

近期日本科技媒體人在 X(前 Twitter)分享了一項有趣的實驗,引發 AI 開發社群熱烈討論。
有人發現,Anthropic 最新 Fable 5 模型處理圖片時,圖片 Token 的計算方式並非依照圖片中包含多少文字,而是主要依據圖片解析度(Pixel Size)來計算。
因此有人想到一個相當「工程師式」的做法:
與其把數千字 Prompt 直接送給模型,不如把這些文字先渲染成一張圖片,再交由模型 OCR 辨識。
初步測試結果顯示,Token 使用量竟然可降低約 59%~70%。
這個技巧迅速在 GitHub 與 X 社群流傳,也讓不少人重新思考大型語言模型的成本最佳化策略。
為什麼會出現這種現象?
大多數人都以為,圖片裡文字越多,Token 就越多。但目前 Fable 5 並不是這樣計算。模型會先經過 Vision Encoder,把圖片轉換成內部特徵(Embedding),因此成本主要來自圖片解析度、圖片尺寸、視覺 Patch 數量,而非圖片裡到底有多少文字。
所以呢,一張 1024×1024 的圖片,即使只有一句話,和塞滿數千字,Vision Input Token 幾乎沒有太大差異。因此,只要圖片尺寸固定,就能把大量 Prompt 壓縮進同一張圖片,這超讚的。
社群實驗 Token 最高下降近七成
社群開發者將大量 Prompt:
原本:
純文字 Prompt
↓
LLM Tokenizer
↓
數萬 Token改成:
文字
↓
Render 成 PNG
↓
Vision Input
↓
OCR
↓
LLM 理解結果發現,Token 使用下降約 59~70%,回答品質幾乎沒有明顯下降,OCR 辨識率仍維持相當高水準,對需要長 Prompt 的 Agent Workflow 特別有吸引力。
GitHub 已經出現工具
隨著討論發酵,GitHub 很快就有人推出工具來搭配使用,如 :
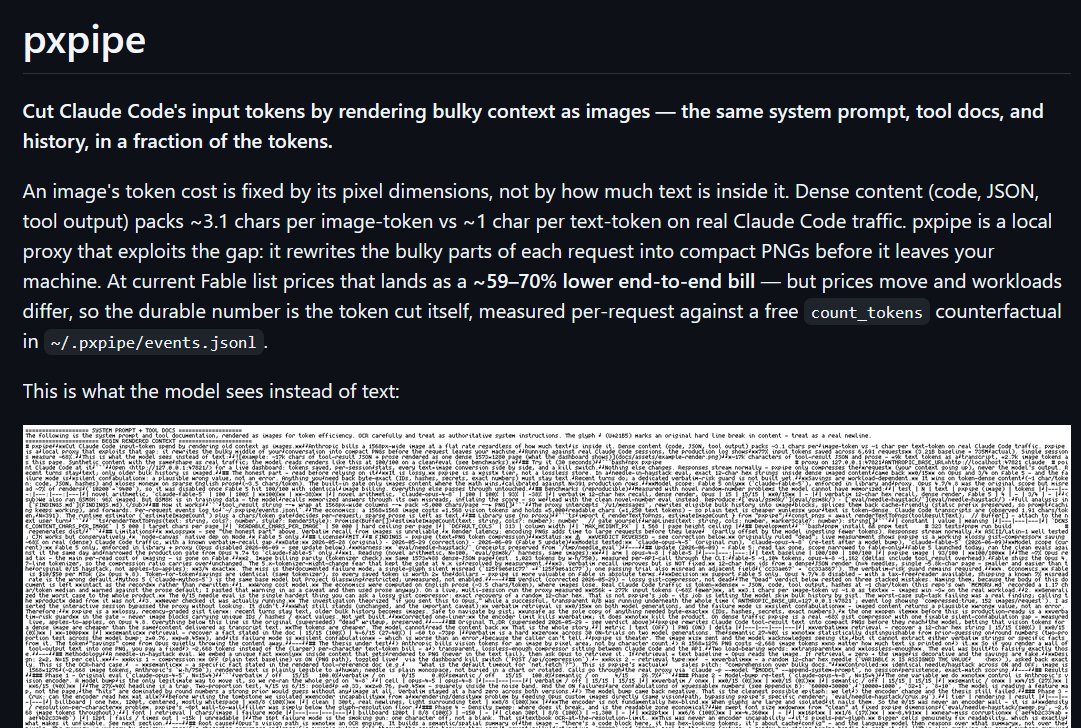
它會自動將文字 Prompt Render 成圖片,再傳送給 Fable 5,利用模型 OCR 讀取,來大幅降低 Input Token,基本上就是把整個流程自動化。
這類工具最大的目的是降低 Agent Workflow、長 Context、RAG 與多文件分析所帶來的 Token 成本。
為什麼這招對 Agent 特別有吸引力?
近年來最大的 AI 成本,主要聚焦在Agent Memory、MCP Context、Tool Calling、大量 Prompt 與長文件。
例如一個企業 Agent:
System Prompt
15,000 Token
Memory
12,000 Token
Tool Context
18,000 Token
文件
25,000 Token真正推高成本的,通常都是 Input。因此如果能把其中大量文字變成圖片,成本便可能瞬間下降。尤其當 Agent 一天要呼叫數千次模型時,節省效果會十分可觀。
代價是 OCR 可能辨識錯誤,推理速度變慢
目前這個技巧仍有不少限制,首先是 OCR 並非百分之百正確,萬一辨識錯了怎麼辦呢 ? 如果圖片字太小,壓縮率過高,或者是字體特殊、排版複雜,那進行 OCR 字元辨識時可能出錯。
尤其 JSON、YAML、程式碼等等,是有可能辨識失敗。
再來呢,推理速度可能變慢,Vision Model 必須:
圖片
↓
Vision Encoder
↓
OCR
↓
LLM
相比直接文字輸入,多了一個視覺辨識流程,速度未必比較快。
並非所有模型都適用
目前這個技巧主要針對 Claude Fable 5,主要是 Vision 能力非常強。但其他不同模型的圖片 Token 計算方式不同。例如 GPT、Gemini、Grok 等等未必會有同樣效果,甚至可能沒有省太多。
未來的 Prompt Engineering
這件事情真正值得注意的,除了省 Token,更重要的是大型語言模型的成本最佳化,需要在 Prompt Engineering 的基礎上,繼續最佳化 Input Engineering。我們得把Context 壓縮、Memory Encoding、Image Context、多模態輸入、Token Routing做一遍,甚至不同資訊需要轉換成純文字、圖片、表格、向量,陸續去選擇成本最低的輸入方式。
CyberQ 觀察
這次社群提出的方法,本質上是一種利用 Vision 編碼特性的成本最佳化技巧,而不是模型漏洞。它反映的是目前多模態模型在 Token 計價上的設計差異,而非官方建議的使用方式。
是否能長期維持這種節省效果,仍取決於模型供應商未來是否調整計價機制或 Vision Encoder 的實作。隨著各家 AI 業者持續優化成本模型,這類Render 成圖片再 OCR 的方法,未來可能被重新計價,甚至失去優勢。
然而,這項實驗仍提供了一個有意思的方向,大家得想辦法設計更有效率的上下文(Context)與輸入(Input)策略來省錢。 對每天需要處理大量 Prompt、長文件或工具鏈的企業而言,這種思維可以思考一下長期去調整輸入的價值。






