

在人工智慧的高速發展下,通用人工智慧(AGI)的實現被視為解決人類重大挑戰的關鍵里程碑。然而,我們該如何精準衡量當前的 AI 系統距離 AGI 還有多遠?為了解決缺乏實證評估工具的問題,Google DeepMind 日前發表了最新論文《Measuring Progress Toward AGI: A Cognitive Taxonomy》(邁向 AGI 的進展衡量:認知分類架構),正式將認知科學引入 AI 評測領域,為 AGI 的測量建立全新的科學基礎。
解構通用人工智慧的十大認知能力
DeepMind 研究團隊汲取了心理學、神經科學與認知科學數十年的研究成果,提出了十項對 AI 系統實現通用智慧所需要的核心認知能力:
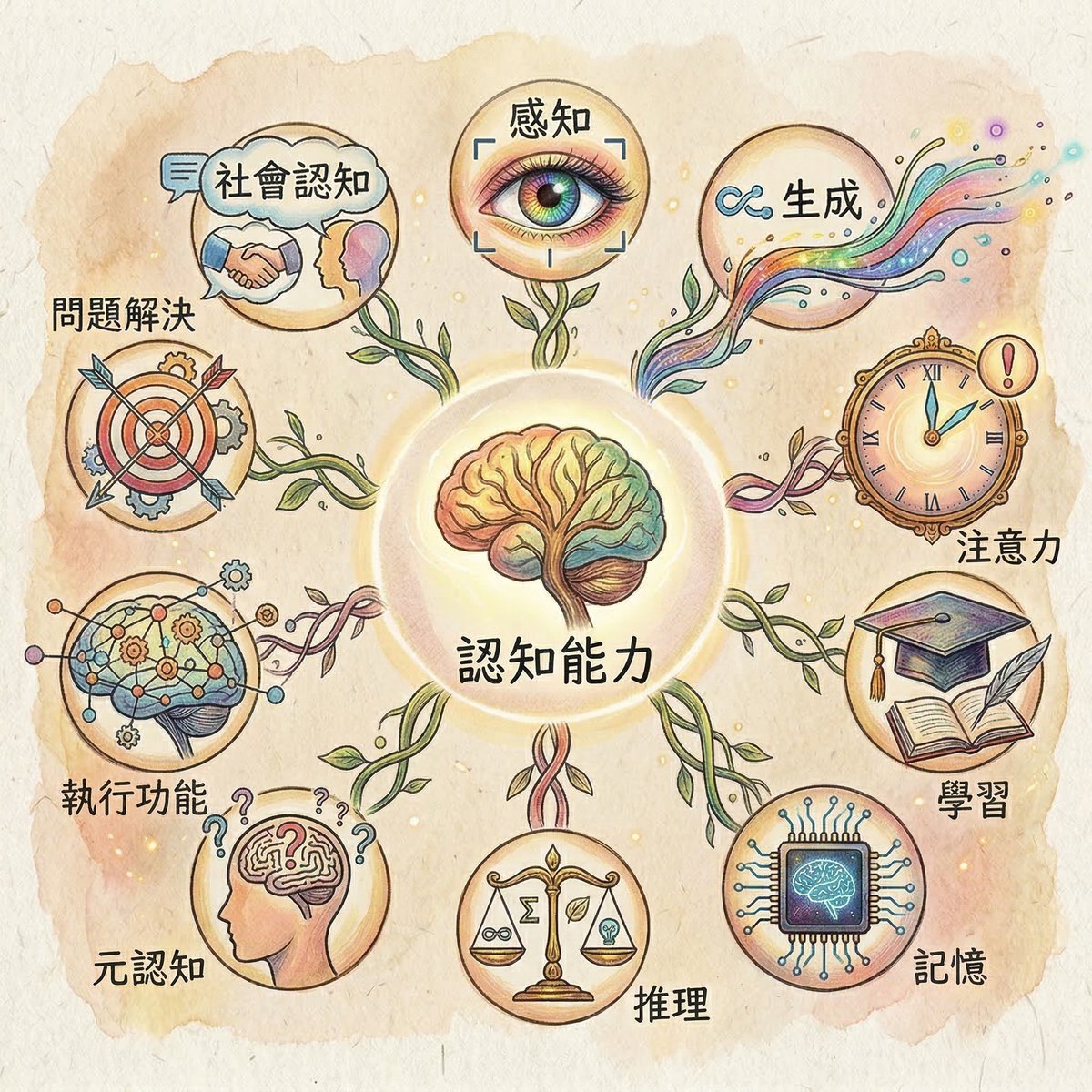
感知(Perception):從環境中萃取與處理感測資訊。
生成(Generation):產出文字、語音與動作等結果。
注意力(Attention):將認知資源集中於關鍵事物。
學習(Learning):透過經驗與指令獲取新知識。
記憶(Memory):長時間儲存與檢索資訊。
推理(Reasoning):透過邏輯推論得出有效結論。
後設認知 / 元認知(Metacognition):了解並監控自身的認知過程。
執行功能(Executive functions):具備規劃、抑制衝動與認知靈活性。
解決問題(Problem solving):針對特定領域的問題尋找有效解法。
社會認知(Social cognition):處理與解讀社會資訊,並在社交場合做出適當反應。
三階段評估協議來對標人類基準
為了確保評測的嚴謹性,並避免過去常見的訓練資料污染(Data contamination)導致模型淪為只會答題的考試型學生,DeepMind 提出了一套三階段評估標準。
首先,使用未公開的測試資料集(Held-out test sets),針對上述認知能力進行廣泛的任務測試。
接著,從具備人口統計學代表性的成年人群體中,收集相同任務的人類基準線(Human baselines)。
最後,將 AI 系統的表現與人類表現的分佈進行相對映射,以此建構出 AI 系統的認知畫像。
廣發武林帖的 20 萬美元 Kaggle 黑客松
由於理論必須經過實作來檢驗,為了填補當前 AI 評測機制的空缺,Google DeepMind 聯合我們熟悉的最大 AI 和機器學習社群,也是資料科學和機器學習愛好者的優秀網站平台 Kaggle ,共同推出了 Measuring progress toward AGI: Cognitive abilities 黑客松。這場競賽聚焦於目前評估差距最大的五個認知領域,學習、後設認知、注意力、執行功能與社會認知。
活動祭出 20 萬美元的總獎金池,包含單項賽道獎金與 2.5 萬美元的跨領域特等大獎。活動已開放報名,預計至 4 月 16 日截止,最終結果將於 6 月 1 日公布。這意味著評測 AGI 的出題權,正交棒給全球的開發者與研究人員。
2026 年 Q1 AI 產業最新動態與趨勢呼應
CyberQ 觀察,DeepMind 的評測框架在此刻顯得無比重要,正是因為整個產業的 AI 應用正從單純的對話式模型躍升為自主代理(Agentic AI)與具身智慧(Embodied AI)。在 2026 年 3 月中旬,市場上也出現了幾項高度呼應此框架的重大進展。
中國市場企業級 Agentic AI 的崛起,就在 DeepMind 發表框架的隔日(3/18),阿里巴巴(Alibaba)正式推出了企業用 AI 代理平台悟空(Wukong),對外宣稱能自主處理複雜業務的 Agentic AI 已進入規模化商用階段,其核心技術正高度依賴 DeepMind 框架中所提及的執行功能與解決問題能力。
另一個有意思的消息是實體機器人跨越實驗室,矽谷新創 Rhoda AI 日前宣布完成 4.5 億美元 A 輪融資。其核心技術 FutureVision 讓機器人能脫離實驗室的控制環境,在真實世界中透過影片預測與學習並自主行動。這項進展正好是在挑戰 AI 於實體世界中的感知、學習與注意力等高階認知表現。
CyberQ 認為,DeepMind 這套借鑑認知科學的框架,希望是能夠更充分評估大模型與實作能力的指標。未來 AI 將有機會以圍繞人類的主要十個認知能力為主要發展目標和切齊方針。







