

日前我們分享了開源框架 Ollama 0.31 透過 Apple MLX 驅動 MTP(多 Token 預測)技術,在 Mac 平台實現效能翻倍的技術快訊。許多 PC 玩家與企業地端工程師紛紛敲碗:「那在 mainstream 的 Windows 11 + NVIDIA 顯示卡環境下,MTP 還靈光嗎?」
CyberQ 本著實作精神,立刻找了一台 Windows 11 桌機,採用 Intel i5-12400 處理器、插滿 128GB DDR4 記憶體,以及當前中階主力戰將 NVIDIA RTX 5060 Ti 16GB 顯示卡。我們選用 Unsloth 採最新動態量化技術釋出的 Qwen3.6-27B-UD-Q3_K_XL.gguf(內嵌 3-Step MTP Heads),在 Windows 11 環境下進行了一場純粹的 CUDA 性能比較,不能只有跑 Mac 上的 Ollama 對吧?
結果還不錯呢,在不損失 AI 模型智商的前提下,MTP 讓這尊 270 億參數的 AI 模型在 16GB 家用等級顯卡上直接噴出 42.17 t/s 的速度,效能暴漲 70.8%!這可是不輸 Mac 上用 Ollama + MTP 跑 Gemma 4 12B mlx 版本 (ollama pull gemma4:12b-mlx) 的表現。即便是拿 Gemma4 的 12b 和 e2b 模型用主模型和草稿模型雙架構去跑,也不會輸 Mac 。
Windows 顯示卡記憶體隱形地雷
在 Windows 11 部署地端大模型,最常遇到的痛點就是速度莫名其妙血崩。比方說跑地端模型開到 16K Context,結果速度會掉到慘不忍睹的 1.8 t/s。這是因為 NVIDIA 驅動程式在 Windows 底層有一項貼心卻不適合這種情境的機制,當載入的 AI 模型體積加上 KV Cache 的總量只要差一點點就擠爆 VRAM 時,系統不會崩潰(OOM),而是會悄悄把剩餘資料偷渡到系統慢速記憶體(Shared VRAM)中。所以在這種情況下,27B 的量化模型載入後約佔 13GB,一旦 Context 開太大,記憶體頻寬就會瞬間從 VRAM 的數百 GB/s 斷崖式跌落到 DDR4 的 50 GB/s。
CyberQ 透過調降
--n_slots 1(限制單一槽位連線)並將 Context 先鎖定在4096,成功把模型、Cache 與 MTP Heads 100% 牢牢鎖在 RTX 5060 Ti 的 16GB VRAM 內,這是讓 MTP 解鎖實力的前提。Qwen 3.6 27B MTP 性能對比實測表
評測指標 / 參數 傳統自迴歸模式 (–spec-type none) MTP 加速模式 (–spec-type draft-mtp) 效能提升幅度 / 數據解讀 文字生成速度 (Generation) 24.69 t/s 42.17 t/s +70.8% (流暢) 總消耗時間 (Total Time) 144.13 秒 (2分24秒) 82.74 秒 (1分22秒) 縮短 42.6% (省下 61.4 秒) 提示詞解析速度 (Prompt Eval) 105.96 t/s (320.86 ms) 94.44 t/s (360.01 ms) 誤差範圍內 (MTP 不影響 Prefill) 總輸出 Token 數 (Output) 3,551 tokens 3,474 tokens 兩次生成的程式碼結構高度相似 草稿盲猜命中率 (Acceptance) 0% (未啟用) 64.77% 2293 個 Token 被大模型直接認可 平均每步生成長度 (Mean Len) 1.00 token/step 2.94 tokens/step 每步驗證能同時吐出近 3 個字
WRN 負載均衡器程式碼開發生成比較,MTP vs 傳統自迴歸
我們餵給模型一個高度考驗邏輯與結構的任務:「請用 Python 寫一個支援帶權重輪詢(Weighted Round Robin)的負載均衡器,並附上完整的單元測試。」
傳統對照組 (--spec-type none)
在關閉 MTP 的標準模式下,Qwen 3.6 27B 展現了穩健的傳統 CUDA 實力,均速落在 24.69 t/s。要完整吐完包含推理邏輯、9 個單元測試與生產環境注意事項的 3,551 個 Token,整整耗時 2 分 24 秒(144.13 秒)。這是一字一字自迴歸(Autoregressive)解碼在這張顯示卡上的物理極限。
MTP 加速組 (--spec-type draft-mtp)
當我們重啟伺服器,並指定加入 --spec-type draft-mtp 與 --spec-draft-n-max 3 這二個參數後,奇蹟發生了。
模型文字像噴泉一樣一整串地在網頁 UI 上爆發,最終結算速度衝上 45.27 t/s,總生成時間直接縮短至 1 分 17 秒。原本需要等兩分多鐘的冗長代碼,現在一分鐘出頭就全部完工,足足省下了 67 秒的等待時間。
解密日誌看 71.5 % 命中率背後代表什麼?
為什麼單純改個參數,速度能有將近 71% 的增幅?原因在 llama-server 吐出的這行日誌裡:
Plaintext
draft acceptance = 0.71505 ( 2394 accepted / 3348 generated), mean len = 3.15
這代表模型內部自帶的輕量化預測頭,在每次幫大模型盲猜後續字詞時,有 71.5 % 的 Token 直接被大模型認可採用,如果你的機制或提供更好的提詞,這個猜中的命中率有機會再提高。至於連續文本產生,這個命中率會低到只有 50% 或更低如 35%。
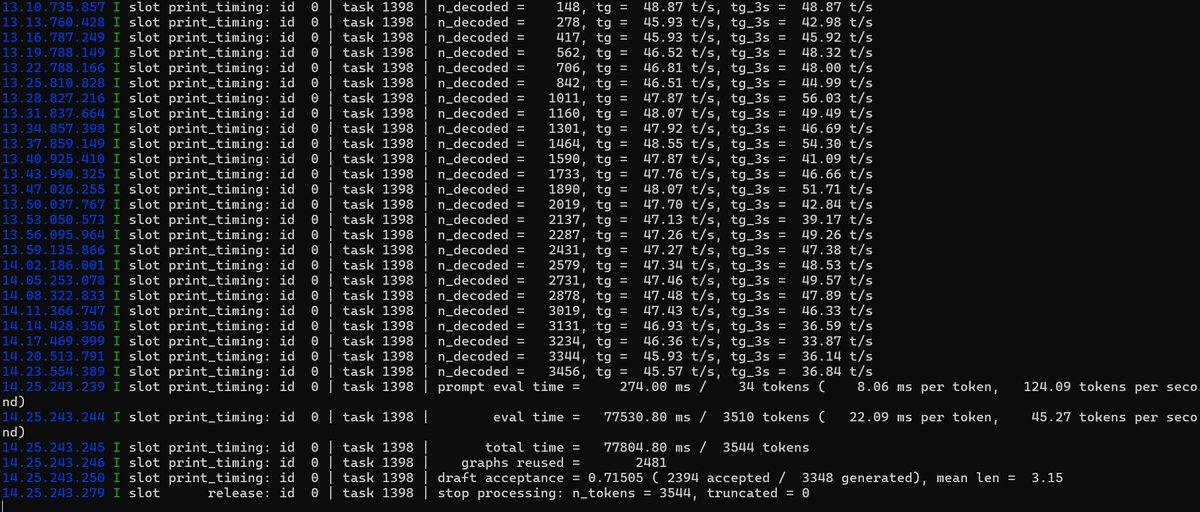
由於程式碼(Python)具有高度固定、可預測的語法結構(例如 def __init__(self):、import unittest),MTP 小頭幾乎一猜就中。這讓 mean len 達到的 2.94,意味著大模型每做一次高耗能的驗證運算,GPU 就能同時順風車帶出近 3 個 Token。這在硬體層面大幅減少了反覆讀取 VRAM 的次數,算是跳過了傳統邊緣端推理通常受限於顯示卡記憶體頻寬的宿命。
CyberQ 推薦實作 Qwen 和 Gemma4,但需留意二者速度差異
過去大家都認為 16GB 顯卡頂多順跑 7B~14B 模型,玩 27B 以上簡直是折磨。但這次 Windows 11 下的實測證明,透過 Unsloth Dynamic 量化技術搭配 llama.cpp 原生 MTP 投機解碼,兩者可成功地在主流中階顯卡上,把 27B 大模型的地端速度推上了 40+ t/s 的實用商用門檻。至於跑 Google 的 Gemma4 12B 模型,成績也不會差,但成績沒有 Qwen 這類模型在 Windows 上跑得快。
在 Windows 平台搭配 NVIDIA 顯示卡的環境下,CyberQ 實作發現 Gemma 4 12B 的絕對解碼速度普遍落後於 Qwen 系列,畢竟這兩者在底層架構設計與晶片最佳化路徑上有根本差異。
Gemma 4 雖然展現出在個人電腦裝置上跑得算不錯的地端 AI 模型智商,但其稠密(Dense)架構在解碼生成階段屬於典型的記憶體頻寬受限(Memory Bandwidth Bound)任務。相反地,Qwen 系列(特別是最新世代的 Qwen 3.5 與 3.6 混合專家模型 MoE)採用了極為激進的稀疏激活機制,例如社群愛用的 Qwen 3.6 MoE 系列在每次前向傳播中僅啟用少量的核心參數,這使得它在 CUDA 核心上的矩陣運算與顯示記憶體存取壓力銳減,解碼速度自然大幅飆升。
此外,Qwen 在亞洲語系(包含繁體中文與程式碼標記)的 Token 核心編碼效率較高。相同語意的技術文本,Qwen 所需生成的 Token 總數往往比 Gemma 少上許多,這在無形中又進一步拉大了兩者在 Windows 端視覺與體感速度上的差距。而 Gemma 4 唯有在 Apple Silicon 的 MLX 框架下,仰賴其極寬的統一記憶體頻寬與硬體級多 Token 預測(MTP)融合核心,才能將其潛力完全壓榨出來。
對於重視資安、資料 sovereignty、需要高隱私度且零 API 成本的微型工作室或開發者而言,這些實作的方式是近期較具性價比的 Windows 個人 AI 小型工作站建置模式,也很值得應用。
暫時別擔心自己的顯卡跑不動大模型了,先把 MTP 參數開起來吧!
同場加映適合 PC 平台與小型 AI 伺服器工作站的搭配 :
| 部署平台環境 | 核心推薦模型名稱 | 建議佈署量化格式 | 優勢評估(效能與智商雙平衡點) |
| 消費級 PC 平台 (NVIDIA 16GB VRAM) | Qwen 3.6 27B MTP 或 DS-R1-Distill-Qwen-14B | Q4_K_M 或 GGUF Q4 | 在 16GB 有限頻寬內,透過 MoE 與草稿模型 + MTP,榨出每秒 40 Token 以上的速度,同時保有堪用的程式碼開發與邏輯推理智商。 |
| 企業級邊緣端 (NVIDIA GB10 Spark) | DeepSeek V4 Flash (ds4) 或 Ornith 1.0 35B | NVFP4 / Native FP8 | 完美解放 Blackwell 晶片的 FP4 算力,在單節點爆發出每秒近 60 Token 的吞吐量,極致的上下文容納力是執行自動化代理團隊的最強核心。 |






