
在電腦視覺領域中,讓人工智慧精確計算影像中的物件數量一直是一項看似簡單、實則極具挑戰性的任務。無論是遙測影像中的車輛、顯微鏡下的細胞,還是農田裡的作物,傳統模型往往受限於特定場景與特定類別。近日,一項名為 Count Anything 的全新開源專案引起了科技界與人工智慧社群的廣泛關注。該專案基於最新發表的學術論文,提出了一種由文字引導的跨領域通用計數模型,真正實現了所見皆可數的技術突破。
傳統物件計數的技術困境與核心問題
CyberQ 觀察,傳統的物件計數演算法主要依賴基於密度圖的方法。這種架構雖然在特定高密度場景(例如演講廣場上的擁擠人群)中表現良好,但當面對不同領域、不同尺度以及不同分佈密度的影像時,其泛化能力便會遭遇嚴重瓶頸。這正是視覺領域長期存在的技術問題。當模型從通用日常場景切換到醫學組織病理學或農業監測時,由於目標物體邊界模糊且尺度落差劇烈,現有的開放世界計數方法往往會完全失效。此外,過去的架構通常需要針對個別場景重新進行大量的模型微調與架構調整,無法做到真正的通用化。
CLOC 橫跨六大視覺領域的巨量基準測試資料集
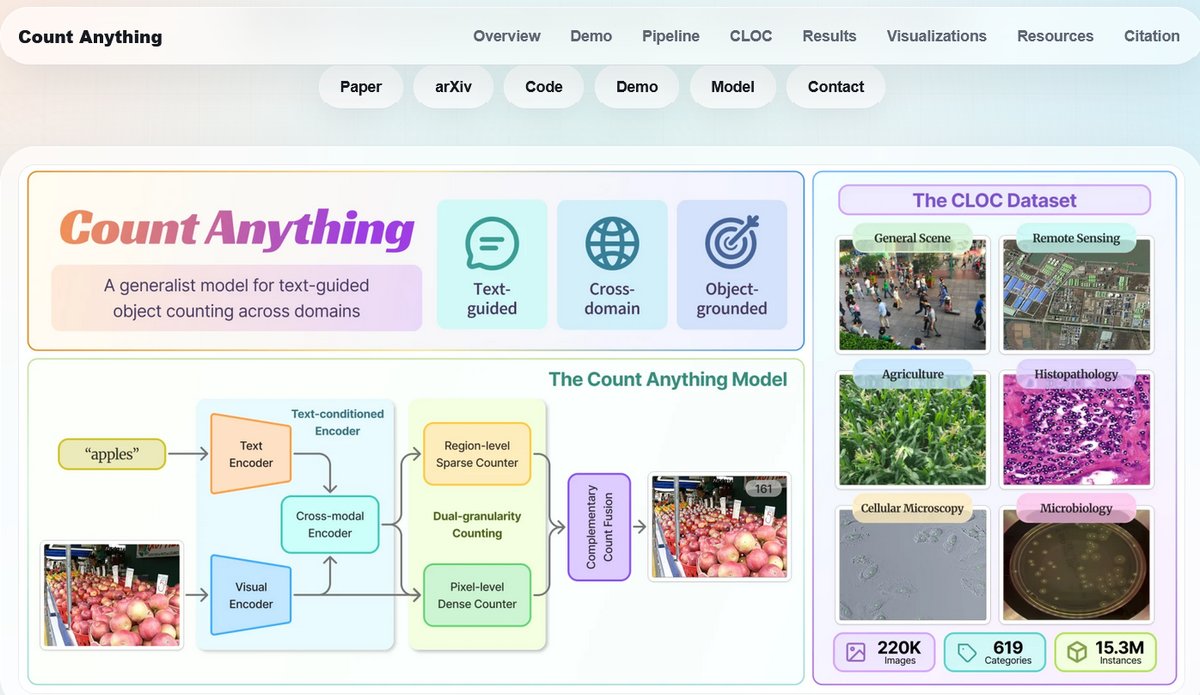
為了克服跨領域資料缺乏的挑戰,研究團隊首先建構了一個名為 CLOC(Cross-domain Large-scale Object Counting)的跨領域大規模物件計數資料集。這個資料集將多元的公開資料來源整合為一個統一的基準平台。CLOC 完整涵蓋了六大關鍵視覺領域,包括通用場景、遙測影像、組織病理學、細胞顯微鏡、農業監測以及微生物學。整個資料集包含大約 22 萬張影像、619 個不同的物件類別,以及高達 1500 萬個具體的物件實例。透過建構如此龐大且具備多樣性的資料庫,研究團隊為後續通用模型的訓練奠定了堅實的基礎。
Count Anything 的創新架構為雙粒度計數與融合機制
這項專案的核心突破在於其創新提出的 Count Anything 萬物計數模型。研究團隊放棄了佔據主流的密度圖架構,轉而採用離散的實例點預測,並設計出獨特的雙粒度實例列舉機制。
模型內部整合了兩套相輔相成的技術核心。首先是區域級稀疏計數器,它主要負責為體積較大且分佈稀疏的目標物件提供物件級的定錨標記。其次是像素級密集計數器,專門透過密集的點預測技術來處理體積微小、極度擁擠且邊界極其模糊的目標。
為了讓模型能夠從多種不同類型的異質標註中進行有效學習,這個專案導入引入了以點為中心的監督策略。模型透過一個完全不需要額外參數的互補計數融合技術,將兩個計數器的優勢結合,在執行高精確度計數的同時,也能提供具備可解釋性的空間定位。
文字引導與開放世界的新範式
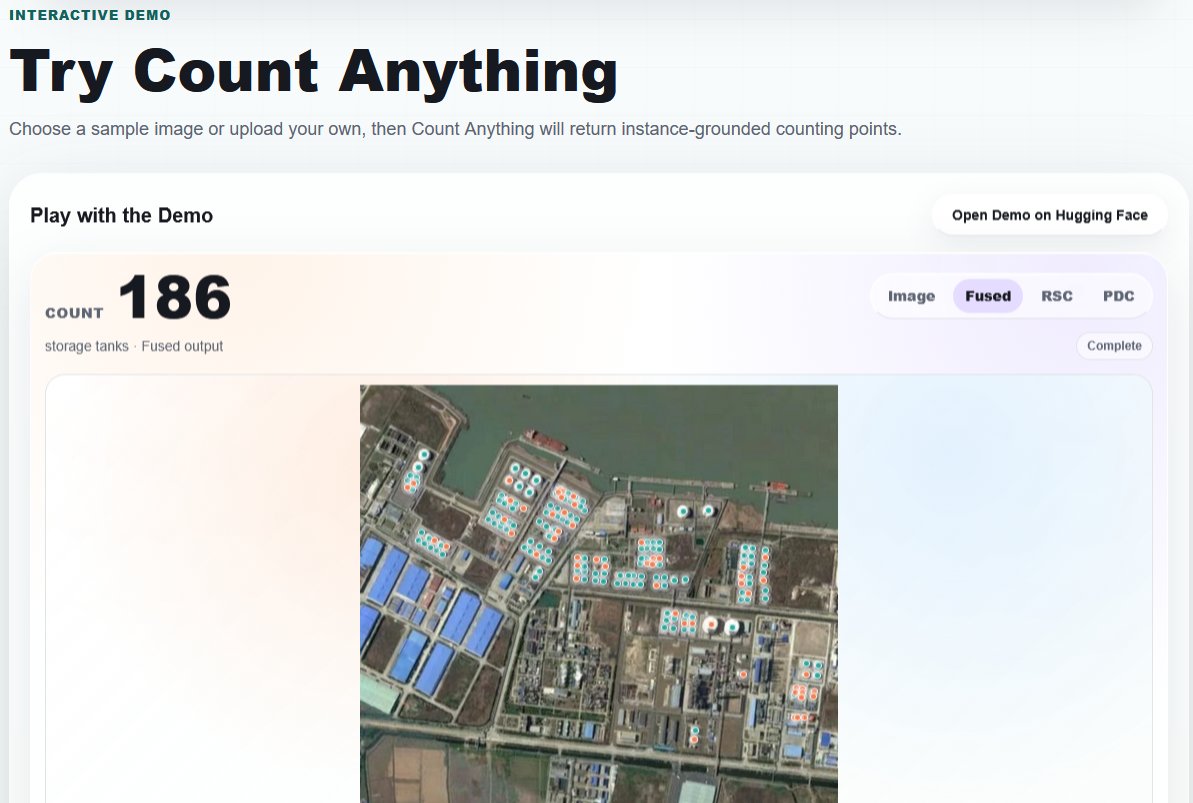
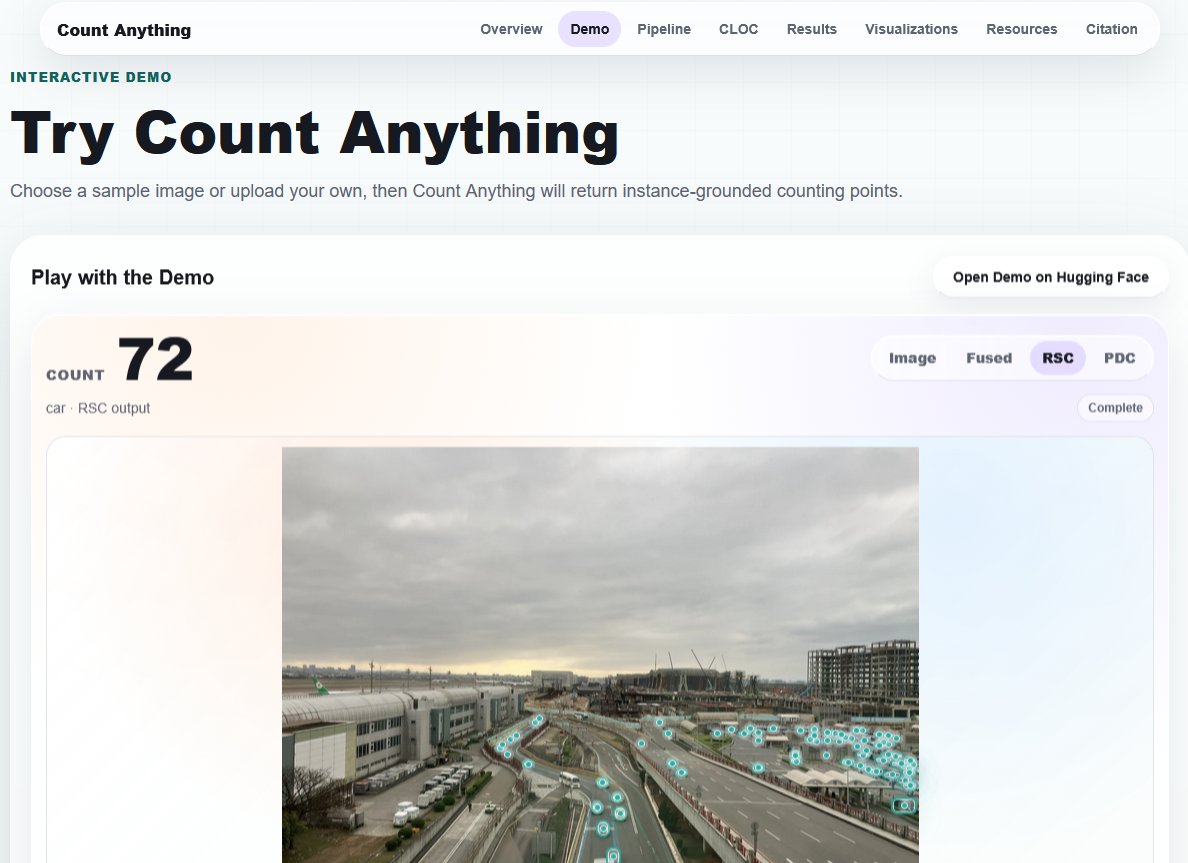
Count Anything 的另一大優勢在於其靈活的互動與控制能力。使用者只需輸入一張影像以及一段自然語言查詢(例如計算畫面中的白血球數量或計算停車場中的紅色車輛),模型就能夠自動理解文字意圖並精確標註出所有目標位置。
這種文字引導的架構讓物件計數從傳統的類別受限,走向了開放世界的全新範式,大幅降低了各產業在實際部署 AI 工具時的技術門檻。
開源生態與未來展望
目前,Count Anything 的完整程式碼已在 GitHub 上正式開源,吸引了大量開發者與資安、資訊工程人員的關注。CyberQ 認為,這種高泛化能力的通用模型將為自動化資產盤點、醫學影像輔助分析以及智慧農業帶來革命性的變革。其具備的離散點定位能力,也為未來的資安合規審查與自動化影像稽核提供了極佳的底層技術支援。隨著開源社群的不斷投入,我們期待看到更多基於此架構的最佳化延伸應用落地。
學術論文(arXiv 2605.30846):https://arxiv.org/abs/2605.30846
GitHub 原始碼專案:https://github.com/Mengqi-Lei/count-anything










