近來 Redis 作者 Salvatore Sanfilippo,也就是 antirez,開源了 ds4 專案,讓地端 AI 推論社群再次出現一個值得注意的新方向。ds4 全名為 DrawfStar 4,是一個專門為 DeepSeek V4 Flash 設計的原生推論引擎。它不是通用 GGUF runner,也不是 Ollama 或 llama.cpp 的外層包裝,而是針對 DeepSeek V4 Flash 的模型載入、Prompt rendering、工具呼叫、KV 狀態管理與 API server 重新設計的專用引擎。目前支援 Metal、NVIDIA CUDA,CyberQ 發現,這個專案還針對 DGX Spark 有額外照顧,至於給 AMD GPU 平台用的 ROCm 則維持在獨立分支中。
CyberQ 提醒,這個專案目前仍屬於 alpha 品質,作者自己也說推論與模型服務是複雜工程,還需要時間成熟。不過,對於手上已經有 QNAP NAS、128GB Mac 或 NVIDIA DGX Spark GB10、本機 NVIDIA RTX 工作站的人來說,這正好可以設計成一套「本地模型倉庫加推論節點」的實驗架構,QNAP NAS 負責集中儲存模型、資料集、測試語料與產出紀錄,128GB Mac 或 DGX Spark 負責執行 ds4、Ollama、vLLM 或 SGLang,本機電腦則作為開發、測試、代理工具與較小模型推論的入口。
ds4 是不是只有128gb mac 或 dgx spark gb10 能夠跑?
CyberQ 和友商實測,記憶體更低的 Mac 也能跑(96GB),96GB 記憶體的多核心 Mac(如 96GB 的 M 系列 Max 晶片)在加載 Q2 非對稱量化版本時,同樣可以成功執行。ds4 採用了特殊的磁碟緩存技術(將高速 NVMe SSD 作為 KV Cache 的擴展交換空間),有降低了執行 1M 超長上下文所需的物理記憶體門檻。
更高規格的設備可以跑更好品質的模型(256GB / 512GB),可以跑效果更好的 DS4 Q4 版本,如果想執行 Q4 模型,128GB 記憶體是不夠的,需要 256GB 記憶體以上的機器,或者在 512GB 記憶體的 Mac Studio M3/M4 Ultra 上執行才能獲得更好的工具調用(Tool Calling)與推理準確度。這點因為 NVIDIA GB10 可以雙台或四台堆疊成 Cluster,是可以這樣跑的。

除了內建 128GB 統一記憶體的蘋果晶片與 ARM 架構的 NVIDIA GB10 之外,傳統的 PC 玩家也有解決方案,透過多卡/單卡推理,社群(如 vLLM、SGLang)已透過 GPT-5.5 輔助迅速寫出適用於通用 NVIDIA 顯卡的 Custom Kernels 。多卡串聯或單卡也可讓擁有高頻寬 GDDR7 的 RTX 5090 (32GB),或利用多張 RTX 3090 / 4090 (24GB) 透過本地推理解析,在縮減上下文(Context Window)長度的前提下,也能跑出不錯的 Token 生成速度。
ds4 誕生時的最佳甜點硬體確實是 128GB Mac 與 DGX Spark,但實質上 96GB 的 Mac 到 512GB 的高階工作站,以及 PC 多顯卡/單卡環境(配合其他推理框架),都能以不同程度的量化和上下文長度跑起這個模型。
為什麼這套架構適合 QNAP NAS 搭配 DGX Spark?
QNAP NAS 機器的定位本來就適合作為高速共享儲存與虛擬化資料平台,CyberQ 辦公室使用的 TS-855X 採用 Intel Atom C5125 八核心處理器,具備 6 個 3.5 吋硬碟槽與 2 個 2.5 吋 SSD 槽,記憶體最高可擴充至 128GB,並內建 10GbE 與 2.5GbE 網路。對 AI 實驗來說,它不一定是最好的推論節點,但很適合作為模型檔案、GGUF 權重、測試資料、RAG 文件庫與備份快照的集中存放點。
QNAP 的 NFS 服務則可以讓 Linux 主機、NVIDIA 工作站、Mac筆電或桌機透過網路直接掛載 NAS 上的共享資料夾,並可在共用資料夾權限中設定 NFS host access,DGX Spark、PVE 節點、Linux 工作站甚至 Windows 系統上的 WSL2 環境,都可以把 NAS 上的 AI 模型目錄掛載成統一的模型倉庫。
DGX Spark 這類節點則適合負責真正的模型推論,採用 Grace Blackwell 架構,具備 20 核 Arm CPU、128GB unified system memory、10GbE 與 ConnectX-7 100GbE/200GbE 等連線能力。這類 128GB 統一記憶體設備,正好符合 ds4 對 DeepSeek V4 Flash 低位元量化模型的主要使用場景。
這套環境可以分成三層。
第一層是 QNAP TS-855X,扮演 AI Model Depot。建議建立一個專用共享資料夾,例如 AIModels,底下再分成 ds4、ollama、vllm、datasets、rag-docs、benchmarks 與 outputs。這樣日後不管是 ds4 的 GGUF、Ollama 的模型、vLLM 下載的 Hugging Face 權重,或是公司文件 PDF、技術文件、測試 prompt,都可以集中管理。
第二層是 NVIDIA DGX Spark 或 128GB Mac,擔任主要推論節點。這類機器適合執行 ds4-server、Ollama server、vLLM 或 SGLang。ds4 專門跑 DeepSeek V4 Flash,Ollama 適合快速管理中小型模型與一般本機 API,vLLM 或 SGLang 則適合需要 OpenAI-compatible API、高吞吐或較標準 Hugging Face 模型服務的場景。vLLM 也支援提供 OpenAI-compatible server,SGLang 也以相容 Hugging Face 與 OpenAI API、支援多種硬體平台為主要特性。
第三層是本機 PC 或筆電,也就是具備 NVIDIA RTX 顯示卡的電腦,這類機器比較適合當開發端、代理工具端與中小模型推論端。以 16GB VRAM 來看,它可以跑很多 7B、14B、甚至部分 30B 級別的量化模型,但不建議把它當作 DeepSeek V4 Flash 的 ds4 主力節點。比較實際的做法是,本機跑 IDE、Claude Code、Codex、Hermes、OpenClaw、瀏覽器、RAG 管線與測試腳本,真正的大模型推論請求則導向 DGX Spark。
ds4 與 Ollama 的角色要分清楚
這裡有一個很重要的觀念,ds4 不是 Ollama 模型,也不是把 DeepSeek V4 Flash 加進 Ollama 的簡單方案。ds4 是獨立的模型執行引擎,並且提供自己的 OpenAI/Anthropic 相容 API server,endpoint 包含 /v1/chat/completions、/v1/responses、/v1/completions 與 /v1/messages,因此可以接到 Codex CLI、Claude Code 類工具,或其他支援 OpenAI-compatible endpoint 的代理框架。
Ollama 則適合作為另一條平行路線,它支援 OpenAI compatibility,並可透過相容 Chat Completions 或 Responses API 的方式接入現有工具。不過 Ollama 的 Responses API 目前僅支援 non-stateful flavor,也就是沒有 previous_response_id 或 conversation 狀態延續,若要吃 ds4 的長 context、disk KV cache、DeepSeek V4 Flash 專用 tool calling 與狀態重用設計,仍應直接使用 ds4-server。
實作步驟一 在 QNAP NAS 建立 AIModels NFS 共享資料夾
在 QNAP 上建立共享資料夾,例如,
Public (AIModels)/
├── ds4/
│ ├── gguf/
│ ├── source-cache/
│ └── benchmark/
├── ollama/
├── vllm/
├── datasets/
├── rag-docs/
└── outputs/
接著到 QTS 或 QuTS hero 的控制台啟用 NFS 服務,並針對 Public 或 AIModels 資料夾設定 NFS host access。建議只允許固定 IP,例如 DGX Spark、辦公室電腦或家用機與必要的 VMware/PVE 節點,不要開整段網段的讀寫權限。
DGX Spark 端可以先確認 NAS 匯出的 NFS 路徑。
showmount -e 192.168.2.2

假設 NAS IP 是 192.168.2.2,共享資料夾匯出名稱是 /public 或 /AIModels,可以在 DGX Spark 上掛載。
sudo mkdir -p /mnt/qnap-ai
sudo mount -t nfs -o vers=4.1,rsize=1048576,wsize=1048576,hard,noatime \
192.168.2.10:/public /mnt/qnap-ai
如果測試穩定,再寫入 /etc/fstab。
192.168.2.12:/public /mnt/qnap-ai nfs defaults,vers=4.1,rsize=1048576,wsize=1048576,hard,noatime,_netdev 0 0
這裡要注意,NAS 很適合放模型檔案與共享資料,但 ds4 的 KV disk cache 建議放在 DGX Spark 本機 NVMe,除非你有像 CyberQ 配置這種 10GbE 網路、 100GbE 網路的較高速傳輸完環境,就可以放在 NFS 上。
實作步驟二 在 DGX Spark 安裝 antirez/ds4
如果採用 antirez 原版 ds4,可以先在 DGX Spark 本機放 source code 與 KV cache,在 NAS 上放模型檔案備份或模型倉庫。基本流程如下。
sudo apt update
sudo apt install -y git build-essential curl nfs-common
mkdir -p ~/src
cd ~/src
git clone https://github.com/antirez/ds4.git
cd ds4
針對 128GB 記憶體環境,CyberQ 建議下載 q2-imatrix 版本,q4-imatrix 則是給 256GB 以上記憶體級別的機器。ds4 的 download_model.sh q2-imatrix 會從 Hugging Face 下載 DeepSeek V4 Flash GGUF,放到 ./gguf/,並更新 ./ds4flash.gguf 指向選定模型。
如果你希望模型檔案直接放在 QNAP NFS,可以先把 gguf 目錄連到 NAS。
mkdir -p /mnt/qnap-ai/ds4/gguf
cd ~/src/ds4
rm -rf gguf
ln -s /mnt/qnap-ai/ds4/gguf gguf
./download_model.sh q2-imatrix
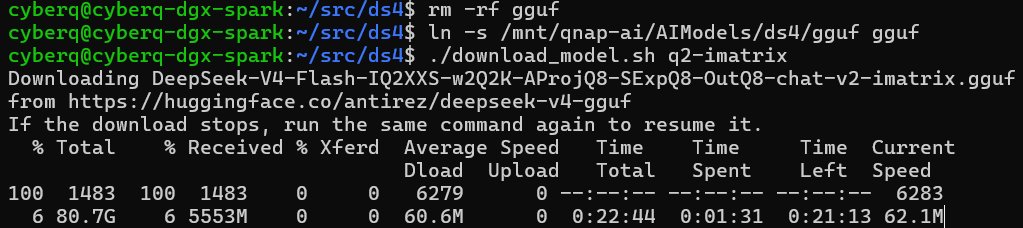
想快速先跑看看效果的話,可以先下載到 DGX Spark 本機 NVMe,完成後再 rsync 回 NAS。
./download_model.sh q2-imatrix
rsync -avP gguf/ /mnt/qnap-ai/ds4/gguf/
接著針對 DGX Spark 編譯 CUDA 版本。
make cuda-spark
CyberQ 建議, make cuda-spark 是 Linux CUDA、DGX Spark/GB10 使用的 build target,一般 CUDA GPU 則是 make cuda-generic,CPU-only 速度很慢先不用。
至於 Mac 就直接下 make 編譯即可,就可以用官方預設的版本了。
啟動 ds4-server 時,CyberQ 建議先用 100k context 起步,KV cache 放本機 NVMe。
mkdir -p /opt/ds4-kv
./ds4-server \
–ctx 100000 \
–kv-disk-dir /opt/ds4-kv \
–kv-disk-space-mb 32768
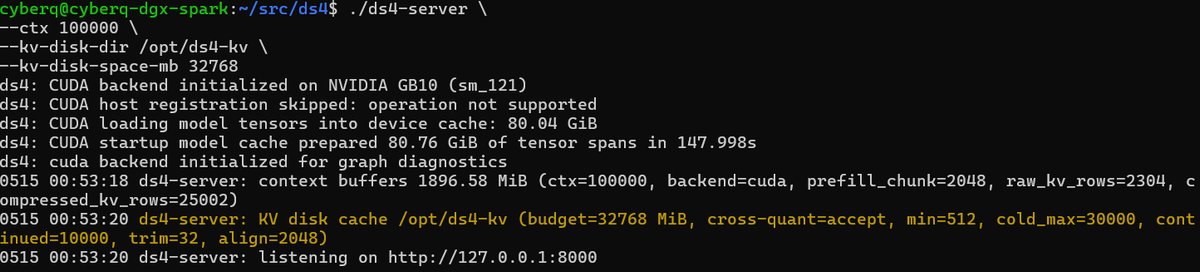
CyberQ 實測可以用 –ctx 100000 搭配 –kv-disk-dir /tmp/ds4-kv 與 –kv-disk-space-mb 8192。對 DGX Spark 或 128GB Mac 來說,如果本機 NVMe 空間足夠,可以把 KV cache 空間拉高到 32GB 或 64GB,方便長工作流反覆重用 prefix。
測試 API
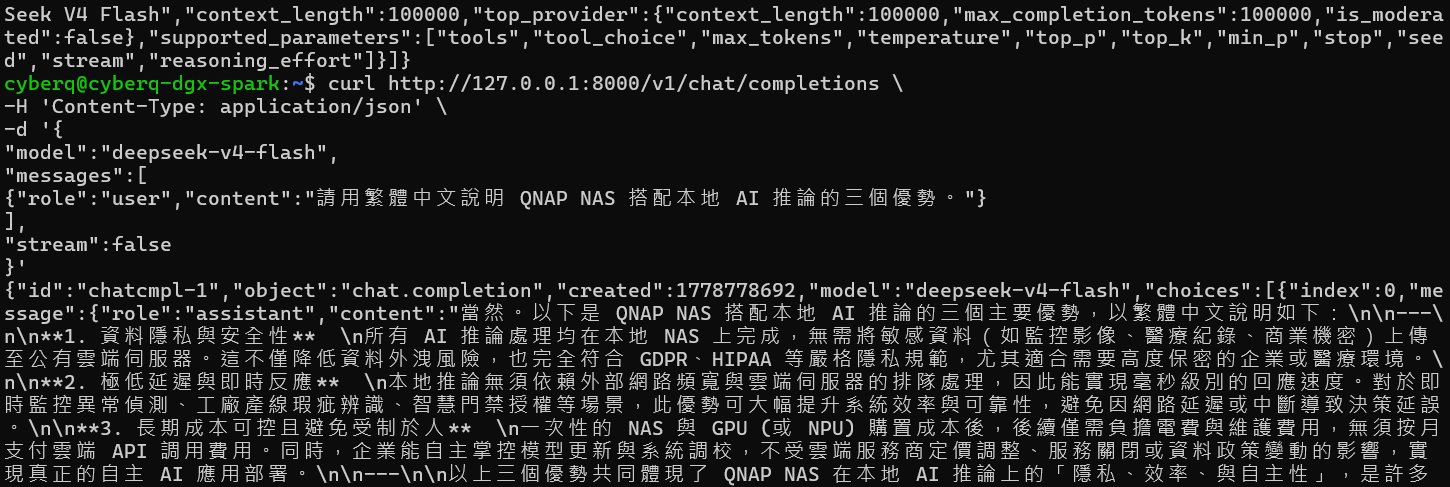
curl http://127.0.0.1:8000/v1/chat/completions \
-H ‘Content-Type: application/json’ \
-d ‘{
“model”:”deepseek-v4-flash”,
“messages”:[
{“role”:”user”,”content”:”請用繁體中文說明 QNAP NAS 搭配本地 AI 推論的三個優勢。”}
],
“stream”:false
}’
實作步驟三 不要直接把 ds4-server 裸露到區網
ds4-server 預設綁在 127.0.0.1 是合理設計。如果要讓本機 PC、Hermes、OpenClaw 或其他工具連到 DGX Spark 上的 ds4-server,不建議直接改成 0.0.0.0 然後裸露在區網。唐鳳的 pi-ds4 指南也特別提醒,ds4-server 預設 bind 127.0.0.1 且不檢查 API key,跨機使用時應優先考慮 Tailscale 或具備驗證的 reverse proxy,而不是直接暴露到 LAN。
最簡單安全的方式是 SSH tunnel。假設 DGX Spark IP 是 192.168.2.131,
ssh -L 8000:127.0.0.1:8000 [email protected]
之後本機電腦上的工具就可以把 base URL 設為
http://127.0.0.1:8000/v1
如果要給多台設備使用,再考慮 Caddy、Nginx reverse proxy、Tailscale Serve、Cloudflare Tunnel 或內部 VPN,並加上 Basic Auth、mTLS 或 IP allowlist。
實作步驟四 Ollama 作為平行推論服務
DGX Spark 上可以同時跑 Ollama,負責較小模型、embedding 模型、快速草稿、一般聊天、摘要與 RAG 前處理。Ollama 的價值在於管理簡單、工具生態多,而且可以用 OpenAI-compatible API 接到許多前端,Ollama 提供 OpenAI API 相容能力,方便既有工具連接本地模型。
概念上可以這樣分工。
ds4-server : DeepSeek V4 Flash、大 context、coding agent、長任務
Ollama : 中小模型、embedding、摘要、快速草稿、一般問答
vLLM/SGLang : Hugging Face 模型服務、高吞吐 API、多人或多工具併發
QNAP NAS : 模型倉庫、資料集、RAG 文件、輸出紀錄、備份
在 DGX Spark 上執行 Ollama 後,客戶端可以用
http://dgx-spark-ip:11434/v1
而 ds4 則維持,
http://127.0.0.1:8000/v1
如果你使用 Hermes Agent,則可以把 ds4、Ollama、Gemini、OpenRouter、Claude 或其他 API 都放進不同 provider,讓工作流依任務切換模型。唐鳳的 pi-ds4 指南也提到,ds4-server 可以作為 Codex CLI、Claude Code、OpenClaw、Hermes Agent 等工具的後端,因為它同時提供 OpenAI Chat Completions、OpenAI Responses 與 Anthropic Messages endpoint。
audreyt/pi-ds4 版本可以怎麼納入?
除了 antirez/ds4 原版之外,唐鳳維護的 audreyt/pi-ds4 也值得觀察。它是基於 Armin Ronacher 的 mitsuhiko/pi-ds4 所做的個人 fork,主要目標是讓使用者可以透過 pi install github.com/audreyt/pi-ds4,把 ds4 與 pi CLI 串起來,形成一個比較完整的本地 AI shell 體驗。該專案 README 提到,它會 clone audreyt/ds4、編譯 ds4-server、下載約 87GB 的 GGUF,並在 127.0.0.1:8000 啟動 OpenAI-compatible API。
這個版本和 redis 大神 antirez 開發的 ds4 原版最大的不同,不只是安裝流程自動化。audreyt/pi-ds4 還加入了 directional steering、可重現 seed、特定 GGUF 下載邏輯,以及針對爭議議題呈現多方觀點的引導設計。文件中也說明,若要關閉 steering,可設定 DS4_DIR_STEERING_FFN=0。
更重要的是,唐鳳的指南已經明確補上 DGX Spark 路徑。文件提到,DGX Spark 等 128GB unified-memory CUDA 機器也可以跑同一份 ds4 engine,在 DGX Spark 上可以直接跑 pi install audreyt/pi-ds4,流程會 clone、編譯、下載 GGUF、啟動 server。若在 Spark 上遇到長 context 或記憶體壓力,手動跑 ds4-server 並把 –ctx 降到 32768 會是比較穩的起點。
因此,若你的目標是「自己掌握每個參數、整合到既有 Hermes、OpenClaw、Claude Code、Codex 工作流」,建議先用 antirez/ds4 原版或 audreyt/ds4 手動部署。若你的目標是「快速體驗 pi CLI + ds4 的整合」,則可以額外測 audreyt/pi-ds4。兩者不衝突,但不要一開始就混在同一個服務目錄裡,避免 GGUF、KV cache、watchdog 與 server 狀態混亂。
效能與實作
CyberQ 以 DGX Spark GB10、q2、7047 tokens prompt 的測試為例,prefill 約 332tokens/s,generation 約 13.5 tokens/s,我們實際上跑了幾次,數字差不多,比其他開發者回報的略低一些,可能是我們的機器上還同時跑有其他開銷,因為實際表現會受 context 長度、KV cache、散熱、CUDA 路徑、模型位置、NFS 或本機 NVMe 讀取影響,以下是我們的實作的架構。
QNAP TS-855X
├─ /AIModels/ds4/gguf 模型檔案備份與共享
├─ /AIModels/datasets 測試語料、RAG 文件
├─ /AIModels/outputs 產出內容與 benchmark 結果
└─ Snapshot / HBS / 權限控管 做資料保護
DGX Spark
├─ ds4-server :8000 DeepSeek V4 Flash 主力服務
├─ /opt/ds4-kv 本機 NVMe KV disk cache
├─ Ollama :11434 中小模型與 embedding
├─ vLLM 或 SGLang Hugging Face 模型服務
└─ NFS mount /mnt/qnap-ai 從 NAS 讀取模型與資料
本機 PC RTX 5060 Ti 16GB
├─ Hermes / OpenClaw / Claude Code / Codex
├─ IDE、瀏覽器、文件處理
├─ Ollama 小模型備援
└─ SSH tunnel / VPN 連到 DGX Spark
這樣的好處是,NAS 不需要硬扛模型推論,避免 Atom CPU 被拖垮,DGX Spark 負責最吃記憶體與 CUDA 的推論工作,本機 PC 則保持互動體驗與開發效率。對實務工作流來說,這比把所有東西塞進單一主機更容易維護,也更符合未來多模型、多 agent、多資料來源的發展。
QNAP NAS 不是推論主角,而是地端 AI 的資料基石
CyberQ 認為,這次 ds4 最有意思的地方,除了讓我們之前很想跑但沒辦法肖想的事,也就是「284B 等級模型可以在本地跑」,還把 long context、disk KV cache、agent tool calling 與 OpenAI/Anthropic 相容 API 放在同一個專用引擎中處理。對重視資料主權、內部文件不出門、程式碼不送雲端的公司或開發團隊來說,這類本地推論架構是有相當的魅力。但是 CyberQ 要提醒,它可沒有雲端大模型 Claude 、OpenAI 的 AI 代理人好用喔,實務上還有很多要調整的地方,效果當然也還不如雲端大模型,但光是本地端模型可以做到比以前笨笨的地端模型要好的效果,已經讓很多公司開發團隊摩拳擦掌,想好好實作一番了。
CyberQ 指出,以 QNAP NAS、128GB Mac / DGX Spark 與 具備NVIDIA RTX 顯卡電腦組成的小型 AI lab,已經可以形成一個很完整的地端 AI 工作流,NAS 負責資料與模型治理,DGX Spark 負責大模型推論,本機電腦負責創作、開發與 agent 操作。接下來大家可以實作的,慢慢把模型跑起來,陸續也把模型、資料、權限、快取、備份、log 與工作流全部整理成一套可維護的內部 AI 基礎設施。
以下是我們在 100GbE 網路環境直接掛載 NFS 給 DGX Spark 執行 DS4 的實作 :