在大型語言模型(LLM)的世界裡,大家都知道算力可以等,但記憶體(VRAM)卻是一翻兩瞪眼。當模型的上下文長度(Context Window)從 8K 狂飆到 32K 甚至 128K 時,推論過程中產生的龐大 KV Cache(鍵值快取)往往會瞬間撐爆我們使用設備的 GPU 顯示記憶體。
然而在 2026 年 3 月下旬,一場由 Google Research 點燃、並由開源社群推向高潮的 VRAM 解放熱潮正在進行中。Google 日前發表了即將在下個月於 ICLR 2026 登場的極限壓縮演算法 TurboQuant,宣稱能在零精度損失、免微調、免校準的前提下,將 KV Cache 壓縮至 3~4 bits(高達 6 倍壓縮率),它的本質是在用算力換記憶體,只是透過演算法設計,把這個 trade-off 壓到極低。但按照慣例,Google 官方並未第一時間就同步釋出原始碼,應該會在論文發表後釋出。
對於苦於 OOM (Out of Memory) 的開發者來說,這怎麼等得及?短短數週內,由前 Google 工程師 TheTom(pidtom)主導的 GitHub 開源專案 TheTom/turboquant_plus 馬上橫空出世。TurboQuant+ 實作復刻了這項神級演算法,更加入了超越原論文的殺手級工程最佳化,成為近期 Hacker News 與 Reddit (r/LocalLLaMA) 上最火熱的焦點。
CyberQ 實際部署 turboquant_plus,來看看這個改變邊緣 AI 生態的專案、它對硬體市場的影響,以及開發社群現況。
為什麼是Plus?TheTom 的殺手級創新
要了解 turboquant_plus 有多強,我們得先知道原版 TurboQuant 做了什麼。原版技術主要是依賴兩個我們之前提過的階段。
PolarQuant,利用隨機正交旋轉(Walsh-Hadamard Transform)將資料分佈強制高斯化,消除傳統量化所需的常數開銷。
QJL(量化 Johnson-Lindenstrauss),僅用 1-bit 來進行殘差修正,確保注意力機制不失真。
然而,TheTom 的專案之所以加上Plus,是因為他解決了量化模型最致命的問題,反量化(Dequantization)帶來的計算延遲。
Sparse V 的獨家創新
在 LLM 處理長文本時,絕大多數的歷史 Token 對當下生成的影響其實微乎其微。TheTom 在幾天前發布了一項震驚社群的最佳化,在 Flash Attention 過程中,直接將算出來的 Attention 權重當作門控信號。如果某個位置的權重極小(<10−6),就直接跳過該位置 Value (V) 快取的反量化運算,讓 KV Cache 不只是被壓縮,而是開始不被計算。
這項只算有用資訊的設計帶來了驚人的實戰成績,首先是解碼速度提升 22.8%,在 32K 長上下文測試中,這項技術跳過了高達 90% 的無效運算,讓解碼吞吐量大幅飆升。
其次是零品質退化,甚至更好,不僅困惑度(Perplexity)毫無退化,在大海撈針(NIAH)的長文本檢索測試中,因為過濾掉了微小權重帶來的量化雜訊,檢索表現反而有所提升。
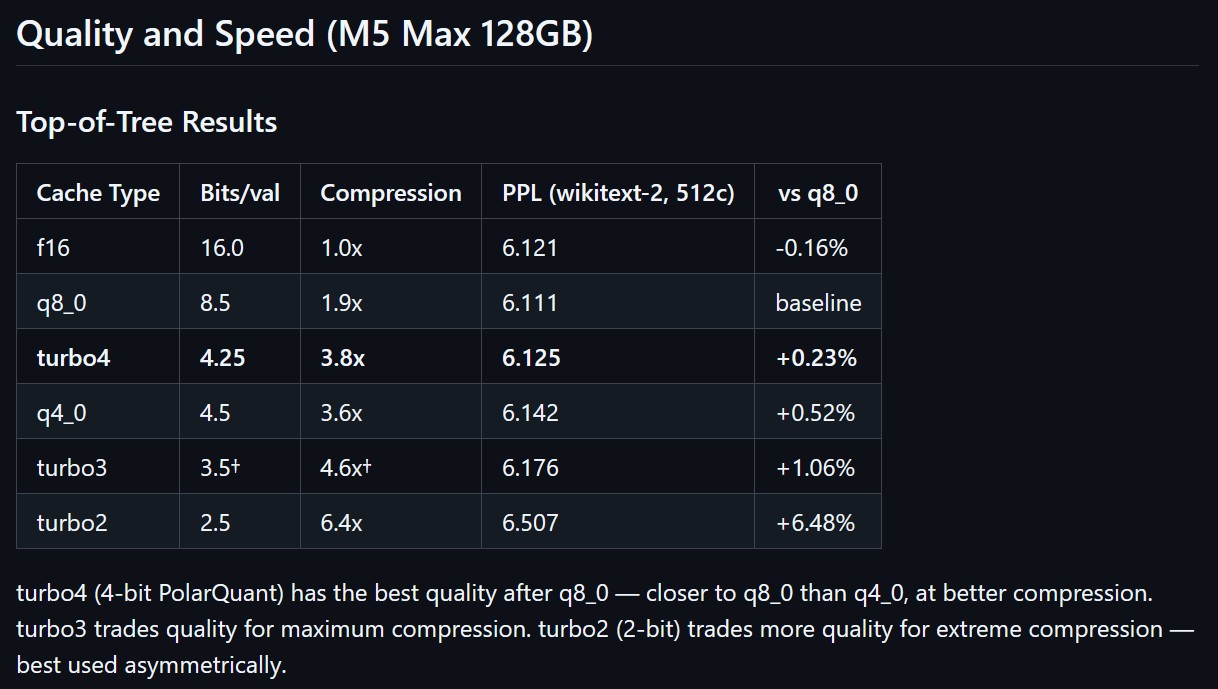
也因為這樣,所以更多人的硬體就可以跑 AI 模型跑得更好了,該專案已經成功整合進 llama.cpp,並在 Apple Silicon (Metal) 上完美執行。透過將旋轉運算移至計算圖端,其 3.5-bit (turbo3) 格式的預填充(Prefill)速度甚至追平了未壓縮的傳統 q8_0 格式。
此外,社群在該專案的實作中也發現了論文未提及的眉角,Key(鍵)對量化雜訊比 Value(值)敏感得多。因此,採用非對稱位元分配(例如 4-bit K 搭配 2-bit V)成為了避免模型崩潰的關鍵實戰策略。
改變硬體經濟學,VRAM 用量降低與 Mac 、CUDA 都將受益
TurboQuant 與 turboquant_plus 的出現,實質上改變了企業與開發者建置 AI 基礎設施的 ROI(投資回報率)。TurboQuant+ 的真正衝擊,不只是省 VRAM,而是開始侵蝕只有大模型才能做長上下文推論這個假設。
現階段既有的 Build-vs-Buy 的採購決策有可能會跟著調整,當前 AI 大廠雖然掌握了強大的雲端算力,但基於資訊安全合規性與企業隱私考量,自行託管(Self-hosting)與本機端推論的需求正日益增長。從 TurboQuant+ 的硬體支援狀態,可以看出目前的市場實作趨勢。
在這之前,很多公司想讓 AI Agent 擁有長期的上下文記憶,跑滿 72K 上下文的 70B 等級模型,光 KV Cache 就會吃掉 20GB 以上的顯存,迫使企業依賴昂貴的多卡伺服器或雲端 API。現在,同樣的工作負載被縮減到不到 5GB。這意味著,兩張消費級的 RTX 3090,或是一台 2,000 美元的 Mac Mini M4 Pro,就有機會處理企業級的長文本 Agent 任務。本地部署 AI 的成本出現了大規模的下降。
同樣的,針對資料中心、企業中高階 AI 推論與訓練市場,硬體門檻的解放,並不是成本降低,而是既有投資的硬體可以獲得更高的吞吐量和效能,實作更大更有效率的多樣化模型,這些演算法的更新,對產業是有相當幫助的。
Apple Silicon 現在可說是佔據先機,專案目前對 Apple 的 M 系列晶片(如 M1/M2/M5 Max)支援度最高,在 128GB 的 M5 Max 上,已經能達到與 q8_0 幾乎一致的預填(Prefill)速度,以及約 0.9 倍的解碼吞吐量。Apple Silicon 在這波會被受惠,並不是因為它的算力強,而是它的記憶體架構剛好對 KV cache 友善。這對於經常建置家庭實驗室(Home Lab)或依賴高階 Mac 進行 AI 工具開發的工程師來說,是一大福音。
同時,NVIDIA 陣營蓄勢待發,雖然專案在 Mac 平台 Metal 上的表現亮眼,但 CUDA 後端(針對 NVIDIA GPU)的移植目前仍在進行中。這是許多使用高階顯卡(如 RTX 3090/4090 或資料中心等級伺服器)用戶目前正進行社群測試中,預期未來 CUDA 更新版本陸續釋出,以及 Google 論文發表且演算法釋出後,屆時業界更多的相關實作,預期將能進一步釋放這些頂規硬體的潛力。
記憶體晶片廠的短暫下跌效應?
另一方面,金融市場對此反應極為敏銳。隨著 TurboQuant 降低了 AI 推理對高頻寬記憶體(HBM)與超大 VRAM 的硬性依賴,買 AI 顯卡其實是在買記憶體的市場需求似乎會被削弱,但關於這一點,市場意見還有歧見。
不過,這已經直接導致了三星(Samsung)、SK 海力士(SK Hynix)與美光(Micron)等記憶體晶片大廠的股價在消息釋出後出現顯著下跌。
開源社群認真實作、極限魔改與學術羅生門
CyberQ 觀察,目前的開源社群呈現出高度活躍且充滿戲劇性的狀態。
各路大神魔改
開源的魅力在於不斷突破極限。除了 TheTom 的實作外,社群的創意正在陸續長出來中。例如,有開發者提出了名為 RotorQuant 的大膽構想,試圖用克里福代數轉子(Clifford rotors)取代原版的密集矩陣乘法,追求 10 到 19 倍的底層運算加速。同時,針對 vLLM 的整合 PR 也正如火如荼地進行中。
籠罩在學術倫理爭議的陰影
就在社群為 TurboQuant 歡呼時,Reddit 上爆發了激烈的學術爭議。2024 年 9 月發表的另一篇量化論文 《RaBitQ》 的作者群公開出面控訴。他們指出,TurboQuant 的核心隨機正交旋轉技術與他們高度重疊,卻在 ICLR 論文中被淡化並塞進附錄,更具爭議的是,RaBitQ 團隊公開郵件指出,Google 在做效能對比測試時,疑似讓 RaBitQ 跑在單核 CPU上,卻將自己的 TurboQuant 跑在A100 GPU上,存在嚴重的誤導。
這場大廠與學界的公關危機目前仍在延燒,讓社群關注中。不過,面對學術圈的口水戰,TheTom 本人的態度相當務實,他表示自己雖是前 Google 工程師(但早於此研究前兩年半就已離職創業),目前他只關心如何把這套極限壓縮技術變成大家都能用的 C/C++ 程式碼。
算力瓶頸依舊在,同志仍須努力
TheTom/turboquant_plus 的爆紅,詮釋了開源社群強悍的速度與生命力,當科技大廠努力開發,以及進行學術發表流程時,駭客與工程師們則進一步把概念與數學公式研究,寫成了可用的程式碼,還疊加了 Sparse V 這類實戰最佳化,繼續把硬體效能推昇。社群正在實驗如何讓歷史越悠久的 KV Cache 使用越少的記憶體,目前的實驗分支已能在長文本下額外節省 30-34% 的記憶體空間。至於MoE 模型支援方面,針對 Qwen 3.5 35B 等混合專家(MoE)模型的壓縮也已得到驗證。
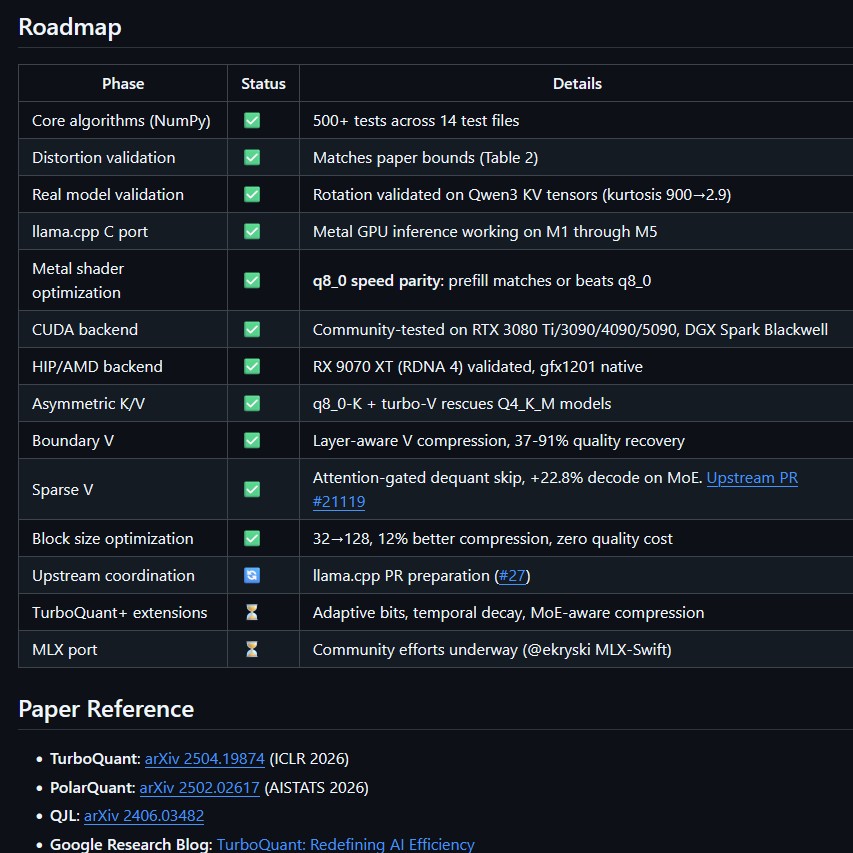
大記憶體時代的下半場才剛剛開始,上面是該專案的 Roadmap 狀態。目前該專案與社群正積極透過 CUDA 高手測試與開發,將 Apple Metal 體驗平移到 NVIDIA GPU 上。目前在 RTX 3080 Ti/3090/4090/5090、DGX Spark Blackwell 上已經通過社群測試了。
根據專案官方的實作設定建議 (TurboQuant Configuration Recommendations),目前蘋果 Metal (M1 到 M5 晶片)、CUDA (NVIDIA RTX 3080 Ti 到 Blackwell)、 HIP (AMD RDNA 4) 等硬體,已經都能夠跑這個專案,詳細設定可以看 GitHub 上的指引和社群反應的測試情形。
如果你的專案深受 LLM 上下文長度的記憶體限制所苦,現在絕對是前往 GitHub 給 TheTom/turboquant_plus 打顆星星 Star,親自體驗這場 VRAM 解放的脈動。
CyberQ 認為 TurboQuant+ 提供了一個兼顧推論效能與硬體限制的絕佳方案。它不僅有效解決了長文本處理時記憶體吃緊的問題,更透過 Sparse V 等演算法的最佳化,證明了我們還能從純軟體與數學層面榨出更多本機硬體的效能。如果你正在尋找提升開源模型執行效率的方法,這個專案絕對值得親自測試。