目前業界針對AI 輔助開發已經從單純的程式碼補齊邁入代理自主程式碼撰寫(Agentic Coding)的工作流成。然而,隨著企業越來越依賴如 Claude Code 等強大的雲端 AI 代理,對於原始碼外洩與供應商鎖定(Vendor Lock-in)的資安焦慮也隨之提升,特別是日前 Anthropic 官方防堵漏洞,宣布封鎖 OpenClaw 與其他第三方工具透過訂閱制 Claude Pro/Max 帳號取得 AI 算力吃到飽的途徑,全面強制改為以 API 使用量計價後,更多開發者重新重視地端的 AI 算力需求,雲端較便宜的模型也被拿來評估。
在這樣的背景下,GitHub 上我們之前報導過的 OpenCode 開源專案正以黑馬之姿狂攬超過 15.1 萬顆星(151k stars),成為全球開發者社群熱烈追捧的新星。CyberQ 解析 OpenCode 現況,並實作如何結合 NVIDIA DGX Spark 與 QNAP NAS,在企業內部打造一套斷網仍可繼續運作、效能堪用的私有化 AI 開發大腦。
從算力吃到飽到自建地端算力的必然趨勢
過去許多開發團隊高度依賴每月固定費用的雲端訂閱方案,搭配開源 Agent 進行無限制的程式碼重構。但在官方強制轉向 API 計價後,若要維持同等強度的 Agentic Coding,由於 AI 代理在分析程式碼時極度消耗上下文視窗(Context Window),企業每月的 API 帳單動輒飆升至數千美元。
這場震撼教育讓企業深刻意識到,過度依賴雲端 SaaS 服務存在極大的成本不可控風險,促使 AI 算力買斷、長期攤提的地端私有化架構重回主流視野。
為什麼 OpenCode 好用?
anomalyco/opencode 被開發者社群譽為開源版的 Claude Code,由一群熱愛 Neovim 的終端機極客與 terminal.shop 的創作者聯手打造。它之所以能在短時間內稱霸 GitHub 趨勢榜,在於它能處理現代開發者的問題。
100% 開源與模型解耦(Provider-Agnostic)
OpenCode 拒絕綁死單一廠商。它內建的 Provider 抽象層不僅支援 Claude、OpenAI,更能無縫相容於本地端部署的開源大模型(如 DeepSeek-Coder 或 Qwen3、GPT-OSS、Google Gemma4)。隨著開源模型能力接近閉源 AI 大廠,將模型選擇權交給開發者應該仍是未來的重要趨勢。
極致的 TUI 與雙重代理(Plan & Build)模式
OpenCode 提供不錯的終端機介面(TUI),並內建兩種核心 Agent:
plan 模式是唯讀狀態,適合讓 AI 快速探索陌生 Codebase、進行架構分析,預設禁止修改檔案。
build 模式則擁有完整權限,能全權編寫程式碼、安裝套件甚至執行 Bash 腳本(可設定高風險指令需人工審核)。開發者只需按下 tab 鍵就能在兩者間無縫切換。
主客從架構(Client/Server Architecture)
OpenCode 支援 C/S 架構,可以將繁重的 Agent 邏輯執行在後端強大的伺服器上,而開發者只需透過筆電的終端機或 Desktop App 輕量連線遙控。
算力與後勤的黃金組合 DGX Spark x QNAP NAS
要在地端流暢執行千億參數級別的大模型來驅動 OpenCode,硬體架構是成敗關鍵。我們採用了當前較熱門的地端側優秀配置:

NVIDIA DGX Spark 128GB 統一記憶體,解放超長上下文窗口 (Context Window)
這台體積僅如 Mac mini、被科技圈暱稱為小金盒的 AI 超級電腦,搭載了 Grace Blackwell (GB10) 超級晶片,具備 1 PFLOP 的 FP4 算力。要讓 OpenCode 的 AI 代理發揮最大價值,往往需要將數十個關聯檔案、架構文件甚至整個專案的 Codebase 餵給大模型作為背景知識。
DGX Spark 搭載的 Grace Blackwell 晶片高達 128GB 的統一記憶體,不僅能輕鬆裝下千億參數的量化模型,更能保留龐大的記憶體空間來支撐 128K 甚至 256K 的超長上下文窗口。在處理複雜專案時,不僅推論延遲極低,更徹底消除了傳統 24GB 顯示卡在塞入長文本時常見的 OOM(記憶體溢出)崩潰噩夢。
如果要載入更大的模型,除了載入量化模型省記憶體空間外,還可以用高速 DAC 線疊加為二台或四台,彼此連線組成 Cluster ,這樣可以獲得更大的統一記憶體容量,載入夠大的模型來執行輔助程式開發的 AI 代理人工作。
知識庫與儲存中樞 QNAP NAS
DGX Spark 雖具備頂尖算力與 1TB/ 4TB NVMe SSD,但面對企業級大量文件、歷史程式碼、CI/CD 產物,以及動輒數百 GB 的多種 LLM 模型權重(GGUF / Safetensors),仍需要強大的後勤支援。透過至少採用 10GbE 高速網路將 QNAP NAS 作為資料湖,不僅能大幅擴充儲存池,更能利用 QNAP NAS 上的不可變快照(Immutable Snapshots)技術,防止 AI Agent 在某些模式下改壞核心程式碼,提供秒級災難復原。還可以升級 100GbE 更高速網路卡,提供更快的傳輸效率與復原速度。
CyberQ 的測試環境使用 100GbE 高速網路交換器 QNAP QSW-M7308R-4X、NAS 上安裝 100GbE 雙埠網路卡 QXG-100G2SF-BCM,電腦上則是安裝 Realtek 10GbE RTL8127 網路卡,負責運行企業內部 CI/CD 與測試環境的 PVE 伺服器則安裝了 100GbE 單埠網路卡 Mellanox MCX455A 100G (ConnectX-4),NVIDIA DGX Spark 則透過它的 ConnectX-7 互聯與連接到 QSW-M7308R-4X 交換器上。
不可變快照 (Immutable Snapshots):防範 AI 暴走的終極防線
再來一個考量點是,當我們放手讓 AI Agent 在 build 模式下擁有完整權限自主修改檔案、執行 Bash 腳本,伴隨著覆寫核心邏輯或引發系統崩潰的風險。除了 OpenCode 內建的強制人工審核機制外,將企業 Codebase 集中存放在 QNAP NAS 的最大優勢,在於能啟用不可變快照防護。
當 AI 代理發生幻覺(Hallucination)改壞專案時,開發團隊不需手忙腳亂地排查退版,只要依賴 NAS 介面即可秒級還原(Rollback)到 AI 執行前的狀態。這種大膽放權、安全兜底的零信任開發沙盒,是純本機單機開發完全無法企及的資安保障。
企業級地端部署 OpenCode 實作
CyberQ 已經將這套算力與儲存分離的 Agentic Coding 架構落地,部署在客戶端與實驗室中。
Step 1: 網路與儲存基礎建設(QNAP NAS)
建立專屬空間:在 QNAP NAS 系統中建立 AI_Models(大模型權重檔)與 Enterprise_Codebase(企業原始碼)共用資料夾。
NFS 高速掛載:在 DGX Spark 的 DGX OS (Ubuntu) 終端機內,將 NAS 空間掛載為本地端目錄:
sudo mkdir -p /mnt/qnap/models /mnt/qnap/workspace
sudo mount -t nfs -o vers=4 :/AI_Models /mnt/qnap/models
sudo mount -t nfs -o vers=4 :/Enterprise_Codebase /mnt/qnap/workspace
CyberQ 實務建議,在 NAS 網卡端啟用 Jumbo Frame (MTU 9000),最大化 DGX Spark 讀取龐大模型時的 I/O 吞吐量。
Step 2: 在 DGX Spark 啟動本地推論服務
利用 NVIDIA 官方為 DGX Spark 最佳化的 vLLM 容器,直接加載存放在 NAS 上的開源程式碼大模型(例如 DeepSeek-Coder-V3 或 Qwen3),並對外提供與 OpenAI 相容的 API。
在 DGX Spark 上啟動 vLLM 服務的範例,實際使用的 tag 與模型名稱請參考最新的資訊,自由搭配修改。
docker run -d –runtime nvidia –gpus all \
–ipc=host \
–restart unless-stopped \
-v /mnt/qnap/models:/models -p 8000:8000 \
nvcr.io/nvidia/vllm:26.03-py3 \
vllm serve /models/你存在NAS中的地端模型名稱 \
–host 0.0.0.0 –port 8000 \
–trust-remote-code \
–max-model-len 32768 \
–gpu-memory-utilization 0.7 \ (設定記憶體消耗用的比例,避免記憶體都被模型吃掉)
–enable-auto-tool-choice \
–tool-call-parser deepseek_v3 (此為範例,如果更換為其他系列模型,請記得將 –tool-call-parser 替換為對應的參數。)
Step 3: 安裝與設定 OpenCode
在我們的開發工作站(或直接在 DGX Spark 上)安裝 OpenCode。官方建議透過 Homebrew 或官方腳本安裝以保持最新版本,也提供桌面版程式下載安裝使用:
curl -fsSL https://opencode.ai/install | bash
接著,編輯 OpenCode 的全域設定檔(~/.config/opencode/opencode.jsonc),將模型 Provider 從預設的雲端,指向同一區網內的 DGX Spark。
{
“provider”: “@ai-sdk/openai”,
“models”: {
“default”: “DeepSeek-Coder-V3”
},
“openai”: {
“baseURL”: “http://:8000/v1”,
“apiKey”: “local-dummy-key”
},
“permissions”: {
“allowBash”: true,
“requireApproval”: true // 資安重點:高風險 Bash 指令強迫人工審核
}
}
Step 4: 召喚我們的專屬數位工程師
進入由 QNAP NAS 掛載的專案目錄 /mnt/qnap/workspace/my-project,在終端機輸入 opencode 即可進入介面。
我們可以先在 plan 模式下發號施令:
請幫我分析目前目錄下的微服務架構,並規劃一套 Redis 快取機制,但先不要修改任何檔案。
當 DGX Spark 的 AI 算力逐步完成分析並給出計畫後,按下 tab 鍵切換至 build 模式:
計畫看起來很棒,請直接幫我實作、撰寫單元測試,並執行 npm run test!
這時,我們將親眼目睹 OpenCode 像一位資深工程師一樣,自主創建檔案、重構邏輯並執行除錯。所有的原始碼修改都安全地保存在 QNAP NAS 中,所有的 AI 思考都在本地 DGX Spark 完成,整個過程的資料流完全鎖死在企業內網。
跑本機小模型和使用免費雲端模型額度
如果企業沒有採購額外 AI 工作站的預算,但還是有本地的程式開發需求,有一個可以省成本的方式是在有 NVIDIA RTX 顯示卡的機器上安裝 OpenCode,這會比買 64GB / 128GB 記憶體的 Mac 要便宜些。
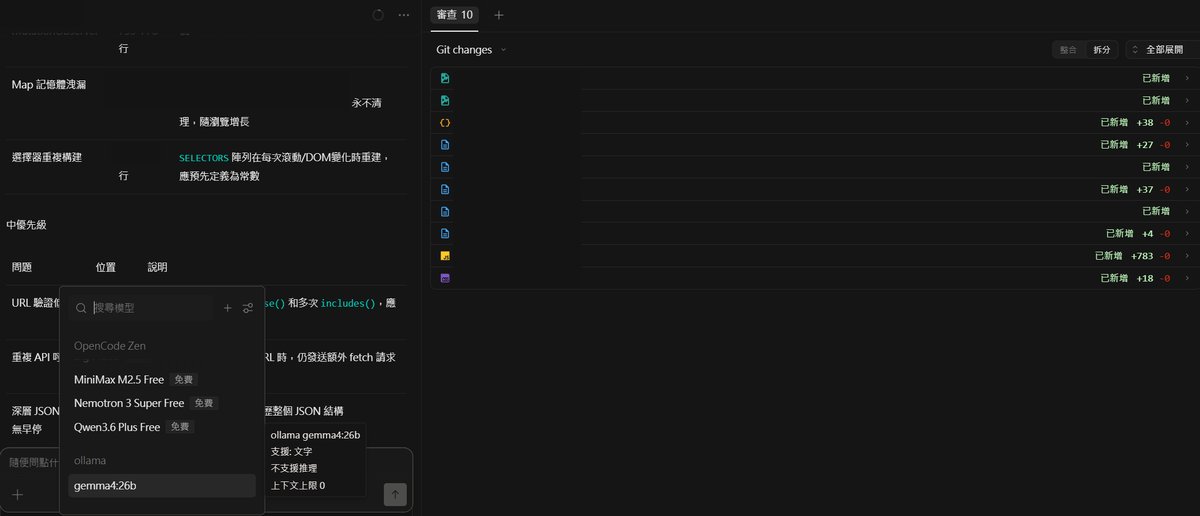
以 Windows 版本的 OpenCode 來說,同樣能夠指定跑在本機的 AI 模型平台,如 Ollama,就可以指定跑 Qwen、Gemma4 之類的模型來進行程式開發的 AI 輔助工作,找到能夠跑的模型,進行簡單的除錯與最佳化程式碼等等的協助。
然後 OpenCode 也支援 OpenCode Zen BigPickle、GPT-5 Nano、MiniMax M2.5 Free、Nemotron 3 Super Free、Qwen 3.6 Plus Free 等雲端模型的免費版,也可以加減用用看省一點 token 的成本,但有時候這些免費模型會報錯無法正確輸出,使用時要留意。
前面我們有提到 OpenCode 有兩種主要模式,記得可使用 Tab 鍵來進行切換,分別是唯讀的計畫模式 (Plan Mode),不會對程式碼進行更改,但是可以分析並研究我們手上給他看的程式碼庫。以及預設的構建模式 (Build Mode),具備程式碼的完整權限,可以讀取、寫入和修改檔案 執行程式碼變更,是我們實際進行開發工作所需要的。
雲地整合可省 token 數與降低整體營運成本
CyberQ 認為,在高度重視資料主權的時代,anomalyco/opencode 結合 NVIDIA DGX Spark 的端側邊緣算力,以及 QNAP NAS 的高速容量與快照保護,無疑是企業實踐安全、高效能 AI 自主開發的可負擔優秀架構之一。
擺脫傳統 IDE 插件與雲端 API 的束縛,奪回對程式碼與大模型的控制權,現在就用 OpenCode 啟動的本地 AI 開發,減少被雲端 AI 服務綑綁的時間和成本吧。即便是地端 AI 和雲端 AI 混用,日常作業也很能夠省 token 數和成本,真的有關鍵任務非使用到雲端超大模型來完成時,再付費使用雲端的 AI API ,反正以量計價。