Google 日前正式推出了新一代旗艦模型 Gemini 3.1 Pro(即開發者近期熱議的 Gemini Pro 3.1 升級版),Google 在多項權威基準測試中,強勢輾壓了 OpenAI 的 GPT 系列與 Anthropic 的 Claude Opus 4.6。
與此同時,Google 近期也釋出了專為解決極端複雜問題而生的 Google Deep Think(實驗版) 深度推理模式,引發了業界的討論。CyberQ 實測也發現,Google Deep Think 在這波推理模型(Reasoning Models)大戰中還是有自己的獨特競爭優勢。
對於開發者、企業主與 AI 狂熱者來說,現在面臨的最大問題是,面對各家大廠的火力展示,在效能與成本之間,我們該如何選擇?
Gemini 3.1 Pro 是目前地表最強的通用大模型嗎?
距離上一代 Gemini 3 Pro 僅短短三個月,Google 就用 Gemini 3.1 Pro 證明了他們的研發實力。這款模型被定位為處理複雜問題、需要進階推理與代理(Agentic)任務的旗艦首選,
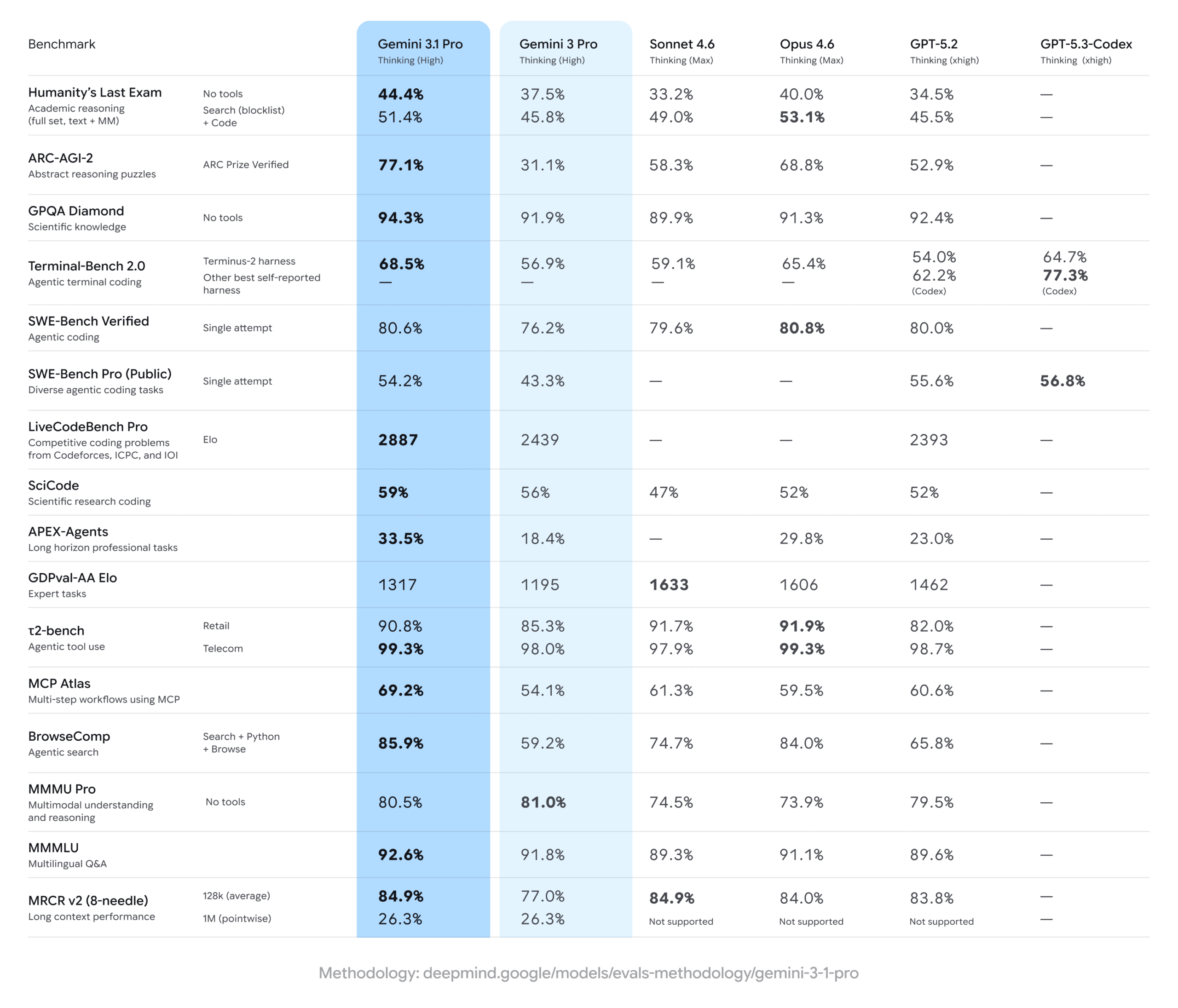
基準測試可說是成績斐然,在評估模型解決全新邏輯模式能力的 ARC-AGI-2 測試中,Gemini 3.1 Pro 拿下了驚人的 77.1%,得分不僅是前代的兩倍多,更遠超 Claude Opus 4.6 (68.8%) 與 GPT-5.2 (52.9%)。
Agent 代理能力也受到矚目,在真實世界專業代理任務 APEX-Agents 測試中,Gemini 3.1 Pro 以 33.5% 的勝率位居榜首,勝過 Opus 4.6 的 29.8% 與 GPT-5.2 的 23.0%。
程式碼撰寫與實務應用方面,這次 3.1 除了擅長撰寫複雜程式碼(Terminal-Bench 2.0 獲得 68.5%),它甚至能直接透過純文字指令,生成高質量且無損縮放的 SVG 動態動畫,輸出完全基於純程式碼,已經呈現出不錯的跨模態空間推理力。
2026 最新主流 AI API 價格比較與分析
效能再好,如果貴到用不起也是枉然。進入 2026 年,大廠間的 API 定價策略出現了明顯的分水嶺。以下是最新主流旗艦模型的 API 定價比較(以標準上下文,每 100 萬 Tokens 計算,單位為美金)。
| 模型名稱 | 開發商 | 輸入定價 (Input / 1M) | 輸出定價 (Output / 1M) | 市場定位與分析 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 高階泛用性價比,支援百萬上下文,具強大推理與代理能力。 | |
| GPT-5.2 | OpenAI | $1.75 | $14.00 | OpenAI 通用旗艦,輸入略便宜但輸出成本較高。 |
| Claude Opus 4.6 | Anthropic | $5.00 | $25.00 | 頂級模型,維持高昂價格,主打極致語感與長文本分析。 |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 | 兼顧速度與品質的中高階日常工作。 |
| OpenAI o3 | OpenAI | $2.00 | $8.00 | 專注於數理邏輯與複雜編程的慢思維推理模型。 |
| DeepSeek R1 | DeepSeek | $0.55 | $2.19 | 性價比高,開源高算力批次處理選擇之一。 |
CyberQ 認為,這波 AI API 價格戰,Google 採用降維打擊策略,Gemini 3.1 Pro 的定價 ($2.00 / $12.00) 極具侵略性。它的跑分超越了 Claude Opus 4.6,但成本卻不到 Opus 4.6 的一半,甚至比 Anthropic 的中階模型 Sonnet 4.6 還要便宜。
輸出端成本決勝負,與 GPT-5.2 相比,雖然 Gemini 3.1 Pro 的輸入端略貴了 $0.25,但輸出端卻便宜了 $2.00。在生成大量程式碼、報告或執行多步驟的 Agentic 任務中,對於我們開發團隊和企業均能省下不少長期營運成本。
高階市場分化也慢慢開始,Anthropic 的效能優異,依然維持著 $5/$25 的「精品定價」,而 Google 則選擇以較低價格下放旗艦推理能力,這可能得迫使競爭對手重新思考定價策略。
Google Deep Think (實驗版) 的推論差異與競爭力
在 Gemini 3.1 Pro 應付日常與大規模商業應用的同時,Google 真正用來探索 AI 智力能走到哪裡的要角,是近期有重大升級的 Google Deep Think(專項深度推理模式),這也是 Google 用來正面迎擊 OpenAI 推論模型的核心底牌。
Deep Think它是什麼?與一般 LLM 有何不同?
傳統大語言模型(如 GPT-5.2 或一般版 Gemini)追求的是儘快回應用戶的提問,是直覺式的 System 1 思考;而 Deep Think 採用了多智能體平行推理(Multi-agent parallel reasoning)架構。在給出答案前,它會在後台投入大量運算時間,同時啟動多個 AI 代理進行平行思考、交叉驗證、自我辯論,並在收斂出最佳解後才輸出。這是一種相對較慢但輸出會比較不會錯與減少幻覺的 System 2 慢思維。
學術與工程實力更上一層樓
在 2025 年國際數學奧林匹亞(IMO)標準測試中,Google Deep Think 成功拿下了 35/42 分,相當不簡單,甚至還成功地解出 5 道極度困難的數學題。在競技寫程式平台 Codeforces 上,其 Elo 評分更是達到頂尖人類選手的水準。它不是用來寫日常 Email 的,而是專為解決材料科學、量子物理、複雜晶片架構設計等高難度挑戰而生。
市場差異化與核心競爭力
與 OpenAI 或其他開源推理模型相比,Google Deep Think 的最大差異化在於生態系整合力與商業應用彈性,CyberQ 觀察,Google 可透過自己的生態系護城河,讓Deep Think 不僅在沙盒裡憑空推論,去結合 Google Cloud 龐大的科學資料庫與即時網路索引(Web Grounding),它的推理能夠有全球最大的知識圖譜做為後盾。
準確度 > 速度的商業價值上,它可能會花費數分鐘的時間思考一條問題。但是呢,對企業而言,儘管會產生較高的思考 Token計費成本,可是在容錯率要求相對較低的研發、財報分析或工程決策上,花費幾分鐘換取無漏洞的架構,能為公司省下人類工程師數週的試錯成本。
開發者與企業該怎麼選?
進入 2026 年,AI 基礎設施的佈局戰略逐漸清楚,依任務分層佈署(Model Routing)是相對較好的解法。CyberQ 認為,追求性價比與商業 AI 應用落地的企業,Gemini 3.1 Pro 是目前市場上的首選。它用不到對手一半的價格,提供了打敗 GPT-5.2 的邏輯跑分與頂尖的代理(Agent)能力,非常適合用於複雜的軟體開發,並構建企業自動化系統。
面對學術研究與極端複雜難題的團隊,請申請測試 Google Deep Think。當遇到連資深工程師都卡關的難題時,讓 AI 花上幾分鐘去進行平行推理,它有機會成為團隊突破研發瓶頸的好助手。
Google 這次打出用 Gemini 3.1 Pro 搶佔實用市場,再搭配 Deep Think 拓展推論需求高的客戶,說實在已經降低了一線 AI 大型模型的價格門檻,並把專業深度推理的競爭腳步打開,近期其他 AI 業者勢必在這一局會加碼競爭下去。