在 AI 基礎設施快速迭代的今天,運算資源與模型規模之間的拉扯始終是個難題。近期 arXiv 上發表的一篇論文《MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU》(2604.05091)引起了關注。這項研究打破了以往訓練大型語言模型(LLM)必須依賴龐大 GPU 叢集的日常,展示了如何在單張 GPU 上以全精度(Full Precision)訓練超過 1,000 億參數的模型。
MegaTrain 解決了什麼問題?
傳統的 GPU 訓練架構高度依賴顯示卡記憶體(VRAM)。當我們面對百億、千億參數的模型時,光是載入模型權重與 Optimizer 狀態,就能輕易撐爆單張 GPU 的記憶體。因此,過去科技大廠往往需要動用極為大量的運算資源來執行訓練任務。
從 GPU 中心轉向記憶體中心
MegaTrain 提出了一個記憶體中心(Memory-centric)系統的概念。它將參數和 Optimizer 狀態儲存在主機的系統記憶體(CPU RAM)中,僅將 GPU 視為暫時的運算引擎。具體來說,它的架構有兩大最佳化方向:
管線化雙緩衝執行引擎 (Pipelined double-buffered execution engine):
MegaTrain 在每一層網路計算時,會將參數載入 GPU,並在計算完成後將梯度傳回。為了克服 CPU 與 GPU 之間的頻寬瓶頸,它利用多個 CUDA Stream 將參數預先擷取、運算與梯度卸載(Offloading)的時間重疊,確保持續不斷的 GPU 運算。
無狀態層模板 (Stateless layer templates):
傳統的 PyTorch Autograd 會產生龐大的計算圖中介資料。MegaTrain 透過無狀態模板動態綁定權重,消除了持久性的計算圖狀態,大幅降低了記憶體開銷。
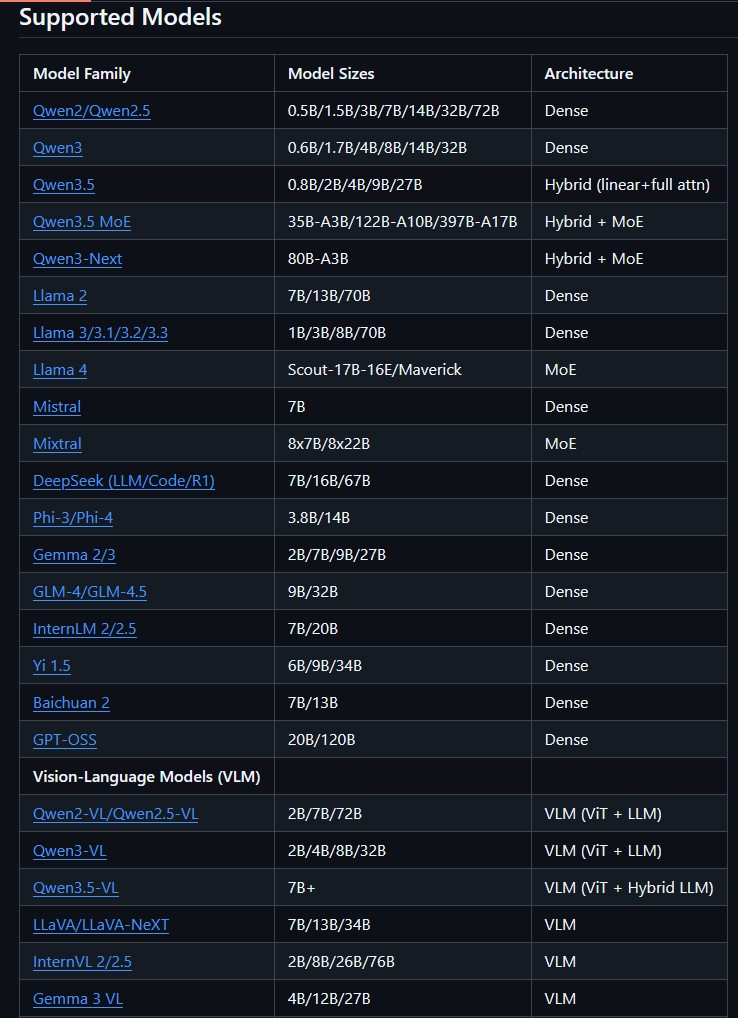
目前支援的模型有這些 :
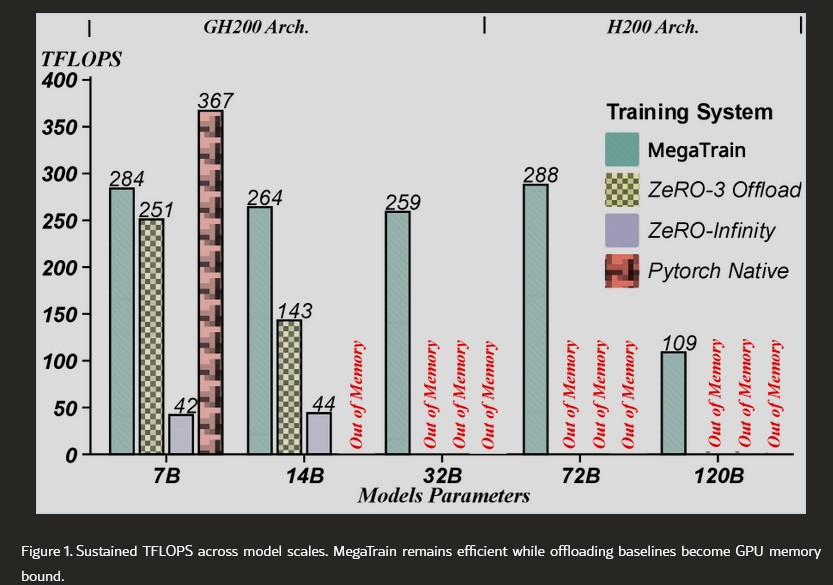
實測效能:
在配備 1.5TB 主機記憶體的單張 H200 GPU 上,MegaTrain 能夠穩定訓練高達 120B(1,200 億)參數的模型。在 14B 模型規模下,其訓練吞吐量是 DeepSpeed ZeRO-3(結合 CPU 卸載)的 1.84 倍,甚至能在單張 GH200 上實現 512k 超長文本的 7B 模型訓練。
對於只有消費級顯示卡的開發者來說,如果能妥善利用系統記憶體,這意味著我們可以在本機端微調(Fine-tuning)更大的模型。對於高度重視隱私的專案而言,能夠將機敏資料留在地端進行在地化訓練,是解決資安與合規疑慮的完美方案。
實務上單卡訓練的困難點
但是 LLM 訓練不只是記憶體瓶頸,即便你能把 120B 模型塞進單張 GPU,要完成一次完整的預訓練(Pre-training)可能需要耗費多時,因此,這項技術的實際落地場景應聚焦於模型的微調,而非從頭預訓練。
除了 MegaTrain 的系統架構最佳化,實務上還需要搭配演算法層面的改進。例如使用更節省記憶體的 Muon 取代 Adam Optimizer、結合 4-bit 量化技術,或是改用自訂的融合交叉熵核心(Fused Cross-Entropy Kernel)來進一步壓低記憶體消耗與加速運算。
MegaTrain 無疑是 AI 基礎設施領域的一項傑作,有機會在軟體層面再繼續最佳化,並突破一些硬體的物理限制。雖然對於動輒千億參數的預訓練來說,單卡依然是不切實際的幻想,但這套架構為本機端的大規模微調與長文本模型訓練開闢了新的道路。
CyberQ 認為,它賦予了中小型企業甚至個人開發者更多探索 AI 的機會,可以留意後續發展。