想要跑新熱門的 Google Gemma 4 系列本地端開源模型嗎? 在本地端跑開源 AI 模型,最讓人頭痛的永遠是顯示卡記憶體(VRAM)不夠用。當你想同時開著聊天介面、讓 AI 代理人(Agent)幫你自動處理信件,又想用 ComfyUI 畫幾張圖時,16GB 的 VRAM 往往會瞬間被榨乾、系統直接 OOM(Out of Memory)崩潰。
其實,這不是你的硬體不夠力,而是系統架構可以再最佳化。CyberQ 實際推薦一套目前開源 AI 用戶普遍認為成本 CP 值不錯的 16GB VRAM 日常工作架構。只要懂得將運算與應用徹底分離,至少擁有 16GB VRAM 的 NVIDIA 顯示卡,絕對能發揮出接近企業級小型伺服器的效能,且16GB VRAM 顯示卡可以很容易地讓 gemma4:26b moe 模型載入到 Ollama 中去跑。
想知道 16GB VRAM 適合那些量化模型,可參考我們製作的這個 本地 AI 模型 VRAM 佔用計算機 :
本地 AI 模型 VRAM 佔用計算機 – CyberQ
⚠️ 總需求超過 VRAM 上限!溢出的部分將交由系統 CPU / RAM 運算(Offloading), 推理速度會顯著下降。
優秀分工的四重奏核心架構
這套架構的核心理念只有一個,將算力與應用優雅職能分離,所有的應用程式全部輕量化。它能確保所有的應用端都不會互相打架,乖乖排隊向底層 AI 運算節點去請求 AI 算力。
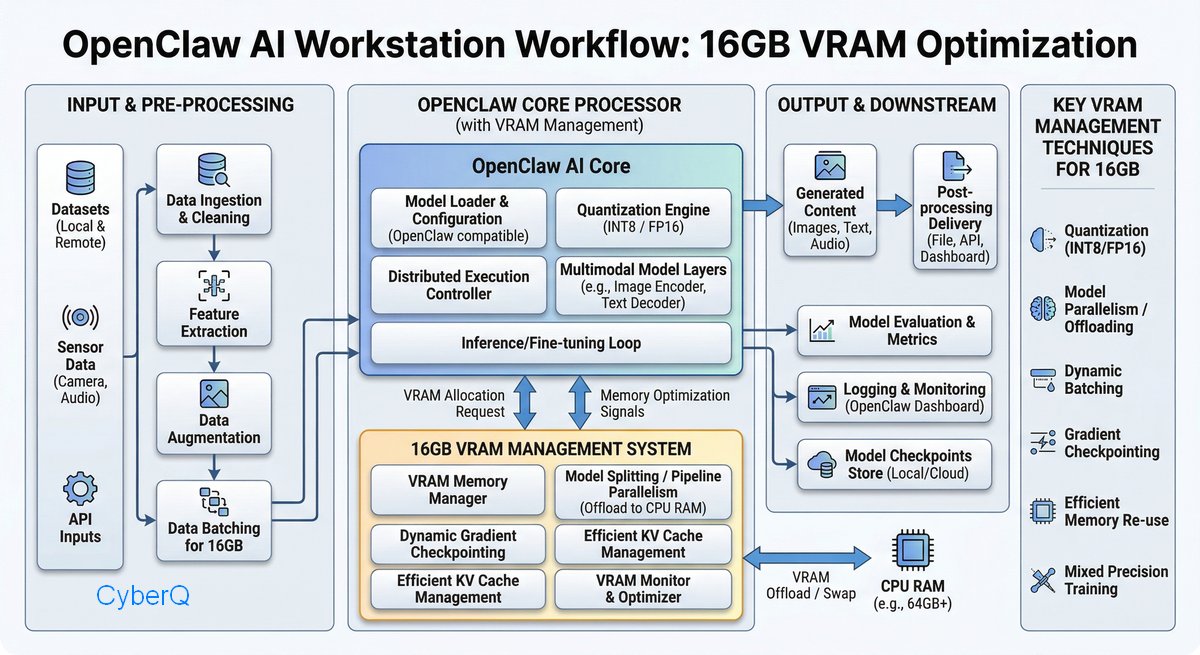
傳統的 AI 配置往往將模型推理(Compute)與使用者界面(UI/App)混在一起,導致一旦應用程式崩潰或需要更新,整個環境都要重啟。CyberQ 採用的架構之一,是將其拆分為兩個層級:
算力層 (Compute Layer – The Engine),運行在宿主機(Windows 或 Linux)上的 Ollama。它直接與 GPU 驅動溝通,負責管理顯示記憶體分配與模型權重加載。
應用層 (Application Layer – The Interface),執行在 Docker 容器中的 Open Web-UI、OpenClaw 龍蝦 AI 代理人或 ComfyUI。它們透過 API 與 AI 算力層通訊,僅負責邏輯處理與視覺呈現。
1、底層大腦 (Windows 本機),Ollama
角色定位,全系統唯一的算力中心。
這種架構的優勢,是將 Ollama 直接安裝在 Windows 本機,讓它獨佔並享有 RTX 5060 Ti 16GB 或其他更多記憶體 NVIDIA 顯示卡的最高硬體存取權。Ollama 最強大的地方在於動態記憶體管理,當你需要在地端寫程式或中小型任務想省雲端 Token 時,它瞬間載入 Gemma 4,需要分析圖片,就切換視覺模型分析內容給我們。當它閒置時會自動釋放顯存,把珍貴的 VRAM 還給系統,不佔用多餘資源。
2、自動化管家 (Docker 容器 A),OpenClaw
角色定位,擁有實作能力和長期記憶的AI Agent(AI 代理人)。
這種 AI 代理人需要比較多的設定,並考量安全性,OpenClaw 有能力幫你整理信件、監控新聞,甚至串接 Telegram 機器人。因為它具備操作檔案的權限,把它關在 Docker 沙盒(Sandbox)裡執行是最安全的做法。這樣能絕對避免 AI 產生幻覺或執行錯誤腳本時,誤刪 Windows 系統的重要檔案。
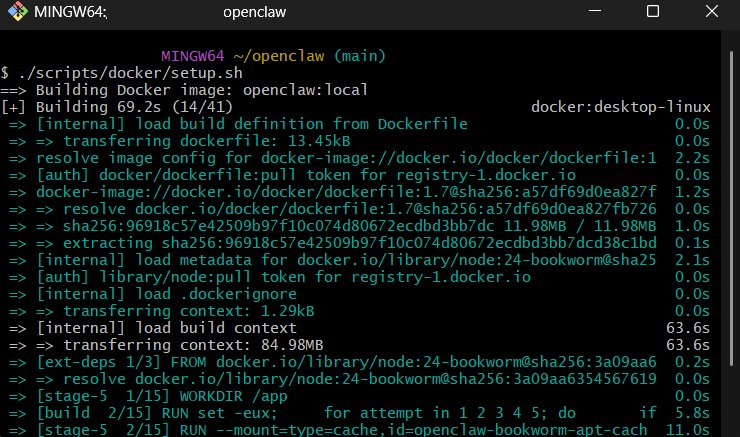
我們將 Open-Webui + Ollma 分別用 Docker 和官方版 .exe 程式安裝跑起來,再透過 git OpenClaw 官方版安裝檔案,執行 docker 腳本,進行 OpenClaw 在本地端 build 進入容器化,就可以在 Docker Desktop 中看到 OpenClaw 有跑起來了。
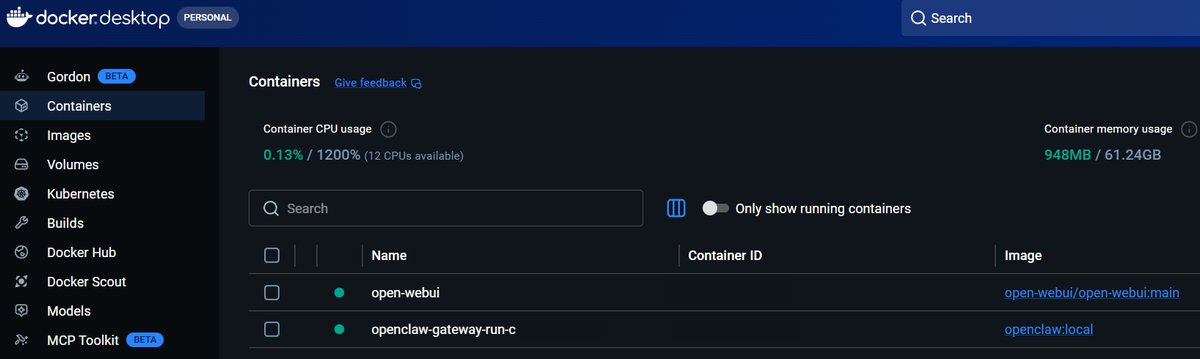
CyberQ 提醒這個的連線秘訣,OpenClaw 容器本身不吃顯卡,它只需要透過 API 位址 http://host.docker.internal:11434 ,就能連去本地端 Docker ,把思考邏輯與推論需求丟給本機的 Ollama 大腦處理。
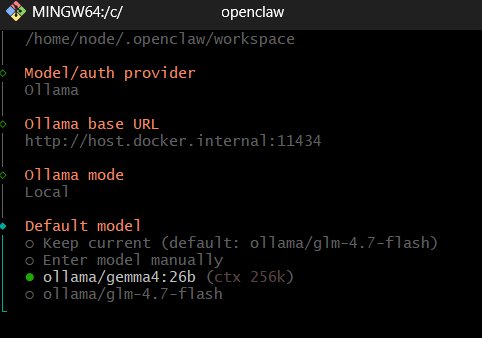
關鍵設定部分,在 Windows 環境下,你必須設置環境變數 OLLable_HOST=0.0.0.0,如果有開 Ollama 的 介面,在設定中開啟讓其他裝置可連線即可,但記得不要把 11434 port 對外,會有資安疑慮,請留在防火牆的内網中。
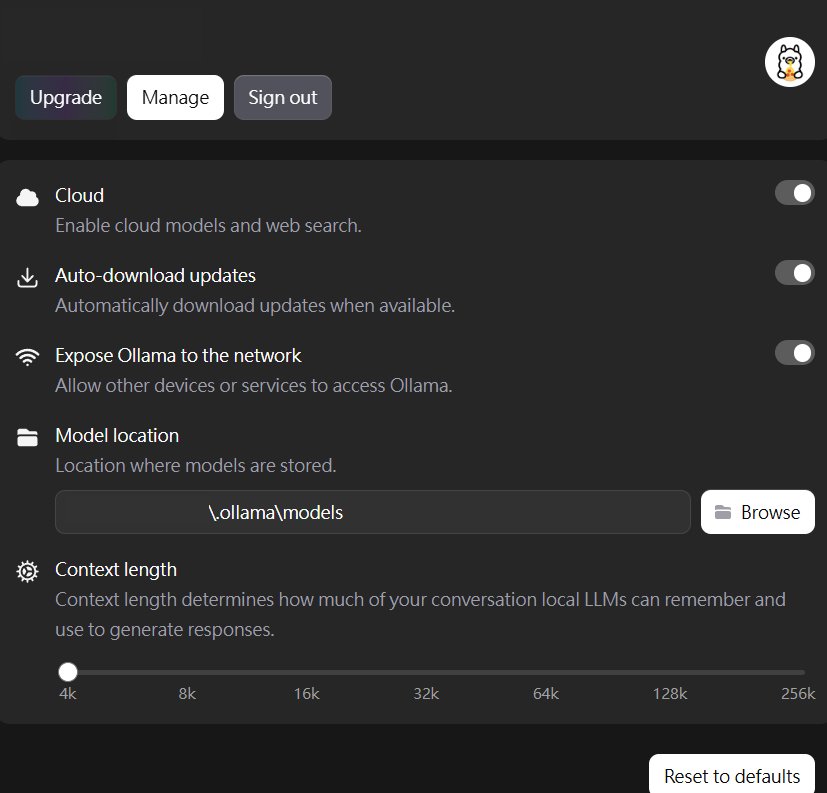
讓 Ollama 監聽網路介面,在 Docker Compose 或 Open WebUI 的設定中,將 API URL 指向 http://host.docker.internal:11434,容器內部的應用程式就能正確利用這個橋樑與宿主機服務溝通。
3、手動聊天室 (Docker 容器 B),Open WebUI
角色定位明確,提供漂亮的 ChatGPT 、Gemini 風格日常對話介面,手機和電腦都能夠連接使用。
CyberQ 建議這是許多新手會踩坑的地方,不要讓 WebUI 佔用 GPU 資源。透過 Docker 安裝時,請務必指定使用 :main 版本(無 CUDA 支援的純 CPU 版本)。它單純只是一個輕量級的網頁入口,負責把你的提問發給 Ollama,保證 0% 的 VRAM 浪費。
4、創意畫布 (Windows 本機),Portable ComfyUI
角色定位是影像生成與創意工作流中心。CyberQ 推薦產圖算影片,都使用這種下載免安裝的 Portable ComfyUI 版本放在本機。畫圖和算影片是最吃顯示卡記憶體的,但透過這套架構,你可以先利用節點呼叫 Ollama 的 API 幫你擴寫提示詞(Prompt),接著趁 Ollama 閒置並釋放顯存的空檔,利用剩下的充沛 VRAM 全力衝刺跑 Z-Image Turbo、Qwen Image 或最新版的 Flux.2 klein 算圖模型。
這種視覺化工作流 (ComfyUI + LLM),文字與圖像無縫交接,利用率達到平衡,我們利用 API 技術,你可以將 LLM 作為 ComfyUI 的大腦。當你輸入一段文字描述,LLM 會自動將其解析為結構化的 Prompt,並驅動 AI 算圖模型進行繪圖,是個不錯的將文本理解與圖像生成深度耦合的起點。
未來個人 AI 落地實作發展趨勢
從這套系統架構中,CyberQ 建議可以思考一下,未來個人 AI 發展的幾個趨勢。
首先是 Agentic AI(代理工作流)普及化,單純的你問我答已經無法滿足人類。未來的 AI 是像 OpenClaw 這樣的數位員工,具備自主規劃能力,並在背景自動完成日常瑣事。
其次是算力與應用解耦 (Decoupling),AI 運算底層會越來越像水電基礎設施(如 Ollama),所有的軟體介面都不再自帶肥大的模型,而是統一向作業系統底層發送 API 請求。
再來是多模態 AI 模型動態無縫切換,未來的硬體與框架必須能在一秒內於文字、視覺、語音模型間動態載入與卸載,這對顯示卡的記憶體頻寬要求將越來越高。
由於近期包括 NVIDIA 的 KVTC、Google 推的 TurboQuant 與開源社群都有推出不錯的記憶體壓縮技術和量化技巧,未來我們要在 16GB 的限制下執行更大的模型,關鍵技術不在於硬扛,而在於 「量化 (Quantization)」 與記憶體壓縮,這部分的發展可以多加留意。
過去為了要在有限的記憶體中跑夠大的模型得用 GGUF 或 EXL2 等量化格式,在新的技術導入後,預期會有更好的發展。CyberQ 假設以 16GB 顯示記憶體的裝置來說,透過精確的量化,讓模型權重與 KV Cache 始終保持在 14GB 左右,為系統預留 2GB 的緩衝空間,防止 OOM。這套邏輯也能依據規格和技術需求的不同,適用更大記憶體的裝置,也包括 NVIDIA DGX 系列大型伺服器與小型 AI 工作站等等。
個人 AI 設備採購指南
看懂了架構,如果你近期打算添購或升級設備,針對不同的預算與情境,以下是 CyberQ 實際跑過並針對客戶實作的四大硬體採購建議,
1、遊戲與 AI 雙棲的高 C/P 值首選,本機電腦 + RTX 5060 Ti 16GB
這就是本文示範的基準平台。NVIDIA 的 CUDA 生態圈依然無可取代。16GB VRAM 剛好跨過了流暢執行現代中型語言模型 + 高階算圖的舒適門檻。而且相對其他 AI 地端算力方案起來,買 NVIDIA RTX 顯示卡的成本相對較低,應用彈性,桌機和伺服器、NAS 都能用。

對於白天寫程式、跑 AI,晚上還要打 3A 大作的玩家來說,這絕對是性價比之王,其他 5070、5080 也是相當好的選項。
2、追求極致能效與大模型,Apple Mac (M5 晶片)
記憶體 (RAM) 到底要買到多少? 這是最多人困惑的問題。Apple 採用的是統一記憶體(Unified Memory),系統 RAM 就是你的 VRAM。且最新的 M5 晶片,在 Ollama 納入蘋果 MLX 框架後,可充分支援並發揮 M5 的效能,實測的資料也顯示不錯。
但是呢,16GB 記憶體,在 2026 年的 AI 需求下,16GB 扣掉 macOS 系統開銷,能分給 AI 的空間大約只剩 8~10GB,只能算勉強入門。
CyberQ 強烈建議 32GB 是起步,64GB 才是最佳解。如果你買了 64GB 記憶體的 M5 Mac,等同於你的 AI 擁有一張將近 50GB VRAM 的顯卡。這讓你能在 Mac 筆電上能執行不錯的中大型模型,這是 Windows 筆電難以匹敵的獨家優勢。
至於熱賣的 Mac Mini 16GB,雖然便宜,但它的地端 AI 算力不行,你跑龍蝦時不會想讓它跑本機的降智小模型,還是會想要用 NVIDIA 顯示卡 或 較高記憶體的 Mac 節點,它們的 AI 算力節點才好用。
以下是 CyberQ 彙整的 Mac 平台若要能夠跑 AI 運算的採購價格比較表,32GB 記憶體是基本低消,64GB 對開發者來說就算是夠用了,128GB 則能夠做更多事情,網路上還有人疊加多台上去跑 MAC 算力叢集的。
| 設備型號 | 32GB (或 36GB) | 64GB (或 72GB) | 128GB |
| Mac mini | ~NT$ 33,900 (M4 / 32GB) | ~NT$ 67,900 (M4 Pro / 64GB) | 不支援 |
| MacBook Air | ~NT$ 49,900 (M5– / 32GB) | 不支援 | 不支援 |
| MacBook Pro | ~NT$ 68,900 (M5 Pro / 32GB) | ~NT$ 102,900 (M5 Max / 64GB) | ~NT$ 172,400 (M5 Max / 128GB) |
| Mac Studio | NT$ 67,900 (M4 Max / 36GB) | ~NT$ 92,400 (M4 Max / 64GB) | ~NT$ 120,400 (M4 Max / 128GB) |
這樣算起來,64GB 是 Mac Mini 的購置成本比較划算。Mac Studio 的 128GB 版本價格已經和 NVIDIA DGX Spark 差不多了。
在 Ollama 正式將 Apple MLX 納入底層支援後,Mac 的硬體潛能被大幅釋放,這直接影響了 AI 工作站的設備評估與採購策略。透過 MLX 框架,CPU 與 GPU 得以在同一塊記憶體池中零拷貝共享資源,徹底消除了資料傳輸的延遲。這讓 M 系列晶片的神經網路加速器能發揮全力,使預填充(Prefill)與解碼(Decode)速度幾乎翻倍。購買 64GB 的 Mac,實質上就等同於獲得一張具備 64GB 超大 VRAM 的 AI 運算卡。
若要執行如 Qwen 35B 或 Gemma 4 系列(27B/26B)的進階開源模型,模型權重載入後本身就會佔據約 20GB 的記憶體。為了保留充裕的 KV Cache 給模型運作,並確保系統與其他應用程式(如 Docker 容器)不會因為動用虛擬記憶體而嚴重降速,32GB 記憶體僅能算是及格。CyberQ 建議,對於需要頻繁呼叫 API、跨對話快取(Reuse Cache)與依賴智慧檢查點的 AI 代理人(如 OpenClaw 或 Claude Code)來說,大量的記憶體能提供更長的上下文保留能力。即使舊的任務分支結束,共用的提示詞前綴也能常駐於記憶體中,大幅提升長文本與自動化程式開發的執行效率,所以買到 64GB 就會是不錯的投資。
3、家庭 / 工作室的私有雲中心,QNAP NAS 搭配 NVIDIA 顯示卡
CyberQ 認為,如果你不想要家中或辦公室每台電腦都插高階顯卡,或者有團隊共用需求,這套方案是比較經濟實惠共用的。在支援 PCIe 的 NAS 中插上 NVIDIA 顯卡,NAS 內建強大的容器化管理,結合 AI 算力後,它就變成了 24 小時在線的私有 AI 伺服器。
團隊成員能隨時隨地連回來調用算力,且商業機密與對話資料完全不出門。
4、頂級研究員與企業小型 AI 工作站 NVIDIA DGX Spark / GB10 128GB
CyberQ 建議,NVIDIA DGX Spark 這是針對 AI 訓練任務為主或 AI 新創團隊的優秀逸品。搭載高達 128GB 大量統一記憶體的微型桌面超級電腦。它不僅能無損執行千億參數的超級大模型,還能輕鬆在本地端進行模型的微調(Fine-tuning)與複雜的多 Agent 平行運算,實現真正的算力自由。
不但如此,還可以按照官方版本建議,實作二台、四台聯接組成的 AI 算力叢集,如此一來 405B、700B 參數的超大模型都有機會駕馭。且同時跑 Ollama、ComfyUI、OpenClaw AI 代理人都沒有壓力。
補充進階玩法,讓小主機擔任 24H 全天候管家
前面的單機環境已經非常強大,但如果你希望 OpenClaw 這個自動化管家能 24 小時不間斷運作(例如半夜幫你收發信件做檢查並自動分類打tag、監控國外新聞或接收 Telegram),讓搭載 RTX 5060 Ti 的主力桌機或 NVIDIA DXG Spark整天開著實在太耗電了。

終極解法是加入一台低功耗的小 NUC 電腦,CyberQ 推薦你可以準備一台搭載 Intel N150、Intel N100 或 AMD Ryzen 3 等級的迷你主機,將上述的 Docker 容器(OpenClaw 與 Open WebUI) 轉移到這台小主機上部署。這類微型電腦整機功耗往往不到 10W – 15W,全天候開機完全不心痛。
日常的輕量監控與邏輯判斷,交給小主機處理,當遇到需要深度思考的複雜任務時,它再透過區域網路(LAN)喚醒主力桌機的 Ollama 請求 AI 大算力支援。
這種小腦管日常、大腦管重運算的雙機流,解決了高階顯卡待機耗電的問題,是進階 AI 地端用戶一個不錯,兼顧成本與效能的極客設定方式。
CyberQ 觀點
儘管硬體的極限決定了算力的上限,但 CyberQ 認為,優雅的系統架構決定了你日常體驗的下限。與其無腦升級硬體,不如先學會如何分配資源。透過量化技術、容器化通訊、掌握 Agent 的協作邏輯,你將不再只是 AI 的使用者,而是 AI 系統的架構師。
在本機和環境中開發好的程式,再丟去邊緣裝置跑地端小模型作辨識和其他專案,在物流、機器人、航太、資療與工業製造環境中都很實用,試著多發揮 AI 工作流環境中的優點,找到適合自己的操作方式。
現在趁著週末,把這套 Ollama + Docker 的分離式架構裝起來,解放你的 16GB VRAM,或善用資源,搭配其他你能夠取得或採購到的 AI 用硬體,開始搭建你的第一個解耦 AI 實驗室,迎接專屬於你的全自動化 AI 時代吧!