

NVIDIA 最新的消費級卡皇 GeForce RTX 5090 才剛問世不久,其標準配備的 32GB GDDR7 記憶體已是消費等級顯示卡市場頂尖。然而,在對算力需求近乎貪婪的人工智慧(AI)市場面前,這似乎仍不夠看。近期,市場上驚現由中國工廠操刀的「魔改版」RTX 5090,其記憶體容量竟被擴充至 128GB,是原版的整整四倍。
非遊戲目的,聚焦在 H100 平替板 AI 算力
首先要釐清的是,這款超級魔改版的 RTX 5090 並非為遊戲玩家所設計。它的誕生,完全是為了滿足 AI 和機器學習領域對龐大視訊記憶體 VRAM 的需求,這是因為要訓練可用的 AI 模型,和執行參數較多的 LLM 模型,都需要更多視訊記憶體或統一記憶體的設備,有 80GB、96GB、128GB 的版本會比較好用。由於美國對 NVIDIA 高階 AI 晶片有出口管制,加上部分地區市場的正規 AI 加速卡(如 H100)的短缺與高昂關稅,讓腦筋動得快的中國廠商找到了市場缺口。
他們將目光投向了消費級旗艦 RTX 5090,透過硬體改造技術,將其變身為適用於伺服器與工作站的 AI 運算平價替換版高階卡。

Photo Credit : NVIDIA 官方版 RTX 5090
鬼斧神工的硬體改造
要將 32GB 記憶體擴充至 128GB,絕非易事。根據目前外界掌握到的流出資訊,整個改造過程相當複雜:
更換元件與 PCB: 廠商必須對顯示卡印刷電路板(PCB)進行大幅度修改,並採用雙面 PCB 或特製的 PCB 轉接板,才能增加額外的記憶體模組連接到顯示卡的板卡上。
特製韌體與 BIOS: 硬體焊接與魔改完成後,還需要刷入專屬的韌體(Firmware)與 BIOS,避開原本 NVIDIA 原本韌體上的規格設定和限制,才能讓顯示卡正確識別並驅動高達 128GB 的記憶體。
伺服器級散熱: 為了能穩定地在伺服器機箱中 24/7 全速運作,原廠的開放式散熱器被更換為更適合伺服器環境的雙插槽渦輪風扇(Blower-style fan),甚至是更高階的水冷散熱系統,確保熱氣能被有效地排出機箱。
儘管有 nvidia-smi 工具顯示 128GB 容量的截圖作為證據,外界也有人對於其技術實現方式仍存有疑慮,這也讓這次的魔改更添一絲神秘色彩。
價格不斐的算力代價
當然,如此極致的客製化改造,價格自然不斐。原本我們去市場上購買一張標準版的 NVIDIA RTX 5090 的建議售價約為 1,999 美元,但因為缺貨和 AI 顯卡市場熱絡,市價可能落在 2,500 至 3,000 美元之間。然而,這款 128GB 的魔改版 RTX 5090,售價竟高達 13,200 美元,是原價的六倍以上。另外,對比 NVIDA 官方版記憶體較多的 RTX 專業運算卡, RTX PRO 6000 Blackwell(96GB 記憶體)售價約 10,000 美元,也是很接近,但記憶體容量比較少。
儘管價格驚人,但在特定市場中,對於那些急需算力卻又受限於採購管道,也就是中國與其他可能受管制市場的 AI 研究機構和相關廠商來說,這當然是目前「相對划算」且可行的解決方案。
中國 AI 算力市場的龐大需求與貿易限制刺激產生的魔改
CyberQ 認為,這次的 RTX 5090 魔改事件,其實顯示出中國 AI 算力市場的需求仍大,並考量貿易上的管制或限制,呈現出「市場需求驅動創新」的奇妙商品。在過去,中國廠商就會買很多張 RTX 5090 卡,去組一個 8卡版的 RTX 5090 AI 算力伺服器來販售,讓無法取得 H100、H200 這種先進伺服器的廠商,也能夠獲得他們想要的算力,儘管每瓦效率和穩定度未如官方版銷售的伺服器,算力也遠遠不足高階伺服器,但對需要算力的人來說,夠用、可以用就好了,可能是過渡時期,之後還是要補強夠高算力的設備。
Photo Credit : NVIDIA DGX GX300
這些改裝 RTX 5090 顯示卡、改裝 RTX 5090 多卡伺服器,均為非 NVIDIA 官方認可的產品,穩定性與保固自然是有風險的,但購買的廠商和機構,以及開發者們,對算力的需求迫切,這些都不算什麼啦,就 CyberQ 在亞洲市場的瞭解,相關二手 AI 晶片與硬體的貿易量不小,化整為零再重生加裝記憶體、刷魔改韌體的情況不算少見,多半從台灣、香港與新加坡等地轉貿易到中國市場,再由當地工廠組裝或改裝,送交到 AI 算力需求的廠商手上,溢價當然是比原本的產品金額高,但需求強勁,這塊市場確實還未減弱。
另外,2025年9月中到10月份,NVIDIA 官方與華碩、宏碁、技嘉、微星、Dell、HP等 OEM 合作夥伴推出的 DGX Spark 也受到市場矚目,其 128GB 統一記憶體的特性,以及 RTX 50 高階顯示卡的 AI 算力效能,加上僅新台幣 10 多萬元的售價,透過 NVIDIA 高速網路,如用10GbE、ConnectX-7 的400GbE 串接多台 NVIDIA DGX Spark,或用 400GbE 的DAC(Direct Attach Cable)光纖直連電纜,直接串接2台NVIDIA DGX Spark做平行運算,兩台這樣的機器還可以組成 256GB 統一記憶體的 AI 運算叢集,甚至是更多台組成更大的算力中心,預期也會對市場帶來新的影響和效益。
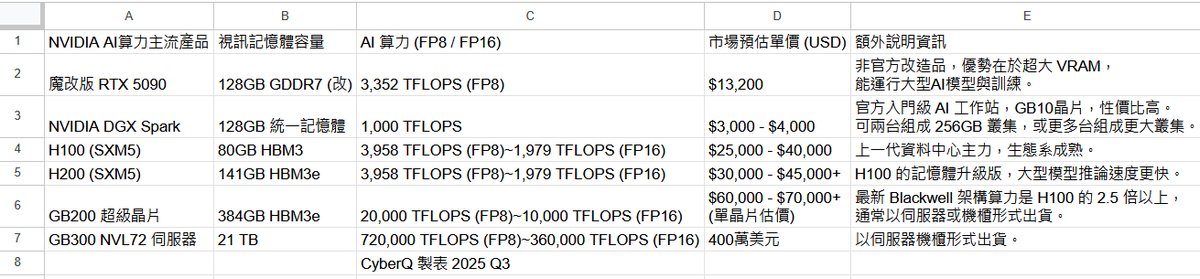
Fig. Credit : CyberQ
可以對照一下,對於中小型 AI 廠商和個人 AI 開發者而言, NVIDIA 新的 DGX Spark 無疑是更經濟划算的選擇,雖然算力未如魔改版 RTX 5090 ,但組成多台的效益也是可以負擔得起的價格,這對許多開發者和小型團隊、學校機構是有吸引力的。
不但如此,NVIDIA 還有新的 DGX Station 這個更強大的 AI 運算工作站,視訊記憶體可拉到 288GB HBM3e ,每秒頻寬可達 8 TB/s,也是中型企業會看中的新品,目前 NVIDIA 也是透過各地經銷商和學校、AI 研究機構、廠商進行銷售中,也是可參考的選項。

首圖採用 ComfyUI 本地端 AI 模型搭配 NVIDIA 顯示卡產生







