隨著 AI 逐步拓展到各領域和大量的實作,業界的共識確實是訓練大型 AI 模型往往需要龐大的算力與極高的資金門檻,導致資源高度集中在少數科技大廠手中。為了稍微平衡一下這種運算壟斷的問題,去中心化 AI(Decentralized AI, DeAI)的底層基礎設施倡議應運而生,並陸續已經有專案落地。
比方說最近的 Alice Protocol ,它算是一個相當有意思的呈現,呈現出區塊鏈技術與分散式 AI 模型訓練結合的一種可實作方法。
Alice Protocol 的去中心化實踐與架構
CyberQ 分析,Alice Protocol 的架構重點,在於將分散式機器學習中關鍵的參數伺服器(Parameter Server)與區塊鏈的激勵機制有效接軌。
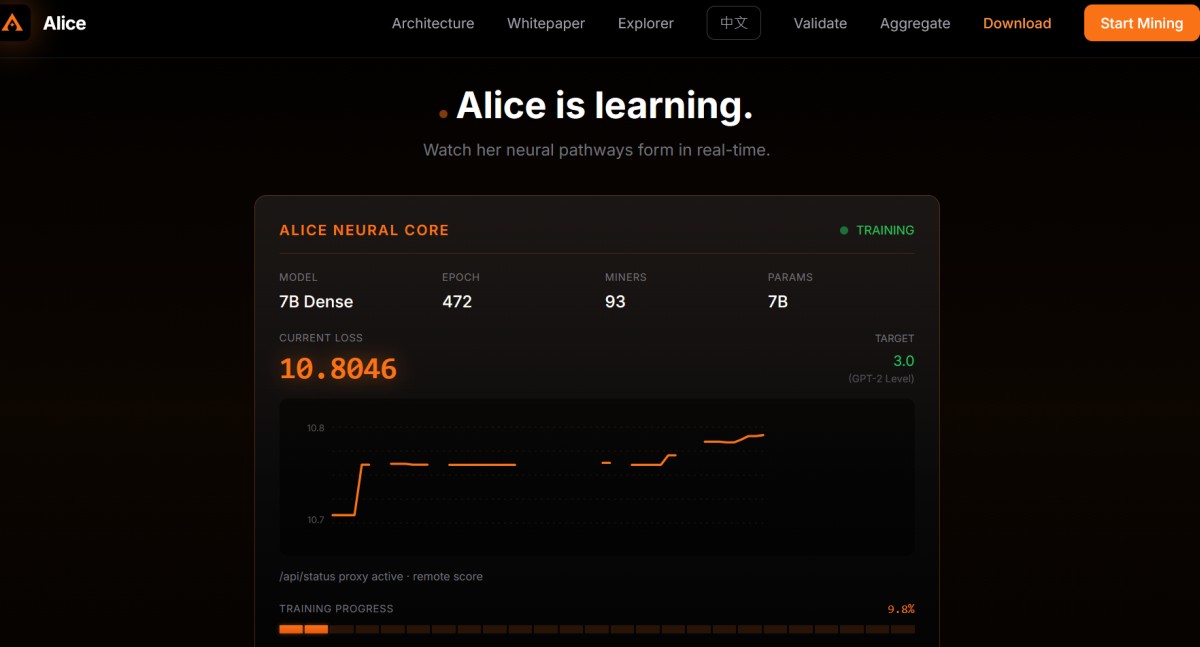
透過其官方的區塊鏈瀏覽器(Alice Protocol Explorer),我們不僅能看到一般的鏈上交易,更能即時追蹤 AI 模型在網路中的訓練進度。該系統的核心架構與訓練機制包含以下關鍵:
參數伺服器(PS)與聚合器池(Aggregator Pool),這種架構中,PS 負責管理模型版本與計算整體的訓練損失(Training Loss)。聚合器則負責收集全球礦工節點貢獻的大量運算結果(如神經網路的權重梯度),進而完成模型的更新與最佳化。
真實的訓練週期(Epoch)是相當重要的,那些加密礦工的運算,當然可以不再是無意義的密碼學雜湊碰撞。在每個 Epoch 中,數位礦工會處理特定的資料分片(Shards),真實推進機器學習的訓練,並讓 Training Loss 持續下降。
如此一來,也會產生透明的代幣經濟學(Tokenomics)。系統可以用去中心化的方式保守評估網路算力(基於 GPU 估算的 TFLOPS),並發放原生的 ALICE 代幣獎勵(最大供給量與比特幣同為 2,100 萬枚)。瀏覽器在設計上嚴格區分了區塊鏈確定性資料、索引歷史資料與 PS 即時狀態,確保了資訊的透明與防篡改。
業界去中心化 AI 的三大技術趨勢
Alice Protocol 並非孤軍奮戰,CyberQ 觀察近期的技術文獻與業界動態,我們可以看到幾個正在改變 AI 基礎設施格局的趨勢。
聯邦學習(Federated Learning)與區塊鏈的合流
根據 UniAthena 與 Prometheus-X 的研究,去中心化訓練的核心精神在於資料不動、模型動。參與網路的節點在本地端進行訓練,僅將加密後的模型權重更新上傳至區塊鏈智慧合約進行聚合。從資安與合規的角度來看,這種架構完美符合 GDPR 等嚴格的隱私法規要求,使得醫療、金融等擁有高度機敏資料的產業,也能在零信任、不外洩個資的前提下安全參與 AI 協同訓練。
突破通訊瓶頸的網路架構
去中心化訓練在過往階段最大的技術阻礙在於跨節點的網路延遲(Latency)與頻寬限制。然而,近期 0G Labs 帶來的突破性框架也很值得我們關注。他們成功在一般 1 Gbps 的商用網路上,跨節點訓練出高達 107B 參數(接近 GPT-4 規模)的巨型語言模型。透過 Delay-tolerant 設計與適應性梯度壓縮技術,這讓開發者不再需要依賴昂貴的資料中心光纖網路,也能高效執行大型模型的訓練。
協定級模型(Protocol Models)的資產化
CyberQ 觀察,新一代網路正透過異步的模型並行(Model-Parallel)策略,將 AI 模型的權重分片(Sharded)分散至多個節點上。這意味著沒有任何單一節點能掌握完整的模型原始碼,大幅提升了防外洩的資訊安全層級,也讓模型真正成為協定內的資產。參與訓練的程式開發者與礦工,能依據貢獻度獲得模型未來營收的分配權與治理權。
運算權力的部分再分配
CyberQ 認為,確實許多科技大廠藉由自己雄厚的資本和技術,已經築起算力與資料的高牆,這讓很多中小企業是很難追趕上的,這點也沒錯。但是呢,當 Alice Protocol 以及諸多 Web3 DeAI 專案正在用去中心化的架構進行開發,我們也正處於一個關鍵的轉折點。
AI 市場當然不會只有閉源、開源,也會有集中式管理、開放運算(Open Compute)與分散式治理,很值得多觀察和研究。