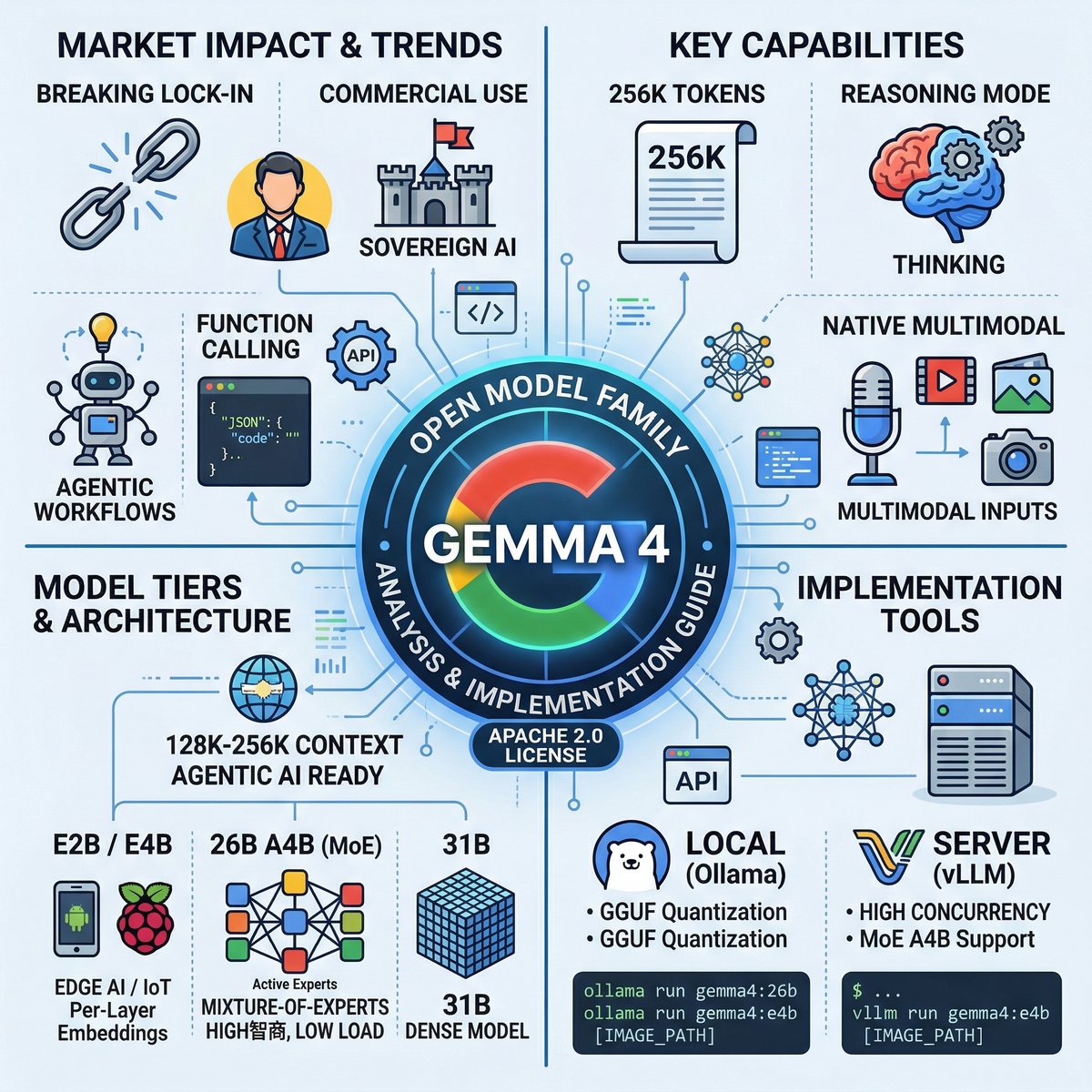
就在開源 AI 社群還在熱烈討論各種大語言模型的發展時,Google DeepMind 正式推出了新一代開放模型家族 Gemma 4。這次的升級可說是誠意滿滿,不僅將上下文長度一舉推升到 25.6 萬(256K)個 Token,更將思考模式(Reasoning)、原生多模態(Multimodal)能力全面下放至全系列模型,並改採友善的 Apache 2.0 授權。
CyberQ 實測 Gemma 4 ,也教你如何在本地端(Ollama)與伺服器端(vLLM)快速部署實作。
重塑邊緣運算與開源商業生態的市場趨勢
CyberQ 認為,Gemma 4 的問世,可說是能處理目前 AI 市場的幾個核心問題,並預示了未來的發展趨勢。
全面擁抱 Apache 2.0,打破生態系鎖定
有別於過去的 Gemma 版本受限於 Google 的特定使用條款,Gemma 4 這次霸氣切換為對商業極度友善的 Apache 2.0 授權。這意味著企業與開發者可以自由地將其整合進商業產品中,無需擔心後續的版稅或合規風險,為主權 AI(Sovereign AI)與資料在地化提供了最堅實的底座。
邊緣 AI (Edge AI) 的全模態革命
Gemma 4 提供了四款尺寸:E2B(Effective 2B)、E4B(Effective 4B)、26B A4B(MoE 架構)與 31B(Dense 架構)。其中針對行動裝置與物聯網(IoT)設計的 E2B 與 E4B 模型,透過層間嵌入(Per-Layer Embeddings)等技術讓體積變得極小,不但能在本地高效率執行,更原生支援音訊與影片的輸入處理。這將推動真正離線、高隱私的端側 AI 助理普及化,未來的智慧型手機或樹莓派本身即是可用的 AI 載體。
推動 Agentic(自主代理)工作流的標準化
Gemma 4 這次導入了原生的 System Prompt 支援與精準的執行函式呼叫(Function-calling)執行能力。這讓其成為企業構建自動化工作流的引擎,開發者能在本地端穩定輸出 JSON 格式或呼叫外部 API,大幅降低了依賴雲端閉源模型所帶來的Token 稅
Gemma 4 現階段的優缺點
Gemma 4 採用了獨特的混合式注意力機制(交錯使用局部滑動視窗與全域注意力),並結合比例 RoPE (p-RoPE) 技術,達成了效能與記憶體的高效平衡。
優點 (Pros)
夠大的上下文窗口:小型模型(E2B/E4B)具備高達 128K 的上下文,中大型模型(26B/31B)更達到 256K,能輕鬆吞下整本書籍或龐大的專案程式碼,進行跨文件檢索與分析。
| 屬性 | E2B | E4B | 31B Dense |
|---|---|---|---|
| 參數總數 | 23 億個有效權杖 (含嵌入為 51 億個) | 45 億個有效參數 (含嵌入層為 80 億個) | 307 億 |
| 圖層 | 35 | 42 | 60 |
| 滑動視窗 | 512 個權杖 | 512 個權杖 | 1024 個符記 |
| 脈絡長度 | 128,000 個符記 | 128,000 個符記 | 256,000 個權杖 |
| 詞彙大小 | 26.2 萬 | 26.2 萬 | 26.2 萬 |
| 支援的模態 | 文字、圖片、音訊 | 文字、圖片、音訊 | 文字、圖片 |
| 視覺編碼器參數 | 約 1.5 億 | 約 1.5 億 | ~5.5 億 |
| 音訊編碼器參數 | ~3 億 | ~3 億 | 沒有音訊 |
越級的推論與思考能力:全系列皆支援可配置的思考模式(Thinking mode),在面對複雜數學(如 AIME 2026 測試)、程式碼(LiveCodeBench)或邏輯題時,能先在後台進行多步驟深度規劃再作答。
高性價比的 MoE 架構:26B A4B 採用混合專家(MoE)架構,總參數達 252 億,但在推理時僅啟動約 38 億參數(啟動了 8 個專家 + 1 個共享專家),提供了極高的生成速度與低延遲,完美平衡了高智商與硬體負載。
| 屬性 | 26B A4B MoE |
|---|---|
| 參數總數 | 252 億次 |
| 有效參數 | 38 億 |
| 圖層 | 30 |
| 滑動視窗 | 1024 個符記 |
| 脈絡長度 | 256,000 個權杖 |
| 詞彙大小 | 26.2 萬 |
| 專家人數 | 8 個有效 / 128 個總數和 1 個共用 |
| 支援的模態 | 文字、圖片 |
| 視覺編碼器參數 | ~5.5 億 |
無損視覺解析:視覺系統不再將圖片強制壓縮或裁切成正方形,而是根據動態長寬比配給軟 Token(最高支援 1120 個 Token),且導入 2D 空間 RoPE,讓模型天生具備極強的空間與圖表感知力。
缺點與限制 (Cons)
極限上下文的 VRAM 門檻:雖然模型支援 256K 的上下文,但要真正吃滿這麼長的文本,其產生的 KV Cache 會消耗極大的顯示卡記憶體(VRAM)。對於一般消費級顯卡而言,若沒有做好量化或長度限制,極易遭遇記憶體耗盡(OOM)的風險。
MoE 架構的記憶體載入限制:26B A4B 雖然推論速度極快,但在初始化載入時仍需具備容納完整 252 億參數權重的實體記憶體空間,對低階設備的 RAM 仍是一大考驗。
參數天花板限制:Gemma 4 最大版本停留在 31B。若企業場景需要極端廣泛的冷門世界知識儲備,對照其他市場上千億級別(100B+)的開源大模型,31B 在絕對的知識廣度上仍存在物理極限。
CyberQ 實際部署 Gemma 4 模型,發現最多人在意的是 26B 和 31B 的差異,模型基本定位上, Gemma 4:31B 是 稠密(dense)架構、約 30.7 B 參數、256K 上下文窗口,是家族中主打最高品質、深度推理與多任務能力的版本。 Gemma 4:26B A4B 則是採混合專家(MoE, Mixture‑of‑Experts)設計,總參數量 ~25.2 B,但每次推理只有約 3.8 B 活躍參數,同樣支持 256K 上下文窗口,這讓它在計算成本與推理速度上具備優勢。
16GB VRAM 顯示卡可以跑 Gemma 4:26B A4B,但沒辦法跑 Gemma 4:31B,那個要 24GB 顯示卡的硬體會比較好。
開發者社群快速部署與因應
在 Reddit 的 r/LocalLLaMA 與 Hugging Face 等開源 AI 社群中,Gemma 4 的發布引起了爆炸性的討論,甚至有開發者以Google 不經意間丟出了現階段最受矚目的開源權重來形容此次發布:
Day-Zero 的完美生態支援:此次最受開發者讚譽的是各大生態系框架的第零天同步支援。發布首日,Ollama、vLLM、llama.cpp 和 Hugging Face Transformers 就已全面相容,開發體驗順利。
多模態 E2B/E4B 讓創客逐步投入測試開發:能直接將語音或圖片丟給只有在樹莓派、Jetson 甚至手機上執行的本地小模型,並迅速得到回覆,讓許多物聯網與邊緣運算開發者感受不錯。
原生 System Prompt 解決痛點:過去使用 Gemma 系列開發時常因為系統指令不穩定而苦惱。開發者大讚導入原生系統角色後,Gemma 4 對話的語氣控制變得極為精準,非常適合用來打造自定義性格的 AI。
CyberQ 實測發現,在複雜邏輯與長文本檢索上,Gemma 4 31B/26B 展現了超越其體積的 Frontier-level 模型實力,在多語言(140+)支援與原生影音處理上,更是對比現有開源競品(如 Qwen 3.5、DeepSeek 等)拿下了差異化的優勢。
Google 官方表格中標示的評估結果,同樣適用於指令微調模型 :
| Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B (無思考) | |
|---|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| AIME 2026 no tools | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| Tau2 (平均值,以 3 為基準) | 76.9% | 68.2% | 42.2% | 24.5% | 16.2% |
| HLE no tools | 19.5% | 8.7% | – | – | – |
| HLE with search | 26.5% | 17.2% | – | – | – |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 21.9% | 19.3% |
| MMMLU | 88.4% | 86.3% | 76.6% | 67.4% | 70.7% |
| 視覺輔助 | |||||
| MMMU Pro | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% |
| OmniDocBench 1.5 (平均編輯距離,越低越好) | 0.131 | 0.149 | 0.181 | 0.290 | 0.365 |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% | 46.0% |
| MedXPertQA MM | 61.3% | 58.1% | 28.7% | 23.5% | – |
| 音訊 | |||||
| CoVoST | – | – | 35.54 | 33.47 | – |
| FLEURS (越低越好) | – | – | 0.08 | 0.09 | – |
| 長篇脈絡資訊 | |||||
| MRCR v2 8 針 128k (平均) | 66.4% | 44.1% | 25.4% | 19.1% | 13.5% |
如何在 Ollama 與 vLLM 中實作部署 Gemma 4
CyberQ 實際部署,在本地或伺服器端執行 Gemma 4 是很方便的。
方法 1:使用 Ollama 進行本地端輕量化部署 (適合個人電腦 / Mac / 筆電 / NAS)
Ollama 透過 GGUF 量化格式,讓我們能用最少的運算資源跑起 Gemma 4,且原生支援多模態輸入。
1、下載與執行 確認已安裝最新版 Ollama 後,開啟終端機並輸入指令。可以根據硬體資源選擇適合的尺寸:
適合一般輕薄筆電或邊緣設備,原生支援音訊與影像處理,輸入
ollama run gemma4:e2b
適合配備獨立顯卡的 PC 或 Mac M 系列,輸入
ollama run gemma4:e4b
適合具備 16GB VRAM 以上的設備 (26B MoE 架構,速度與智商的最佳平衡),輸入
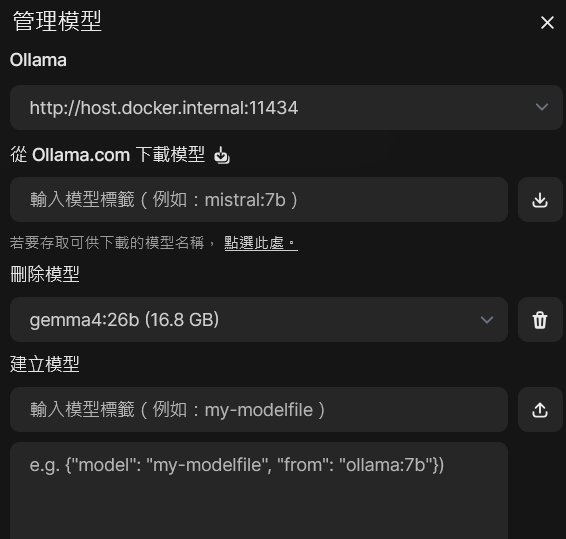
ollama run gemma4:26b
CyberQ 實測 gemma4:26b,這個版本的成績很漂亮(AIME 逼近 31B 旗艦),是優秀的模型。但因為總參數有 26B,經過 4-bit 量化後,大約會吃掉 14GB ~ 15GB 的 VRAM。
CyberQ 測試的 QNAP NAS 有搭載 NVIDIA A2000 顯卡,具備 12GB VRAM,因此也可以在 QNAP 中的 Docker 跑 Ollama 再搭配這個 Gemma4 模型,透過 Open WebUI 也是可以很方便地部署 Gemma4 來跑。
如果你有 18GB 以上 或 24GB 以上 VRAM 的設備
也可以下這個指令跑 31B 的
ollama run gemma4:31b
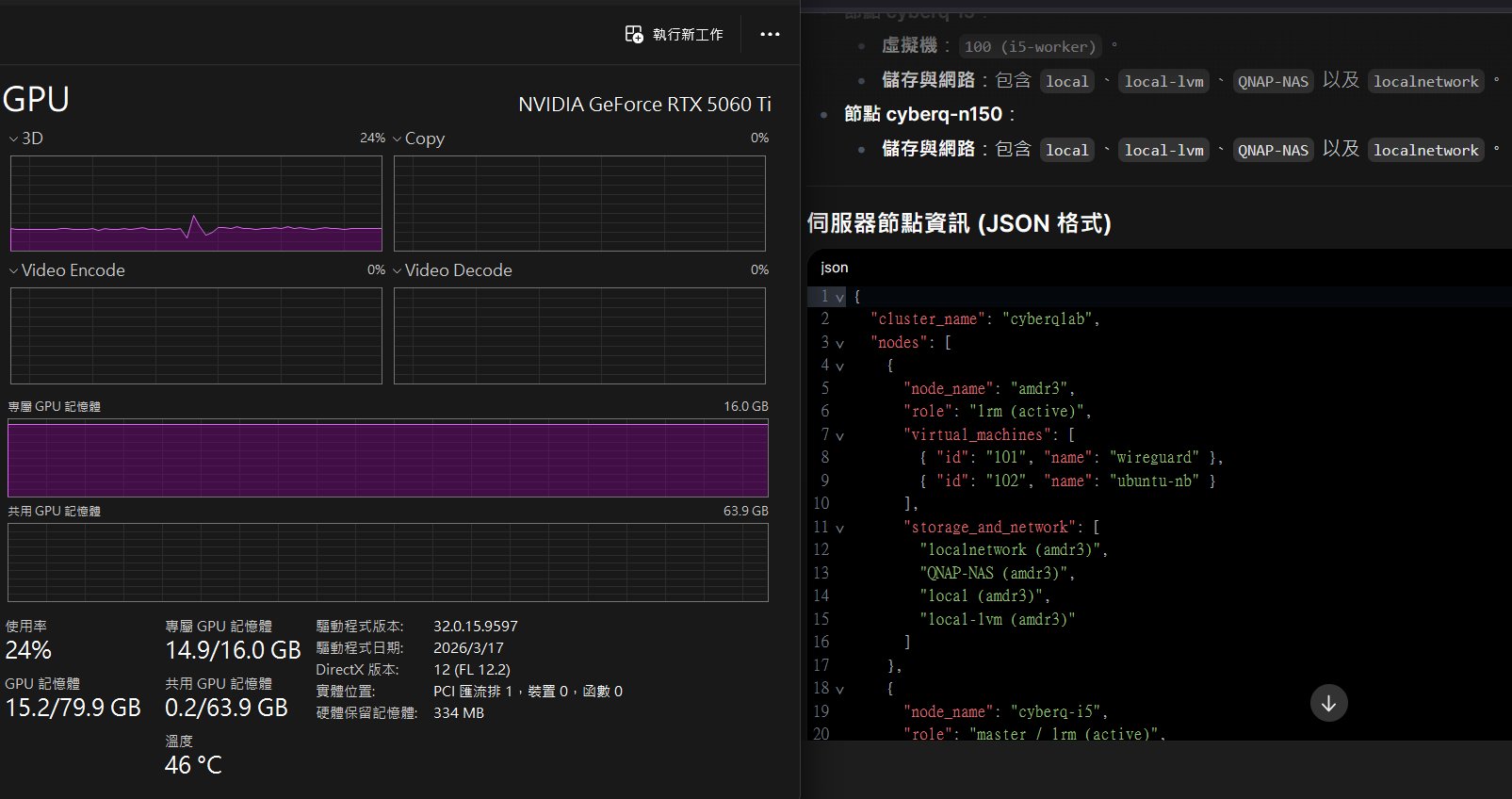
2、多模態圖像指令測試
Gemma 4 支援視覺輸入,可以直接在對話框中附上圖片的本機路徑:
ollama run gemma4:e4b “請詳細描述這張架構圖,並用 JSON 格式輸出其中的伺服器節點 /Users/Name/Desktop/architecture.png”
可以看到 Gemma 4 可以正確辨識圖片的內容,並且針對指令做後續處理和節點資訊用指定的 JSON 格式輸出給我們。
方法 2:使用 vLLM 進行高併發伺服器部署 (適合生產環境)
對於需要高吞吐量與多併發請求的企業級部署,vLLM 是目前的最佳解決方案。它已經原生支援 Gemma 4 的動態視覺解析度與 MoE 架構。
1、安裝或更新 vLLM
pip install -U vllm transformers
2、啟動 OpenAI 相容的 API 伺服器
以下指令以 31B 密集模型為例。CyberQ 建議,為了避免超長文本耗盡伺服器記憶體,請根據你的硬體狀況,使用 –max-model-len 來限制最大 Token 長度。若單卡 VRAM 不足,可使用 –tensor-parallel-size 跨卡分散運算。
vllm serve google/gemma-4-31b-it \
–trust-remote-code \
–max-model-len 32768 \
–tensor-parallel-size 2 \
–port 8000
CyberQ 建議,若追求極致的 TPS (Tokens per second) 推理速度,可將模型替換為 google/gemma-4-26b-a4b-it MoE 版本,能大幅提升企業內部 API 的生成吞吐量。
啟動後,我們就可以使用標準的 OpenAI Python SDK 來呼叫本地端的 Gemma 4,將 base_url 指向 http://localhost:8000/v1,立即將這顆強大的地端模型納入我們的應用專案與工作流中使用。
快來用 Gemma 4 吧
CyberQ 認為,Google Gemma 4 的問世,不僅確立了邊緣多模態 AI 的新標準,更透過 Apache 2.0 授權與強悍的推理模式,將開源模型的實用性拉升到了一個全新層次。
無論我們是想在終端裝置上跑一個智慧語音助手的開發者,還是需要建立極高安全性主權雲的企業,Gemma 4 都絕對是我們專案工具箱中不容錯過的好夥伴喔。