隨著大型語言模型體積不斷膨脹,AI 計算集群對於儲存系統的吞吐量與延遲要求,是目前業界在公司內建構環境時優先要考量的項目。傳統 1GbE、2.5GbE 甚至 10GbE 網路在面對數十、數百 GB 的模型權重載入與動態快取時,早就已顯得捉襟見肘,目前是邁向 100GbE、400 GbE 的時代。

為了打造更好效能的 AI 基礎設施,CyberQ 實作如何透過 QNAP 高速 NAS 方案,搭配 100GbE 超高速網路與 RDMA 技術,直接為企業用的平價 AI 計算節點 NVIDIA DGX Spark GB10 提供足夠的儲存後盾,解決分散式 AI 部署中的核心儲存問題。本範例中使用到的交換器為 QNAP QSW-M7308R-4X,NAS 是 TS-h1277AFX,加裝了 100GbE 雙埠網路卡 QXG-100G2SF-BCM 一張。
硬體佈署:QNAP QM2-2P-384A 高速固態硬碟擴充卡整合

在硬體佈署方面,CyberQ 本次實戰的重點在於擴充 NAS 的高速快取與儲存池。我們選用了威聯通原廠的 QM2-2P-384A PCIe 擴充卡,這張擴充卡能夠在單一插槽上擴充兩組 M.2 NVMe SSD。從拆解圖中可以看到,我們安裝了兩支 PCIe Gen4 NVMe SSD 固態硬碟,並透過卡上的綠色免螺絲扣具進行穩固鎖定。

為了應對企業級負載,該卡在 M.2 插槽下方設計了專屬的熱敏堆感測器,能精準監控硬碟溫度。外層則覆蓋了極具質感的厚實玫瑰金純銅散熱片與主動式微型風扇,確保高速讀寫時不會因過熱而降速。

這張擴充卡隨後被安置於 QNAP NAS 的主機板 PCIe 擴充槽(如支援 Gen4x4 或 Gen4x8 的插槽)中,本範例的機器是 TS-h1277AFX,可充分釋放 PCIe 頻寬優勢,協助後續的 AI 資料傳輸。

網路架構建構通往 AI 叢集的 100GbE 與 RoCE 高速公路
有了底層高速固態硬碟的加持,接下來便是打通通往 NVIDIA DGX Spark 計算節點的高速公路。CyberQ 在 QNAP 控制台的網路與虛擬交換器設定中,將 100GbE 網卡與系統服務做整合。
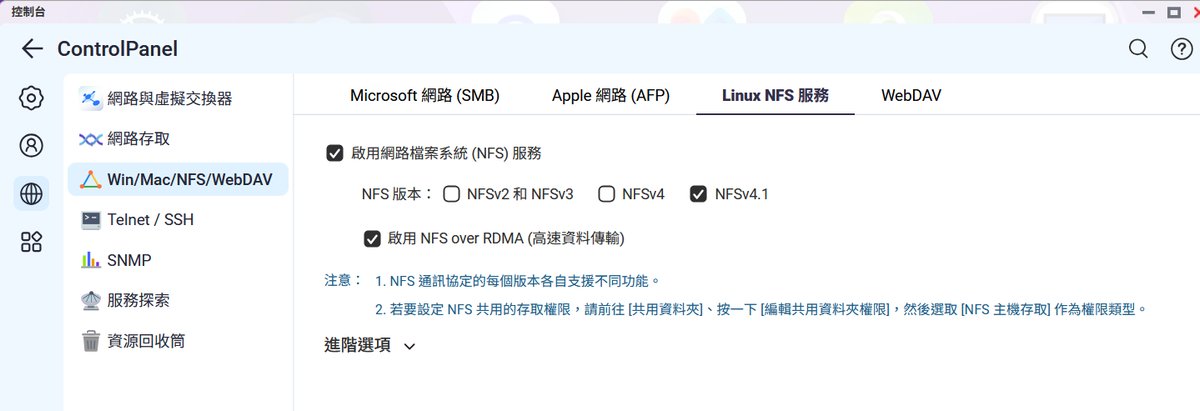
進入系統的控制台介面,在檔案服務的 Linux NFS 服務分頁中,必須勾選啟用網路檔案系統服務,並將版本指定為最新的 NFS v4.1。最為關鍵的步驟是開啟「啟用 NFS over RDMA(高速資料傳輸)」選項。透過遠端直接記憶體存取技術,DGX Spark 節點在讀取 NAS 上的模型資料時,能夠實現較低的延遲與更高的資料吞吐量,這對於多節點平行去讀取模型權重是有幫助的。
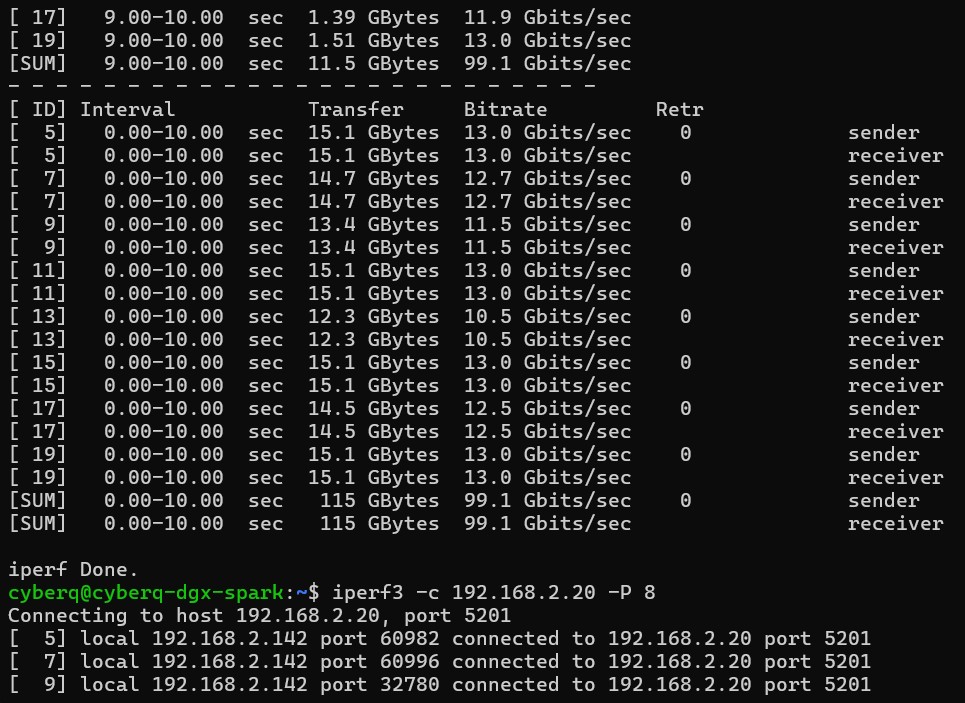
實際測試 iperf3 方面,可以看到 NVIDIA DGX Spark 和 QNAP NAS 兩台機器之間傳輸速率可以開到最高每秒 99.1 Gb,測試中都沒有重傳的錯誤。
NFS 遠端掛載與 ds4-server 推理引擎執行
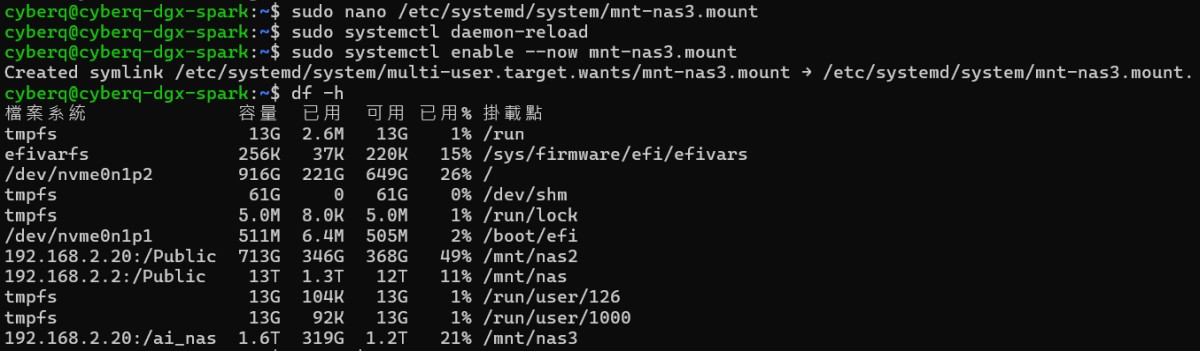
當儲存端與網路端基礎建設就緒後,便可進入 NVIDIA DGX Spark GB10 的 Linux 終端機環境進行實例部署。首先透過系統指令,將遠端 QNAP NAS 的高速分享目錄(例如網段中的高速分享資料夾)直接掛載至本地端路徑,完成檔案系統的映射。
隨後我們啟動專為次世代架構設計的 ds4-server 推理引擎。從實際執行的終端機日誌可以看到,我們直接載入了存放在 NFS 高速儲存路徑下的 DeepSeek-V4-Flash 量化大型語言模型。執行命令中明確指定了高達十萬記號(ctx 100000)的超大上下文長度,並且將關鍵的鍵值快取磁碟目錄(kv-disk-dir)直接設定在遠端 NFS 分享路徑下,減輕一些地端 AI 運算節點的記憶體壓力。
隨後日誌清楚顯示,ds4-server 成功在 NVIDIA GB10 架構上初始化了 CUDA 後端。得益於 100GbE 加上 RoCE 的高頻寬,總共達九十幾 GB 的模型張量映射與權重載入在短短二十幾秒內便建構完成,比原本跑 SATA SSD 與硬碟的一百多秒執行時間要快上不少,且系統順利在本地連接埠開啟監聽服務,準備迎接該網段內指定好機器的 AI 推理請求。
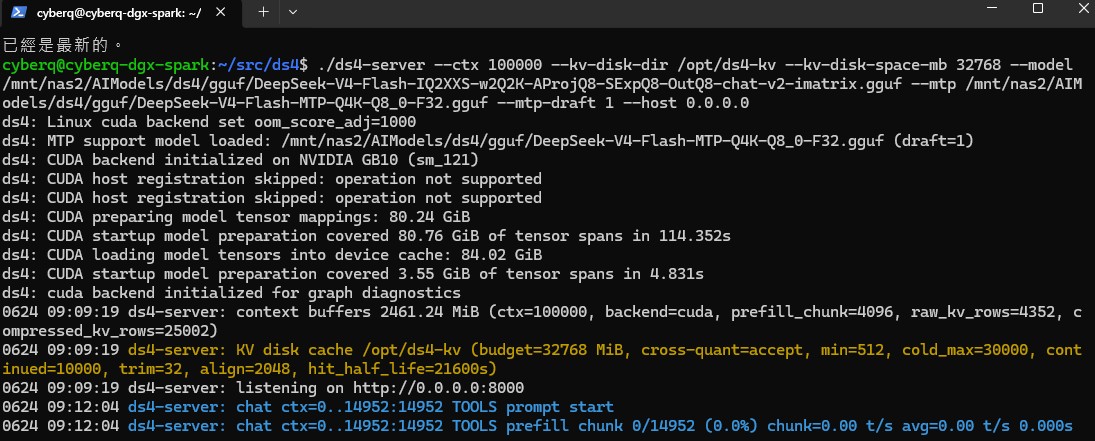
下圖中可以看到改用 SSD 擴充卡後,這個載入速度加快很多,也讓 GB10 可以直接掛載模型檔和處理快取檔資料。雖然這個數值尚未完全頂到該架構的理論頻寬上限,但考慮到這是在網路環境下進行遠端掛載,且軟體層在處理張量對應時需要同步消耗系統與處理器的運算資源,能在不到 30 秒內把這些檔案全部推進 NVIDIA GB10 的統一記憶體中,已經是非常流暢的表現,解決了過去掛載 10GbE NFS 的儲存設備在這種 AI 模型載入環境中需要漫長等待的問題。
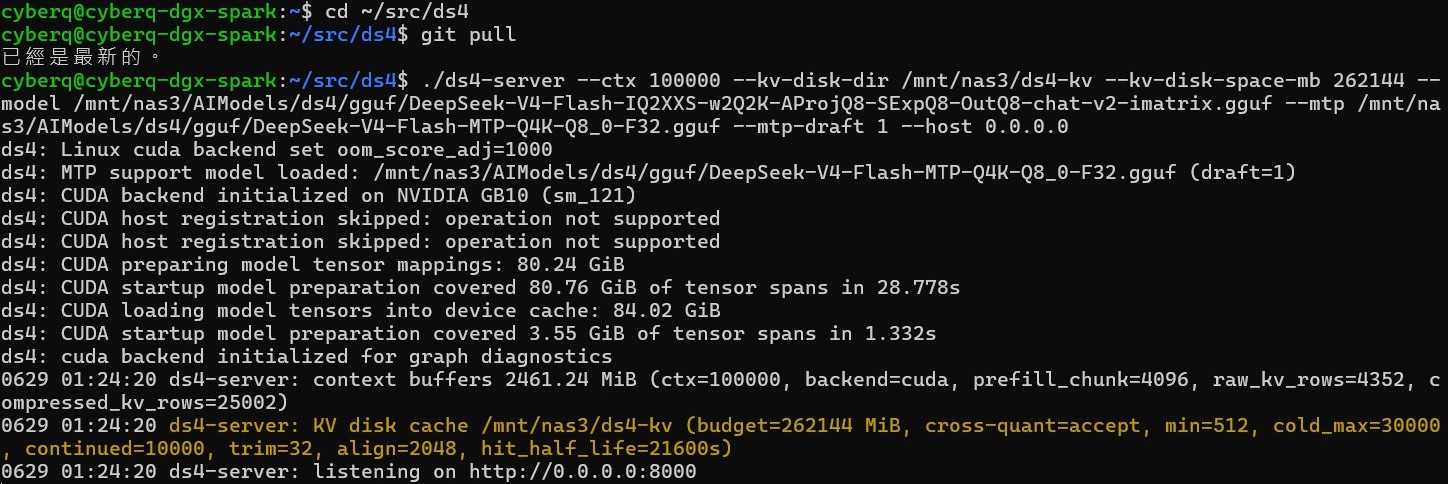
透過將計算與儲存分離,藉由 100GbE NFS over RDMA 緊密結合的架構,為現代 AI 資料中心提供了相當程度的彈性,免去了在每個計算節點重複拷貝大量模型檔案的時間與容量浪費,更利用了 QNAP 高速固態硬碟擴充卡的硬體優勢,為 NVIDIA GB10 晶片提供了接近本機儲存的存取體驗。
這套實戰配置經驗,是還不錯的參考,為當前追求效率改善的 AI 工程師與基礎設施架構師提供了一個參考藍本,適合搭配 AI 代理人與公司的 AI 伺服器節點使用。