馬斯克的 xAI 公司正式推出全新模型 Grok 4.1,即日起所有用戶皆可透過 grok.com 網站、X 平台以及 iOS 與 Android 應用程式進行體驗,這款新模型已透過 Auto 模式陸續推送,並可在模型選擇器中直接切換使用
本次更新外界關注的是其大幅提升人工智慧在現實世界中的實用性,Grok 4.1 在創意寫作、情感交流以及協作互動方面展現了更卓越的能力,新模型不僅能更敏銳地察覺使用者的意圖,在對話過程中也更具備連貫性與個人風格,同時保留了先前版本在智慧運算與可靠性上的優勢。
在技術層面上,Grok 4.1 沿用了驅動 Grok 4 的大規模強化學習基礎架構,並針對風格、個性、協助性與安全性進行了最佳化,為了改善這些難以量化的獎勵訊號,開發團隊採用了全新的方法,利用具代理式推理能力的大型模型作為獎勵模型,自動化評估並大規模迭代模型的回答品質。
靜默發布期間表現優異,稱霸 LMArena 文字排行榜
在正式發布前,xAI 於 2025 年 11 月 1 日至 14 日期間進行了為期兩週的靜默發布,將 Grok 4.1 的初步版本逐步推送到 grok.com、X 平台及行動裝置的生產流量中,在對比舊模型的盲測中,有 64.78% 的情境中使用者更偏好 Grok 4.1 的回應。
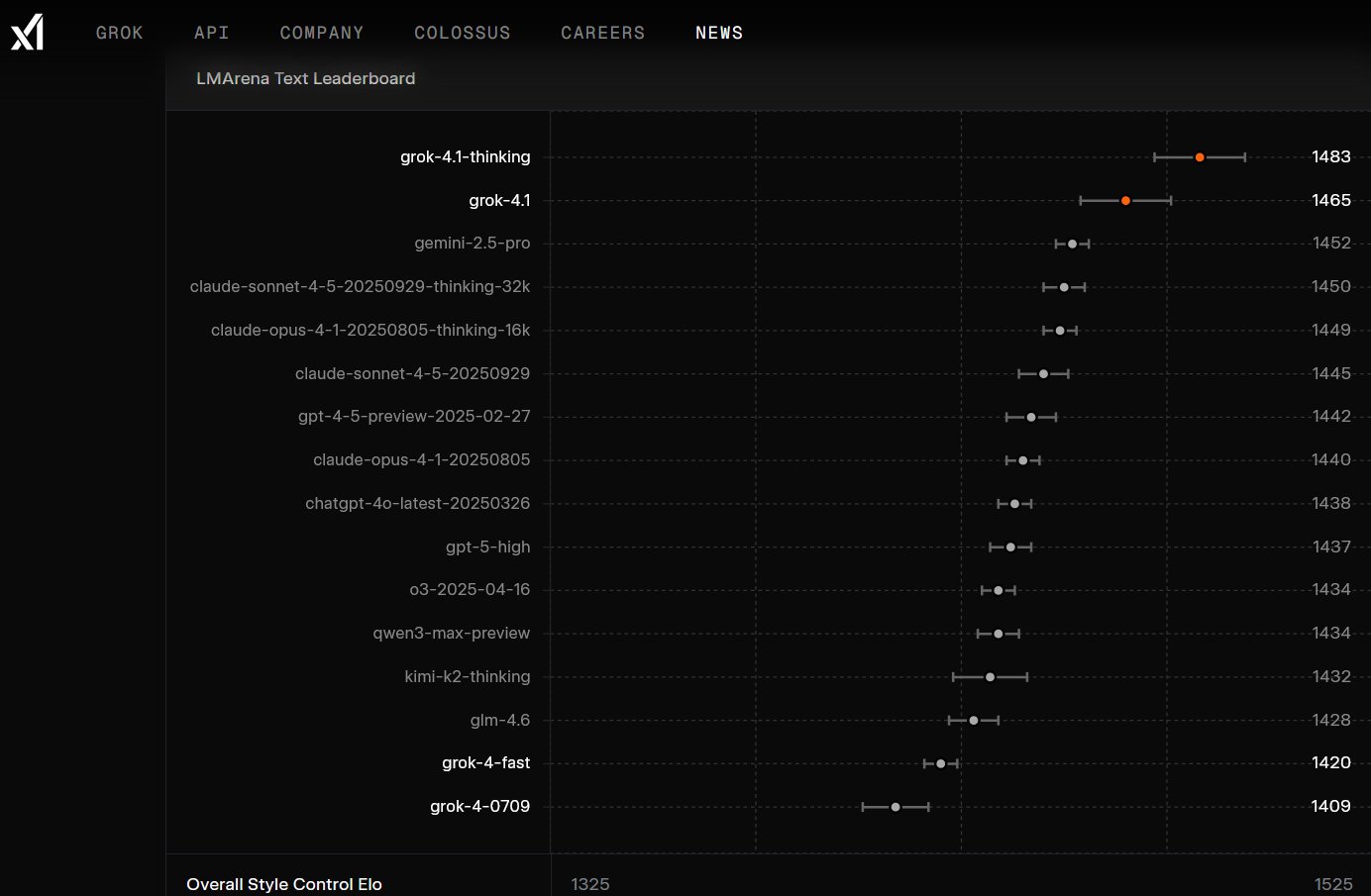
Grok 4.1 在 LMArena 的盲測人類偏好評估中樹立了新標準,代號為 quasarflux 的 Grok 4.1 Thinking 版本以 1483 分的 Elo積分佔據排行榜第一名,領先非 xAI 最高分模型達 31 分之多,而代號為 tensor 的非推理模式版本 Grok 4.1 也以 1465 分位居第二,其表現甚至超越了其他競爭對手具有完整推理能力的模型配置,相較於先前排名第 33 名的 Grok 4,進步幅度相當驚人。
情感商數與創作能力大幅提升
為了衡量模型在個性與人際互動上的進步,開發團隊使用 EQ-Bench3 對 Grok 4.1 進行了評估,這是一項由大型語言模型擔任評審的測試,旨在檢驗模型的情感智商、同理心與人際技巧。
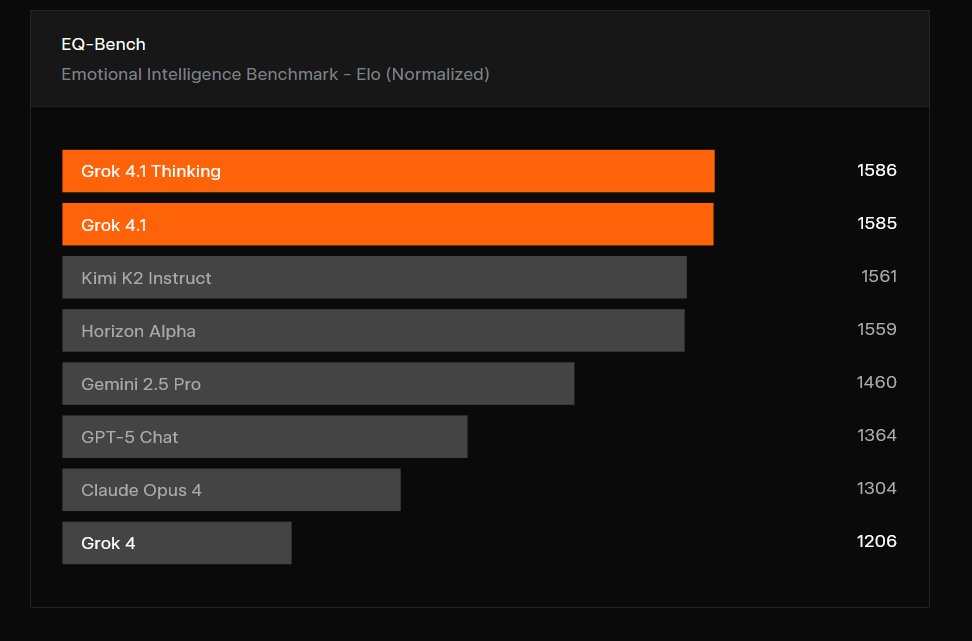
測試結果顯示,Grok 4.1 Thinking 以 1586 分的標準化 Elo 積分位居榜首,展現了更細膩的情感處理能力,以面對用戶表達失去寵物的悲傷為例,Grok 4.1 的回應不再僅是制式的安慰,而是能給予更具溫度與同理心的回應。
在創意寫作方面,Grok 4.1 在 Creative Writing v3基準測試中同樣表現出色,Grok 4.1 Thinking 取得了 1721.9 分的成績,證明了其在處理複雜寫作任務時的靈活性與創造力。

降低幻覺與提升資訊準確度
快速且具備搜尋功能的非推理模型雖然能提供即時答案,但往往受限於推理深度而容易產生事實性錯誤,針對此問題,Grok 4.1 在後訓練中特別著重於減少資訊查詢類問題的幻覺現象。。
根據針對真實世界生產流量的評估結果,Grok 4.1 的幻覺率僅為 4.22%,遠低於 Grok 4 的 12.09%,在 FActScore 公開基準測試中,Grok 4.1 的錯誤率也從先前約 9.89% 降至 2.97%,顯示其在提供準確資訊方面的可靠性已大幅提升。