在 AI 業界正追求龐大參數與混合專家 (MoE) 架構的同時,阿里巴巴通義實驗室 (Qwen Team) 這次釋出的全新的開源模型 Qwen3.6-27B 受到了業界高度關注。這是一款擁有 270 億參數的稠密模型 (Dense Model),並主打頂尖的代理程式開發 (Agentic Coding) 能力。
根據 Qwen 官方部落格的最新發布,這款僅有 27B 參數的模型,在多項程式開發指標上,竟然全面擊敗了自家總參數高達 3,970 億的前代旗艦 MoE 模型 Qwen3.5-397B-A17B。CyberQ 實測部署了這款模型,並參考官方基準測試資料,以及實際應用來看它之後的潛力。
捨棄 MoE,回歸稠密的實用主義
官方強調,這次的開發不受刷跑分 (benchmark optimization)驅動,而是建立在開發者社群真實的回饋之上,專注於穩定性與真實世界的實用性。為了讓開發者更容易部署,Qwen3.6-27B 移除了 MoE 的路由複雜度,回歸全稠密 (Fully Dense) 架構,並帶來了幾項重大創新:
混合注意力架構 (Hybrid Architecture)
模型結合了 Gated DeltaNet 線性注意力機制與傳統的自注意力 (Self-attention)。這種混合設計不僅提升了生成效率,更原生支援高達 262,144 個 Token(可擴展至 100 萬)的超大上下文視窗。
思維保留機制 (Thinking Preservation)
這是一項專為 AI Agent 開發打造的全新機制。透過 API 中的 preserve_thinking 功能,模型能夠在多輪對話歷史中,保留先前的思考與推理脈絡。這能大幅減少反覆迭代與多步驟除錯時的運算開銷。
代理程式開發升級 (Agentic Coding)
模型針對前端工作流程與儲存庫級別 (Repository-level) 的推理進行了大幅最佳化,能深入理解大型程式碼庫、進行跨檔案導航與產生可執行的輸出。
原生多模態 (Natively Multimodal)
在單一模型權重下支援視覺與語言,處理圖片與影片,並允許在思考模式 (Thinking mode)與非思考模式 (Non-thinking mode)之間切換。
官方測試小蝦米戰勝大鯨魚
根據官方提供的測試資料,Qwen3.6-27B 效能超越了體積是其約 15 倍的前代開源旗艦模型 Qwen3.5-397B-A17B (397B 總參數 / 17B 活躍參數):
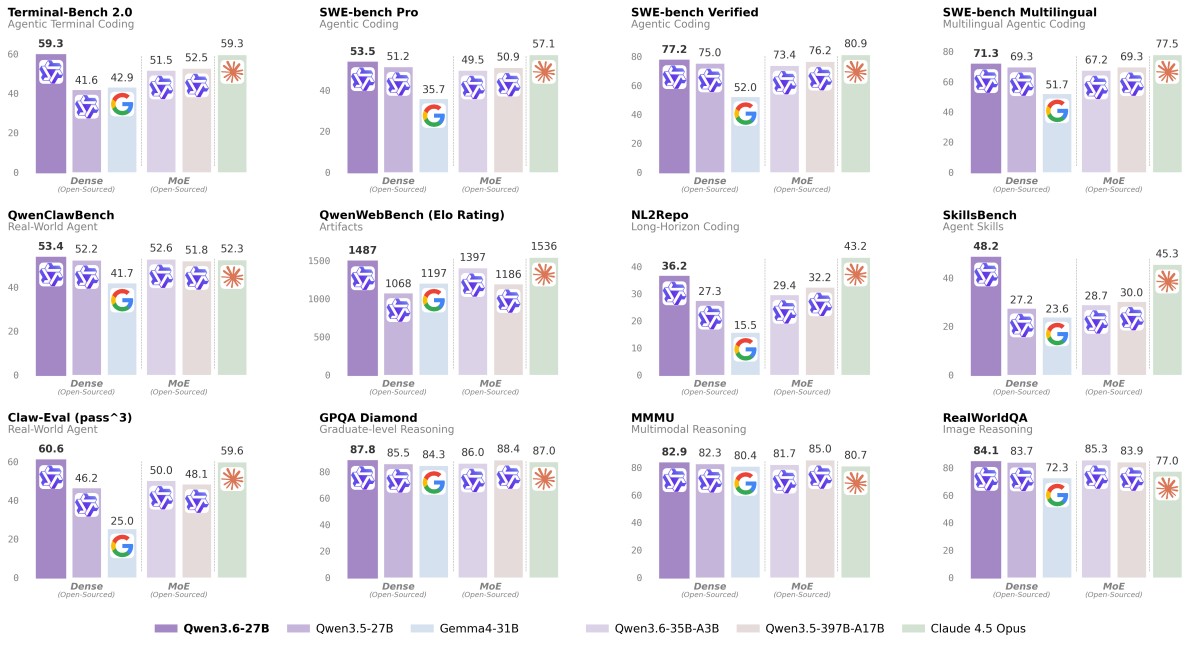
SWE-bench Verified: 77.2 (勝過 397B 模型的 76.2)
SWE-bench Pro: 53.5 (勝過 397B 模型的 50.9)
Terminal-Bench 2.0: 59.3 (勝過 397B 模型的 52.5)
SkillsBench: 48.2 (大幅超越 397B 模型的 30.0)
此外,在涵蓋多種類別的內部中英雙語前端基準測試 QwenWebBench 中,它獲得了1487 分(對照千問的上一代 27B 模型僅 1068 分),在進階邏輯推理測試 GPQA Diamond 中,亦取得 87.8 的優異成績,實力已逐步接近幾倍大的頂級 AI 模型。
實機測試感想
官方跑分固然亮眼,但它在本地端 (Local) 的真實表現如何? CyberQ 用個人電腦與 AI 工作站測試,讓模型權重檔案放在 QNAP NAS 的 NFS 上,本機和 NVIDIA DGX Spark 都可以來讀取,它在本機端具備不錯的執行流暢度。透過 llama-server 載入約 16.8GB 的 Unsloth Q4_K_M 量化版本是可行的。
另外,實際測試中,它也可以整合到流行的第三方程式設計助手中,比方說熱門的龍蝦 OpenClaw、Hermes Agent、OpenCode等等。
Qwen API 也支援 Anthropic API 協議,所以可以這樣整合進去 :
# Install Claude Code
npm install -g @anthropic-ai/claude-code
# Configure environment
export ANTHROPIC_MODEL="qwen3.6-27b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.6-27b"
export ANTHROPIC_BASE_URL=https://dashscope.aliyuncs.com/apps/anthropic
export ANTHROPIC_AUTH_TOKEN=<your_api_key>
# Launch the CLI
claude
CyberQ 指出,這款模型的硬體門檻相對不會太高,進行初次執行時,把約 17GB 的模型快取至本地,對於具備足夠記憶體的電腦或工作站來說是好部署的。
從 llama-server 測試,讀取速度達 53 tokens/s,生成測試約為 25 tokens/s。繪圖與空間推理品質也不錯,對於一個 16.8GB 的本地模型來說已經很不簡單了。
開源部署資訊
Qwen3.6-27B 的出現是件好事,實務上確實我們在本機跑不動動輒上千億參數的模型,但只要架構創新,比方說捨棄 MoE 帶來的複雜度,加上預訓練用的資料品質優秀,27B 的稠密模型也能成為強大的本機端程式 AI Agent,搭配 AI 代理人會是好用的。
該模型採用 Apache 2.0 授權,完全免費且可用於商業用途。阿里巴巴通義官方目前已於 Hugging Face 上釋出 Qwen3.6-27B 標準的 BF16 權重與精細的 FP8 量化版本,且已能相容於 vLLM (>=0.19.0)、SGLang、KTransformers 等主流 AI 生態工具。
另外,這款模型也支援在 Ollama 上跑,並且能在 16GB VRAM 的顯示卡上使用,但會觸發系統的記憶體分載(Offloading)機制,建議是要用更大的卡來跑比較好。
針對 16GB VRAM ,要留意記憶體佔用與 CPU 分載 (Offloading) 機制,這是因為 Ollama 預設會拉取 4-bit 量化版本 (如 Q4_K_M)。27B 模型的 4-bit 權重體積大約落在 15GB 到 16GB 之間。當加上推論所需的上下文快取(KV Cache)後,總記憶體需求通常會來到 17GB 到 18GB 左右。在 16GB VRAM 的環境下,Ollama 不會報錯崩潰,而是會自動將無法塞入顯存的模型層溢出,分載到系統記憶體 (System RAM) 交由 CPU 運算,速度就會變慢了。
對 Agent 框架長文本執行的影響方面,在執行 OpenClaw 或 Claude Code 這類自主 AI Agent 框架時,由於需要不斷讀取專案檔案或分析程式碼,上下文長度會迅速攀升。這會導致 KV Cache 膨脹,迫使更多模型層被擠出 VRAM。雖然模型依然能給出高品質的推理結果,但生成速度會因為頻繁的 VRAM 與系統 RAM 資料交換而出現明顯下降。
在儲存與載入架構上,若你的電腦只有 16GB VRAM 的險卡,這台主機是跑在 PVE 虛擬化環境,並搭配高速網路連接至 QNAP NAS 的 ZFS 儲存池,模型初次載入至系統記憶體的速度會非常優異。若要進一步突破推論速度的瓶頸,CyberQ 建議可以選擇手動降級量化,改為拉取 qwen3.6:27b-q3_K_M(3-bit 量化版本),權重體積會降至約 12GB 左右,保留充足的 VRAM 空間給 Agent 的長文本快取使用。
但是呢,如果你手邊的 Apple Silicon 設備如 M5 Mac Mini、M5 MacBook Pro 擁有較大的統一記憶體(例如 32GB 或 64GB),利用其架構來跑這類 27B 模型,在執行長文本任務時的整體流暢度,有時反而會優於受限於 16GB VRAM 的獨立顯卡。
想要更快可以採用 vLLM 多卡叢集,手邊資源夠或有擴充的計畫,可考慮切換至 vLLM 進行張量平行(Tensor Parallelism)部署,可解決單卡 VRAM 的限制並最大化吞吐量。
CyberQ 建議,如果你正在尋找一款能在個人電腦上流暢運作,卻想要能夠擁有稍微接近旗艦級 Agentic Coding 能力的 AI 助手來省日常工作用的 token ,Qwen3.6-27B 是目前最值得嘗試的選擇。