

Cloudflare 在今天一度又出現當掉的情形,不同節點回報異常,CyberQ 綜合 Cloudflare 官方通告、社群反應以及全球主要服務狀態的分析:
12/5 Cloudflare 事件時間軸 (台灣時間)
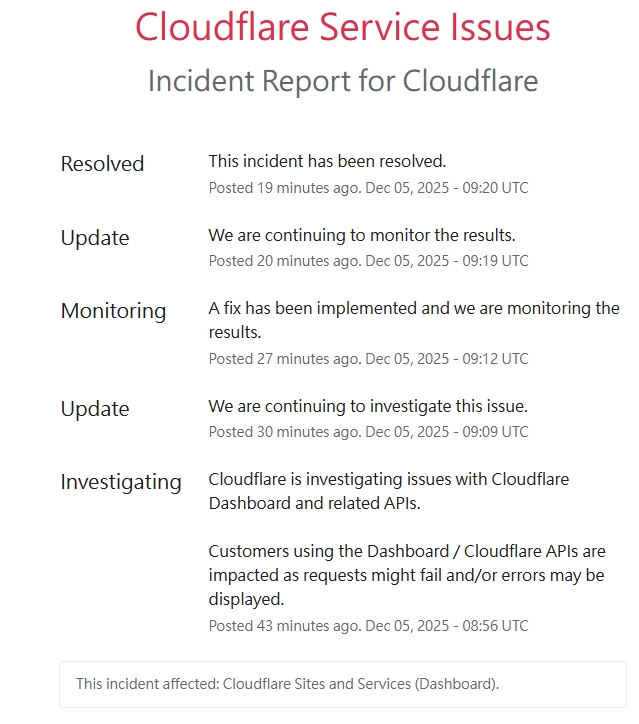
16:56 (08:56 UTC) – [確認異常] Cloudflare 官方正式確認正在調查 Cloudflare Dashboard(儀表板)及相關 API 的問題。此時用戶開始回報請求失敗或出現錯誤訊息。
17:09 (09:09 UTC) – [持續調查] 官方更新狀態,表示調查仍在進行中,尚未定位到確切修復方案。
17:12 (09:12 UTC) – [實施修復] 僅僅過了 3 分鐘,官方宣佈已實施修復措施(Fix implemented),並進入結果監控階段(Monitoring)
17:20 (09:20 UTC) – [標記已解決 官方宣佈已解決。(Resolved)
黃金 16 分鐘(The 16-Minute Crisis): 從官方承認問題(16:56)到實施修復(17:12),中間僅間隔 16 分鐘。這極短的處理時間強烈暗示了故障原因可能是一次「錯誤的配置推送(Bad Config Push)」或「程式碼部署失誤」。這類問題通常在回滾(Rollback)版本後能迅速恢復,與硬體故障或遭受攻擊需要長時間清洗的情況截然不同。
API 服務的「短暫陣痛」: 雖然 16 分鐘對一般瀏覽網頁的用戶來說可能只是一瞬間的卡頓,甚至沒感覺;但對於每秒都在呼叫 API 的自動化程式(如 Shopify 後台、CI/CD Pipeline、監控機器人)來說,這 16 分鐘是紮紮實實的「服務中斷(Downtime)」。這解釋了為什麼社群上會瞬間爆量抱怨,隨後又快速平息。
危機解除,進入觀察期: 狀態改為「Monitoring」通常表示系統指標已恢復正常,運維團隊正在觀察是否會有殘留的錯誤率(Error Rate)。對於使用者來說,目前 Dashboard 登入與 API 呼叫應已恢復正常。
根據這次 Cloudflare 官方事件報告(Incident ID: lfrm31y6sw9q),CyberQ 分析這份報告,今天發生的核心問題並非單純的「網路連線」故障,而是控制平面(Control Plane)的異常。以下是針對這份官方通告的詳細分析,以及這對用戶意味著什麼:
官方通告細節分析
事件名稱: Cloudflare Dashboard and Cloudflare API service issues(Cloudflare 儀表板與 API 服務異常)
發生時間: 2025 年 12 月 5 日,08:56 UTC(台灣時間 16:56,美東時間 03:56 AM)。
官方說明: Cloudflare 確認當時正在調查儀表板(Dashboard)與相關 API 的問題。用戶在嘗試登入管理介面或透過程式碼(API)呼叫 Cloudflare 服務時,會遭遇請求失敗或錯誤訊息。
具體細節: 官方指出部分服務出現間歇性影響。值得注意的是,這一天 Cloudflare 在全球多個節點(包括華沙、里斯本、芝加哥、卡加利等)正好安排了預定維護 (Scheduled Maintenance)。
潛在關聯: 雖然官方通常將「維護」與「故障」分開,但密集的維護時段(特別是涉及流量重新路由時)有時會導致終端用戶感受到延遲增加或短暫的連線錯誤(如 500 錯誤),這可能解釋了為何用戶端感覺是「故障」。
2、社群反映 (Twitter/X, Reddit)
用戶感受: 社群媒體上確實湧現了許多用戶抱怨「Cloudflare 又掛了」。由於 11 月 18 日才剛發生過一次大規模全球當機,用戶對於這次的異常特別敏感,普遍反應是「怎麼又來了?」以及對網路基礎設施過度集中的擔憂。
具體災情:
Reddit 上有討論串指出電子商務平台(如 Shopify)似乎再次受到影響。
部分開發者與網站管理員回報遇到間歇性的連線超時與 API 錯誤。
許多用戶反映在訪問不同網站時出現了 Cloudflare 經典的錯誤頁面,雖然不像上次那樣全面癱瘓,但範圍涵蓋了多個應用程式。
3、各大服務的實際影響狀態
與 11 月 18 日那次導致 ChatGPT、Discord、Canva 等服務全面停擺的災難性故障相比,這次 (12月5日) 的影響範圍相對較小且較為零星:
受影響服務: 主要是依賴 Cloudflare 進行流量代理的特定網站和應用程式。媒體報導指出有「多個應用程式」受影響,其中 Shopify 商店的訪問問題被社群多次提及,這直接影響了電商交易。我們可以更精準地還原當時狀況:
為何 Shopify 等電商受影響? 電商平台高度依賴 API 進行後台數據交換。Cloudflare API 的故障會導致這些平台的後端邏輯無法執行(例如結帳流程中的安全驗證),而不僅僅是網頁打不開。
為何社群反應是「又掛了」? 對於維運人員(DevOps)和開發者來說,API 壞掉等同於服務不可用(CI/CD 流程中斷、無法部署新版、無法監控),因此技術社群的反應會比一般大眾更為激烈。
12 月 5 日的事件是一起典型的「控制層(Control Plane)故障」。 雖然官方定調為「服務降級」,但對於依賴 Cloudflare API 運作的現代化網路服務(如 SaaS、電商平台)而言,這就是實質上的服務中斷,這也是為何美國部分依賴自動化架構的服務會出現功能異常的原因。
主要大廠狀態: 像 ChatGPT、Discord 或 X (Twitter) 等超大型服務似乎未出現像上次那樣的「全面無法使用」災情,或者影響時間極短。這次出現「部分區域」或「部分路由」的性能下降,但還沒有到全球性的斷網,只有部份網站的服務被迫中斷,這是因為不同區的 Cloudflare 節點所致。
CyberQ 觀察,這次事件在技術層面上被定調為「內部服務降級」與多地「預定維護」的疊加效應。
對一般用戶而言: 體驗是「網路變慢」或「部分網站打不開」,出現一大堆 500 錯誤訊息。
CyberQ 認為,儘管嚴重程度遠低於 11 月 18 日的全球大當機,但這再次提醒了我們,雖然 Cloudflare 提供了強大的防護與加速,但其密集的維護排程與單點故障風險,仍是依賴該服務的企業(特別是電商)需要評估的營運風險成本。







