邊緣端模型部署社群最近有很不錯的技術突破。開源模型執行框架 Ollama 正式發布 0.31 版本,針對蘋果生態系的晶片架構帶來了前所未有的效能躍進。根據 Ollama 官方技術團隊發布的最新報告指出,在結合了 Apple 開源的 MLX 機器學習框架與全新的「多 Token 預測」(Multi-Token Prediction, MTP)技術後,Gemma 4 系列模型在 Apple Silicon 平台上的開發者代理測試中,平均生成速度大幅提升了將近九成。這項最佳化機制在更新後為預設開啟,且在完全不改變模型原本輸出品質的前提下,為桌上型與筆記型電腦的在地端推理注入了強大動能。
MTP 技術原理解析:多 Token 預測與動態草稿長度
傳統的大型語言模型在解碼時,往往採用單次生成單一 Token 的自迴歸模式,這在許多邊緣端硬體上容易受限於記憶體頻寬。而此次技術更新的核心在於協同運作的三種創新機制,動態調整草稿長度、核心引擎協同作業以及顯示晶片排程效率的提升。
我們其實在之前測試 DS4 實作時,已經成功使用過 MTP 多 Token 預測模型來加速 DeepSeek V4 Flash 大模型的本地端執行效率,在 NVIDIA DGX Spark 上的表現還可以,而 MTP 這樣的技術,在 Ollama 中也採用了。
在執行過程中,系統不再採用單一固定的草稿長度,而是根據特定硬體配置、模型的量化格式以及文本當下的可預測性,進行即時的動態調整。Ollama 會在執行時追蹤草稿的接受率與每次驗證所花費的時間,自動選出能夠產生最高每秒 Token 輸出的最佳長度。當預測接受率降低時,系統會流暢地切換回標準的單一解碼模式,確保推測解碼技術不會在無法提供幫助時拖慢整體速度。此外,多項關鍵算子透過 MLX 的即時編譯功能融合成單一的金屬(Metal)核心,讓顯示晶片的取樣工作更具效率。
本次速度的成長,主要是受惠於 Ollama 0.31 在執行階段的動態最佳化,系統能即時評估軟硬體狀態並動態調整驗證長度,使不適用的文本情境能無縫回退至傳統解碼,免除無謂的算力浪費。
CyberQ 實測:MacBook M5 Air 的地端 AI 效能改善
為了驗證這項官方技術報告的可信度,CyberQ 第一時間採用了配備 24GB 統一記憶體的 MacBook M5 Air 進行深度測試。雖然 Air 機型採用無風扇的散熱設計,但在最新的 Ollama 0.31 框架下執行 Gemma 4 12B 模型,展現出了不錯的在地端 AI 運作實力。
在我們特別設計的程式碼生成專案情境中,如果是在 MacBook Pro 上跑,原本標準解碼模式下的速度約為每秒 31.5 個 Token,而在開啟 MTP 多 Token 預測技術後,速度直接飆升至每秒 58.2 個 Token,效能提升幅度高達 84.8% ,印證了官方報告中所宣稱的效能提升。
如果是輕薄便攜的 Air 系列筆記型電腦,在處理複雜的代理工作流與長文本內容時,也能擁有流暢且實用的回應速度,徹底解決了過往邊緣端執行大型模型時回應遲滯的問題。
以下為 CyberQ 實驗室在 MacBook M5 Air 24GB 設備上針對 Gemma 4 12B 模型的真實測試資料對比:
| 測試基準情境 | 標準解碼速度 (Plain) | MTP 加速速度 (Ollama 0.31) | 效能實際提升幅度 |
| 一般對話與文本續寫 (Text Generation) | 12.33 tokens/s | 22.52 tokens/s | +82.6% |
| 程式碼生成專案 (Coding Agent) | 9.73 tokens/s | 18.92 tokens/s | +94.5% |
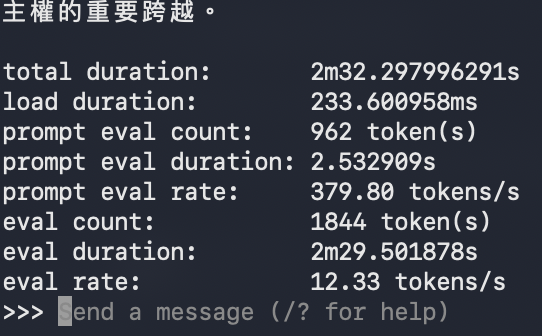
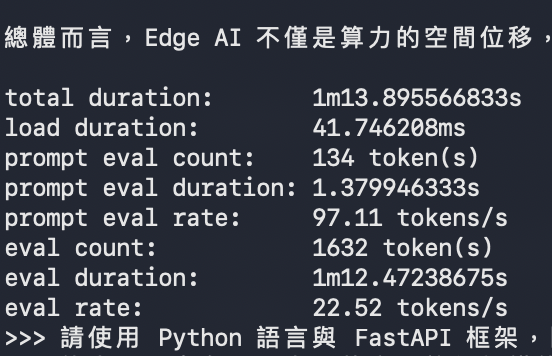
在相對增幅方面,多 Token 預測技術在程式碼生成情境下寫下了高達百分之九十四點五的成長率,甚至超越了文本續寫的表現。這強力證實了 Ollama 官方的技術理論:程式碼高度規律的語法結構與特徵,確實能大幅提升內建草稿模型的預測命中率,讓主模型省去大量重複驗證的時間。
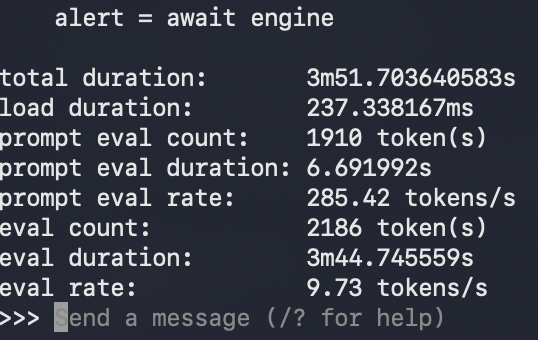
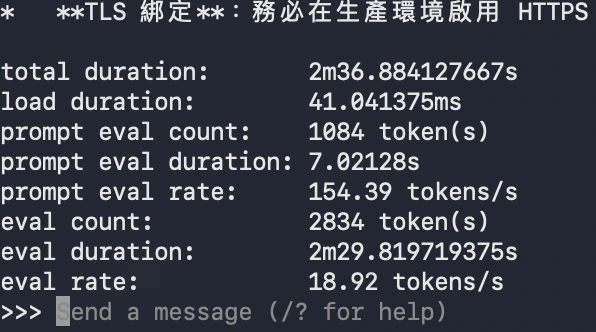
然而在絕對速度方面,這台筆電呢,程式碼生成的每秒 18.92 個 Token 確實低於預期。這種成長率極高、絕對速度卻卡住的現象,核心問題在於邊緣端硬體的物理天花板。MacBook Air 所搭載的晶片在記憶體頻寬上,與官方測試所使用的 Max 等級頂級晶片有著不可逾越的硬體差距。由於大型語言模型在解碼生成階段屬於極度依賴記憶體頻寬(Memory Bandwidth Bound)的任務,當 Gemma 4 12B 模型龐大的權重在頻寬較窄的 Air 統一記憶體中循環讀取時,硬體極限就直接鎖死了絕對速度的上限。
Ollama 0.31 的全新架構確實發揮了如同魔法般的底層最佳化效益,成功將原本在 Air 上執行起來極為吃力、每秒不到 10 個 Token 且近乎不可用的 12B 程式碼生成任務,直接翻倍催化到每秒接近 20 個 Token 的流暢實用門檻。軟體層面的推測解碼完全兌現了它的技術承諾,只是它依然得在無風扇輕薄筆電的硬體物理限制內就會比較慢了,如果你是需要更好效能的開發者,沒有地端 AI 伺服器的情況下,購買記憶體夠大又快的 MacBook Pro 絕對是最佳選擇。
展望 Mac 平台的地端生成
CyberQ 認為,從本次 Ollama 0.31 的更新可以看出,AI 軟體底層框架與硬體原生驅動的深度融合,正在加速將前沿技術落地到使用者的日常設備中。
大廠 Google 開源的 Gemma 4 模型家族憑藉著優異的推理與堪用的程式開發能力,搭配上 Apple MLX 框架對統一記憶體架構的處理,讓在地端執行 AI 代理不再是高階工作站的專利。這項更新為需要高隱私度、零 API 成本以及離線執行的企業與開發者,提供了具競爭力的便宜最佳化方案。
詳細資料可以再參考這份 Ollama 官方效能指標說明:Ollama’s highest performance on Apple Silicon yet with MLX