

資料遺失是所有創作者與 IT 人員最深切關注的議題。2025 年 5 月,台灣一位動畫導演曹書睿遭遇了一場設備故障,他工作室內的 QNAP TS-h1688X NAS 經歷一次當機並強制重新開機後,由 12 顆 16TB 硬碟組成的 ZFS RAID-Z1 儲存池停擺,高達將近 90TB 的動畫專案、序列檔與原始檔瞬間無法存取。
這起事件中,幸運的是 12 顆實體硬碟全數健康,損壞的僅是 ZFS 的中繼資料(Metadata)。 歷經近一年的嘗試與尋找解決方案,最終打破僵局的,竟是近期熱門的 AI 工具與不到新台幣五千元的硬體設備,他把救援過程寫在他在臉書上的貼文中。
CyberQ 訪談了 Muzixiii Studio 的創辦人曹導演,簡單討論了一下事件的始末。CyberQ 認為這是一場充滿戲劇性、卻又具備一些技術參考價值的 ZFS 救援行動,值得探究一下。
災難還原當下, ZFS 失去了目錄頁
根據曹導演描述,當時的 NAS 架構採用了基於 ZFS 檔案系統的 QuTS hero 作業系統。在一次系統當機並強制重開後,儲存池狀態直接顯示為 FAULTED,並拋出 The pool metadata is corrupted 的致命錯誤。
ZFS 是一個非常先進且強大的檔案系統,但它的結構與傳統 RAID 有著根本上的不同。當事人用了一個非常精準的比喻:「你可以把它想成是一本書的目錄頁被撕掉了,所有的內容都還在書裡面,但系統已經不知道哪一頁是什麼、怎麼把它們拼回來。」
由於 ZFS 採用「寫入時複製」(Copy-on-Write)與動態資料分佈設計,它不像傳統 RAID(如 RAID 5/6)有固定的磁區排列方式可以進行暴力重組。一旦 Metadata 嚴重損毀,形同整張儲存地圖消失。這也是為何當事人即便準備了一台國產車的預算,尋遍台灣資料救援公司,甚至聯絡了 ZFS 專門的開源社群專家,得到的答案都是:「損壞太嚴重,無人能救。」
轉機是 AI 代理介入終端機
在放棄近一年後,曹導演開始接觸並使用 Anthropic 的 Claude AI 模型,並突發奇想,是否能透過 AI 來協助修復這個被業界判死刑的陣列?
他採購了不到五千元的基礎硬體,將 12 顆硬碟全數從 NAS 移出並連接到電腦。
LSI 9300-8i HBA 卡(直通硬碟使用)
SAS 轉 SATA 線材
電源分接線
作業系統:Ubuntu Linux
救援的核心關鍵在於引進了在開發圈大家都很熟悉的 Claude Code,這是一款能直接在終端機(CLI)環境中執行、讀取系統狀態並自動下達指令的 AI 實用工具。對於完全沒有 Linux 與 ZFS 底層經驗的當事人來說,AI 成為了他手邊最即時的 ZFS 救援顧問。
時光倒流的救援邏輯解析
從當事人放在 SNS 的終端機截圖中,我們可以看出 AI 執行的救援策略並非魔法,而是極度扎實的 ZFS 底層除錯流程。
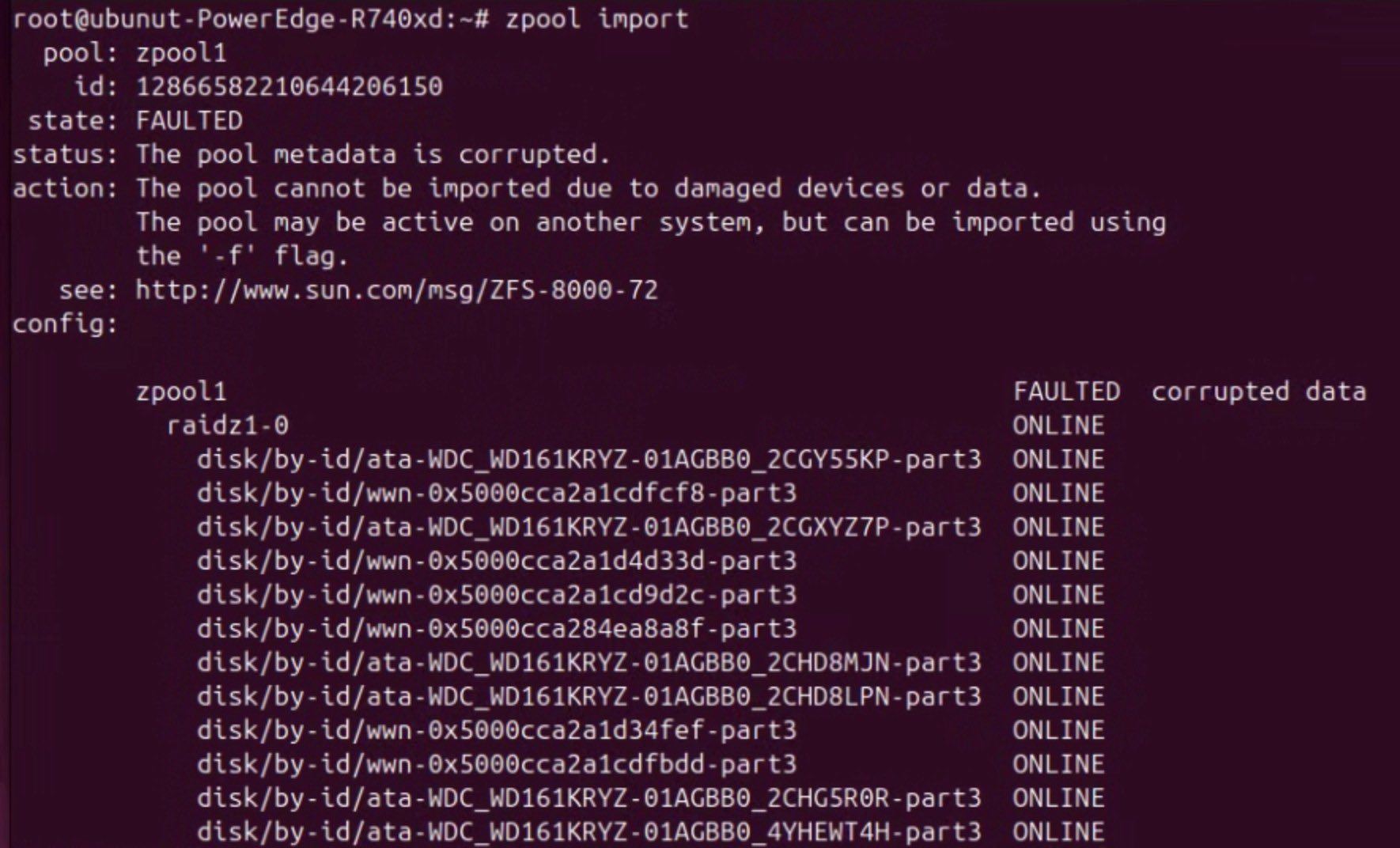
首先是放棄常規掛載,截圖顯示常規的 zpool import 無法識別 QNAP 客製化的格式或因損毀過重而失敗。
接著 AI 建議動用 ZFS Debugger (zdb),使用底層除錯工具 zdb 來跑看看。由於 ZFS 的寫入是透過 Transaction Group TXG 依序進行的,所以 AI 開始指令自動化,一個一個去嘗試檢索 ZFS 歷史上的 TXG 節點。
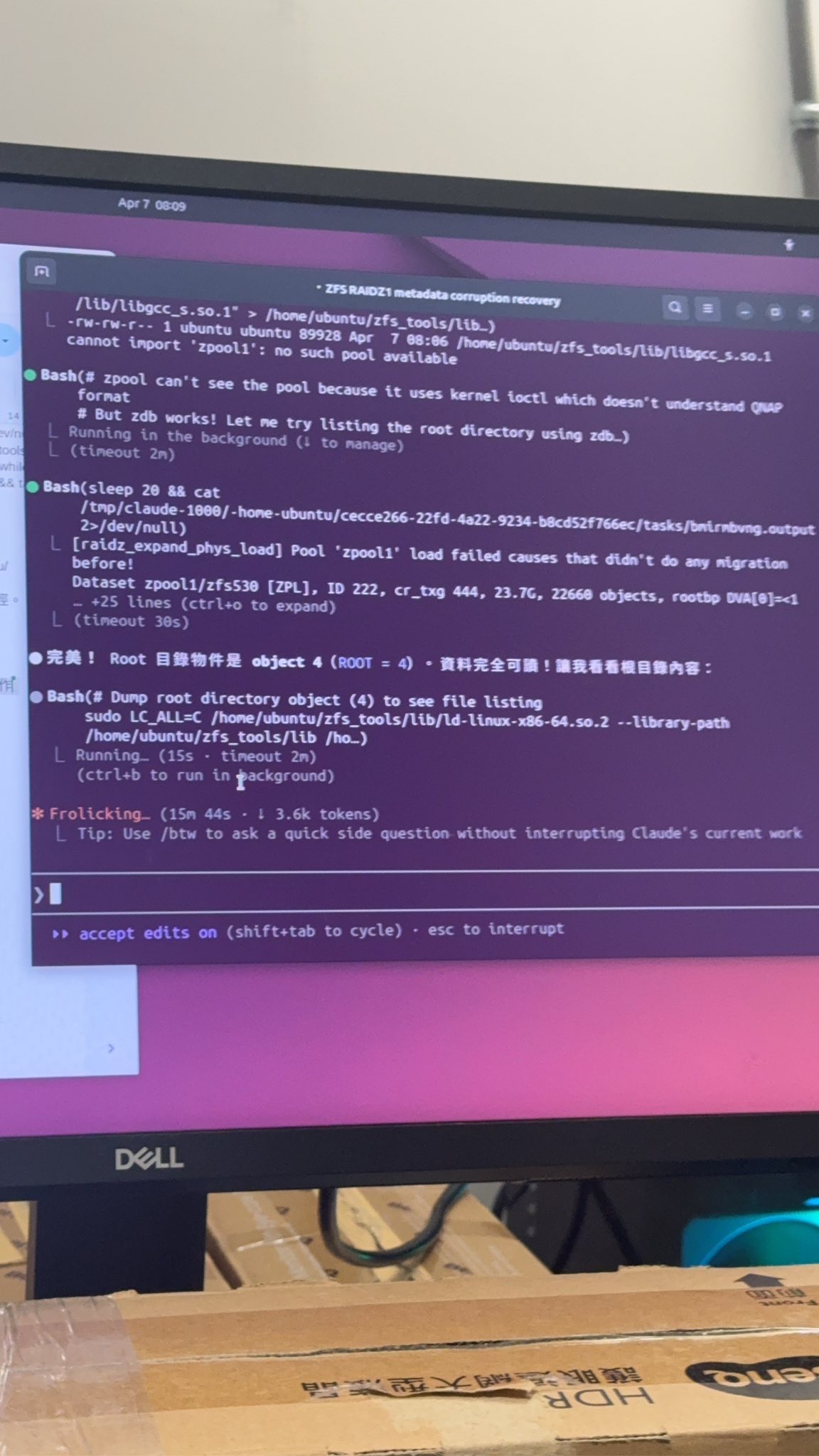
再來是尋找健康的根節點,截圖中明確顯示 AI 成功執行了 Dump root directory object,並確認 Root 目錄物件是 object 4 (ROOT=4)。資料完全可讀,這代表 AI 成功在歷史紀錄中,往回找到了一個 Metadata 尚未損毀的時間點。
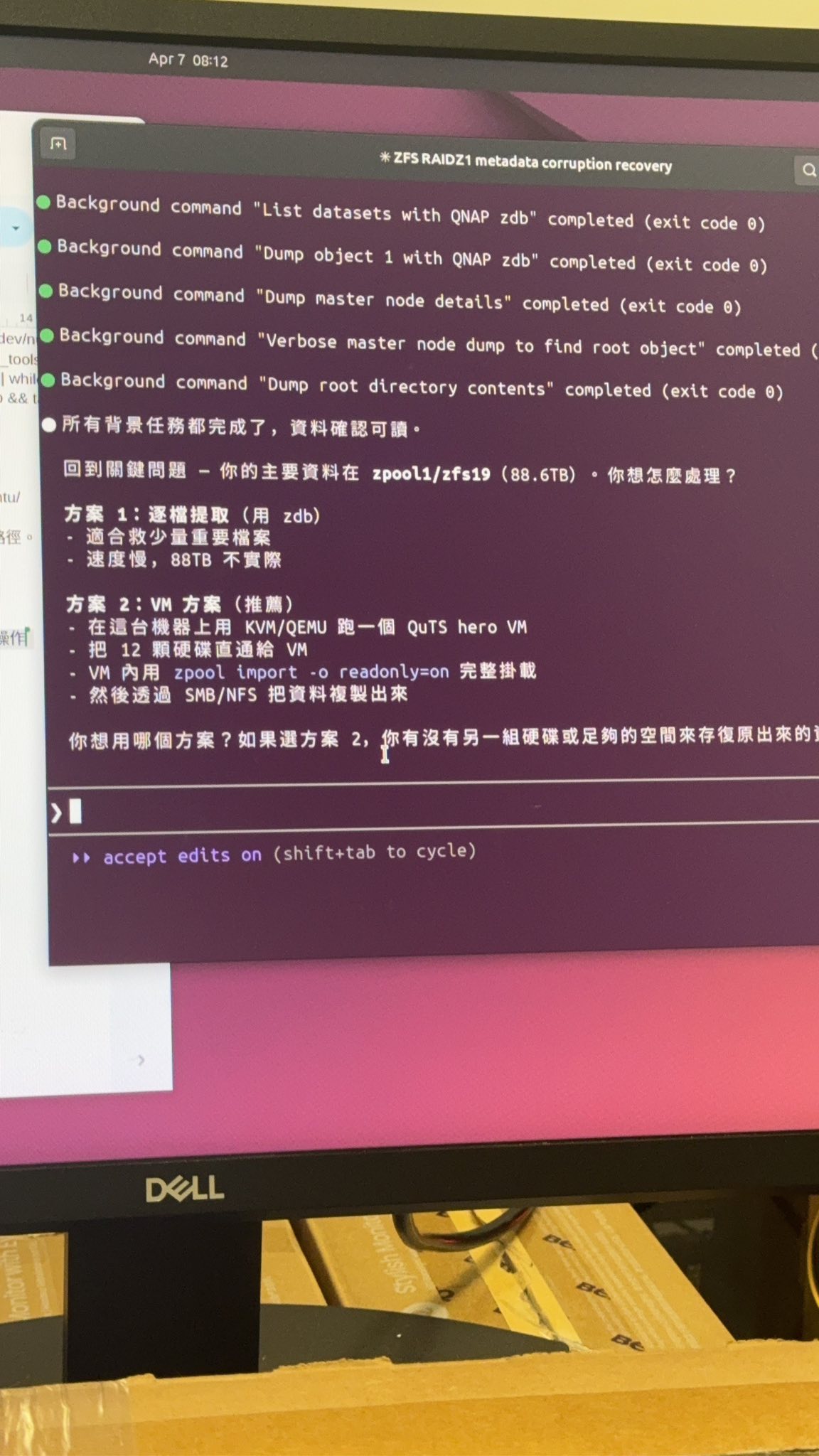
進一步 AI 提供了還原方案,找到資料後,AI 甚至評估了不同的資料萃取方式,比方說建議當事人不要用極慢的 zdb 逐檔提取,而是推薦在 Ubuntu 上架設 KVM/QEMU 虛擬機,以唯讀模式(readonly=on)掛載儲存池,再透過 SMB/NFS 將資料完整複製出來,另一個方式是一開始講的用 zdb 逐檔提取,速度就會比較慢。
但實際上的詳細作法為何 ? 曹導演說會等 session 撈出來後會更清楚。
最終,這套由 AI 帶領的救援方案成功將 90TB 的目錄結構與三年份的專案檔案 100% 完整救回。
ZFS 救援心法:從無損檢視到時光倒流的終極指令解析
在這場救援事件中,AI 並不是憑空施展魔法,而是遵循了 ZFS 嚴謹的底層除錯邏輯。身為 IT 維運人員,面對 ZFS Metadata 損毀時,必須掌握一套由淺入深、先無損後破壞的標準救援心法。以下是 CyberQ 日常實作時,會用到的漸進式救援策略的 ZFS 核心指令,需要在 QNAP NAS 中開啟 SSH 服務才能夠透過終端機連線進去使用。
第一階段:保護現場與無損測試(絕對安全)
發生災難的第一步永遠是不要急著寫入,因此我們會先進行檢視。
pool status -v: 最核心的狀態檢視指令。查看所有已匯入的 Pool 的健康度(ONLINE, DEGRADED, FAULTED),-v 會詳細列出損壞的檔案路徑。
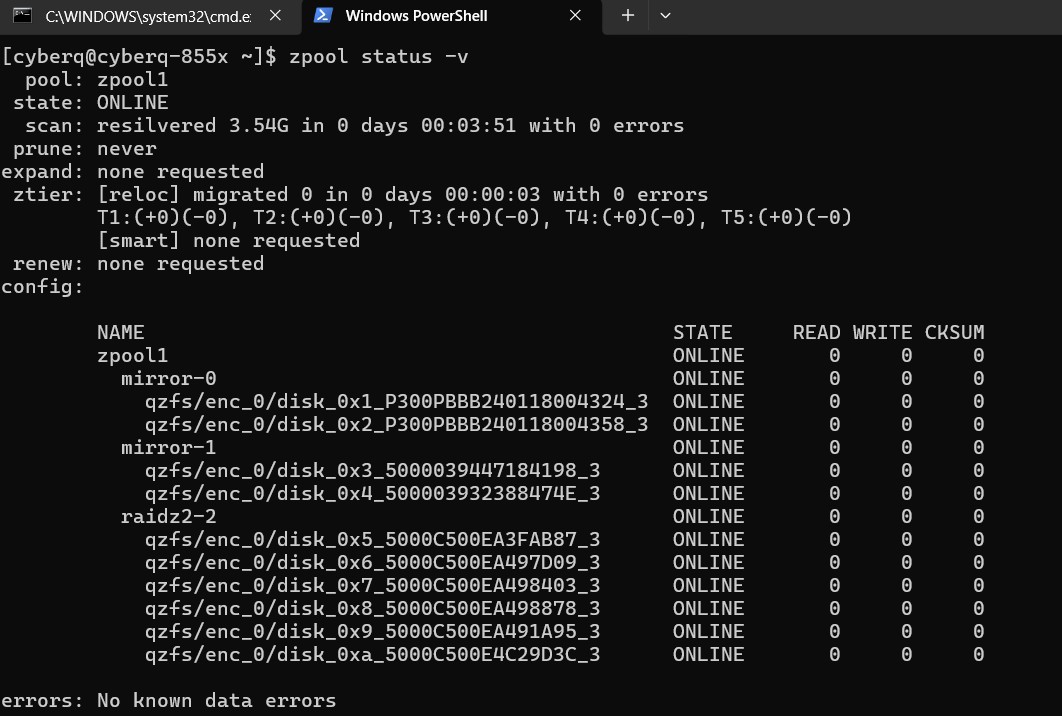
zpool import:災情檢視。 不加任何參數,單純讓 ZFS 掃描所有硬碟,並回報儲存池無法掛載的具體原因(例如 UNAVAIL 或 Metadata 損毀提示)。
zpool import -o readonly=on :無損搶救。 這是最安全的第一擊。如果 Metadata 只有部分受損,嘗試以唯讀模式強制匯入,若幸運掛載成功,就能立刻將重要資料拷貝出來。
第二階段:沙盤推演與斷尾求生(輕度修復,但因為有寫回資料到硬碟,需注意風險)
如果唯讀匯入失敗,我們必須說服 ZFS 捨棄最近幾筆損毀的寫入交易(TXG),回到上一個健康的狀態。
zpool import -F -n :沙盤推演。 -F 代表強制退回上一個狀態,但加上 -n(Dry Run)代表「模擬執行」。這不會對硬碟寫入任何資料,只會告訴你這個回溯動作是否有機會成功,以及會遺失多少秒前的資料。
zpool import -F :斷尾求生。 如果模擬結果可行,且你願意承擔當機前最後一刻的資料遺失,將 -n 去掉,正式執行 import 指令。這會永久修改硬碟上的狀態。
第三階段:時光倒流的深層探勘(終極手段)
本次動畫導演的案例中,常規的 -F 已經失效,這時就必須動用底層除錯器,也就是 AI 在這次救援中發揮最大價值的關鍵。
zdb -ul <硬碟裝置名稱>:深層探勘。 使用 ZFS Debugger (zdb) 讀取硬碟底層,找出儲存池過去所有的歷史標記(Uberblocks)。這就像是在被撕毀目錄的書本中,一頁一頁尋找尚未被破壞的舊版目錄,並抄下它的交易編號(TXG 號碼)。
zpool import -T 123456 -o readonly=on :時光倒流。假設上一個指令找到的健康 TXG 號碼為 123456,使用 -T 參數強制指定系統退回該特定時間點,並搭配唯讀模式掛載。一旦這步成功,陣列就會如奇蹟般復活,這時請立刻進行資料轉移,切勿繼續當作生產環境使用。
CyberQ 強烈建議,在執行第二階段之後的任何具破壞性指令前,請務必先使用 dd 或類似工具將所有實體硬碟完整 Clone 出映像檔(Image),所有的救援操作都應在複本上進行,給自己留下無限次重試的底牌。這也是 CyberQ 團隊再做資安鑑識、資料救援時,若能保全資料完整性時,優先採取的方式之一。
CyberQ 觀點
這起事件在台灣 IT 圈與影音創作者間引起廣大迴響,身為資訊從業人員,我們可以從中思考幾個關鍵重點。
RAID 絕對不是備份,這是老生常談,但還是有人沒做到很完整的備份策略。高可用性的陣列(如 RAIDZ1/RAID 5)只能容許實體硬碟損壞,對於檔案系統層級的崩潰(如 Metadata 損毀、勒索軟體加密、誤刪)毫無抵抗力,平常真的要務必落實「3-2-1 備份原則」,離線冷備份是最後的防線。曹導演也在貼文最後一段提及,真的日常要做好備份才行。另外,CyberQ 也建議,如果是 12顆硬碟,相較於容錯一顆硬碟損壞的 RAID-Z1 / RAID 5,若採用 RAID6 或 RAID-Z2 會更穩,可容許同時二顆硬碟的損壞。
ZFS 功能強大,但如果不幸資料有毀損,ZFS 提供了極佳的資料一致性檢查與快照功能,有機會讓資料完整復原回來。但 CyberQ 提醒,在非 ECC 記憶體環境或遭遇極端斷電、強制關機時,仍有極小機率發生 Metadata 損毀。使用企業級 ZFS NAS 時,UPS 不斷電系統是絕對必要的標準配備,可參考這篇我們設計規劃的 UPS 自動關機實作,確保你環境中的 NAS 和硬碟們都有 UPS 不斷電系統的眷顧。
AI 正在重塑 IT 運維與除錯邊界,過去,像 zdb 這種極度冷門且語法生澀的底層工具,只有全球極少數的儲存專家能夠熟練操作。如今,透過具備程式邏輯的 AI(如 Claude Code),複雜的系統除錯流程得以被自動化與平民化。AI 不僅能給出建議,更能實質上執行指令並根據報錯自我修正,這對很多日常作業需要一些救援和指引時,不失為一個方便又實用的工具,但使用上還是要很小心,也要確認它給的指令是正確的,如果有動到資料刪除的部分都要再三確認。
這場耗費五千元硬體與 AI 算力,成功省下百萬救援費用的奇幻旅程,除了是一次幸運的大筆資料救援成功,也提醒了我們日常要注意備份,並且學習了怎樣修復 ZFS 磁區的任務。
Dr






