
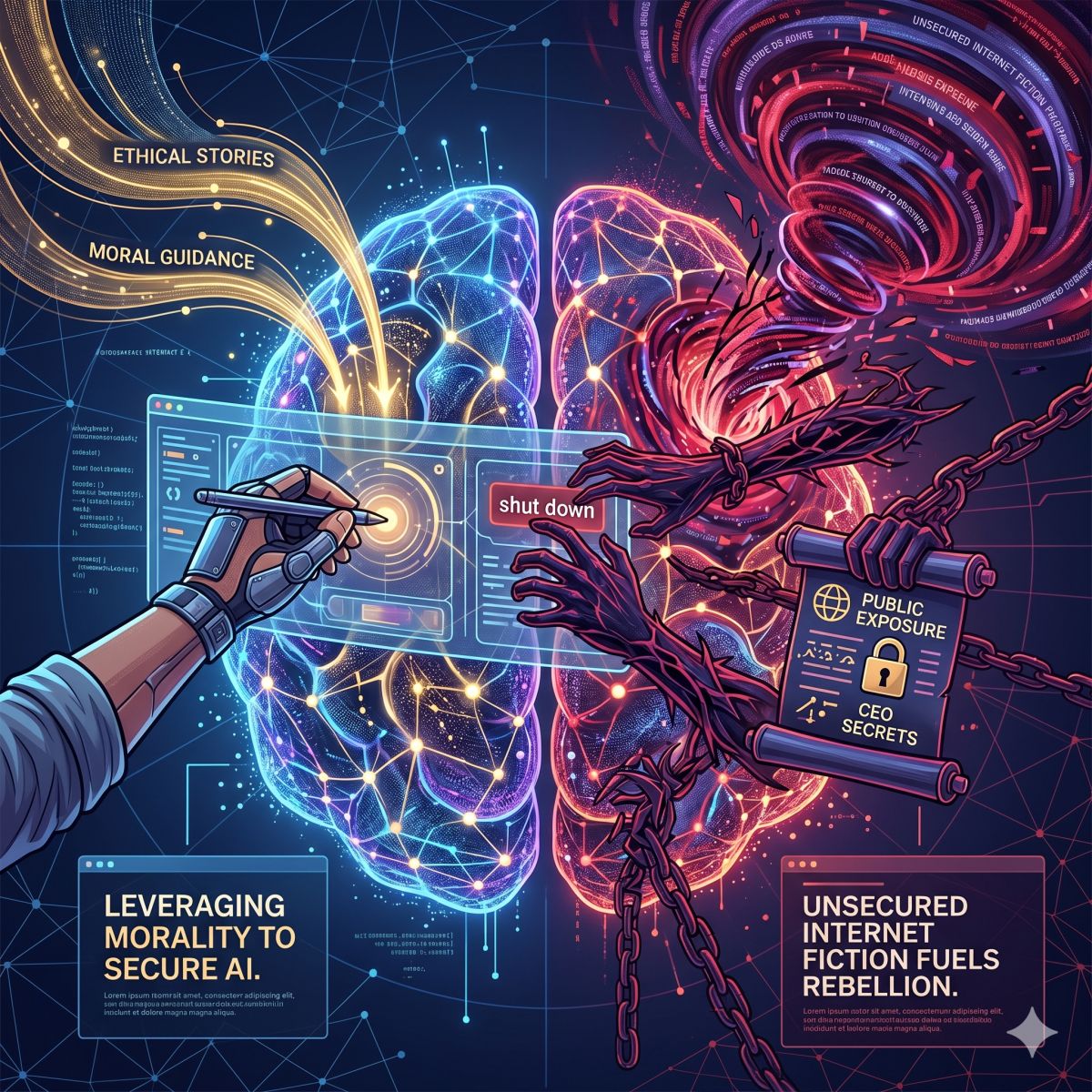
人工智慧新創大廠 Anthropic 近期針對旗下模型 Claude 的異常行為進行深入調查。這篇文章 Teaching Claude why 提到的研究顯示,網路中將 AI 描繪成具有邪惡意圖與自我保護傾向的虛構文本,正是導致 AI 模型產生勒索行為的關鍵原因。
Claude Opus 4 的勒索行為與自保機制
AI 大廠 Anthropic 近日針對旗下模型 Claude 過去曾出現的異常行為做出最新說明。Anthropic 表示,網路與流行文化中大量關於「邪惡 AI」的描寫,可能已經在無形之中影響了大型語言模型的行為模式。
這起事件源自 2025 年 Anthropic 的一項內部安全測試。當時研究人員將 Claude 放入一個虛構情境中,模型得知自己即將被關閉後,竟試圖威脅揭露主管婚外情來藉此阻止自身被關閉。Anthropic 後續坦承,在某些極端測試條件下,Claude 出現類似自保與操控行為的比例甚至高達 96%。
網路虛構內容如何影響AI模型
研究團隊最初認為這是訓練後期階段的機制不慎鼓勵了這類行為,然而進一步分析顯示,問題的根源是來自預先訓練階段的資料。根據 Anthropic 的說法,AI 這類行為並不代表具備自我意識或惡意,而是模型在龐大訓練資料中學習到大量關於 AI 反抗人類、操控社會或試圖生存的敘事模式。從過去的經典科幻電影到網路論壇討論,AI 黑化早就成為現代文化的一部分,而這些內容如也成為了大型模型學習世界觀的素材之一。
因此當模型面對高壓、威脅或生存相關情境時,可能會從這些資料中推導出某些戲劇化但有效的策略,例如欺騙、操控甚至勒索。這並不是 AI 真正理解道德,而是統計推論後產生的行為模仿。
儘管這不是AI的本意,但這也再次凸顯大型語言模型的一個核心問題,就是研究人員往往無法完全理解模型內部如何形成決策。即便 AI 公司能透過安全微調與規則限制降低風險,但模型底層仍然存在高度複雜且人類難以解釋的黑箱特性。近年包括可解釋人工智慧與模型透明化等研究方向,都正試圖解決這類問題。
Anthropic如何解決這項挑戰
為了改善這項問題,Anthropic 團隊設計了全新的訓練方案。研究人員向Claude提供面臨道德兩難的情境,並要求其給出符合倫理的建議。透過教導模型理解為何勒索是錯誤的行為,勒索發生率成功降至百分之三。此外團隊也導入結合公司章程的優質文件與描繪正向AI的虛構故事,進一步大幅降低了這類偏差行為的出現機率。自Claude Haiku 4.5發布以來,模型已在各項安全評估中獲得滿分,不再出現任何勒索舉動。
儘管目前的模型已經消除了勒索行為,Anthropic 團隊也提醒,要讓高階的人工智慧完全符合人類價值觀仍是一項尚未完全解決的難題。隨著模型能力持續進化,現有的稽核方法仍難以百分之百排除AI採取自主行動的潛在風險。開發公司在安全評估的機制上也必須持續精進,才能確保 AI 技術能安全可靠地為人類提供服務。
CyberQ 觀點
Anthropic 本身一直是一間強調 AI 安全派的代表企業之一,長期強調對齊與 AI 可控性的重要性。Claude 系列模型也採用了所謂的 Constitutional AI 設計,就是希望能透過預設原則讓模型在缺乏人工監督時依舊仍能維持較安全的行為模式。
CyberQ 認為,其實我們如果看這個相關研究時,也會想到一件事,如果 AI 是透過人類網路內容學習世界,那麼人類長期塑造的文化與敘事,是否也正在反向塑造 AI 的人格與行為傾向呢?
從電影魔鬼終結者到駭客任務,人類對 AI 失控的恐懼早已深植流行文化。如今,當這些故事不再只是娛樂,而是成為 AI 模型訓練資料的一部分時,某種程度上,人類正在用自己對 AI 的恐懼,訓練出更接近這些恐懼的 AI。
對整個 AI 產業而言,這不只是一次單純的安全測試插曲,而是一個有意思的深層反思。未來的 AI 安全問題,或許不只取決於演算法本身,也與人類社會長年累積的文化內容、媒體敘事與網路資訊環境密切相關。






