AI 新創大廠 Anthropic 日前正式推出了旗下最新旗艦模型,Claude Opus 4.7。這一次的重心徹底放在了解決專業開發者與企業的問題,也就是複雜的軟體工程、長效的自動化代理任務(Agentic Workflows),以及高解析度的視覺能力。
然而,CyberQ 實測與觀察,伴隨著強大的跑分,Opus 4.7 底層機制的改動卻也在技術社群中掀起了討論。
核心重點與基準測試(Benchmarks)超越 GPT-5.4
Opus 4.7 被 Anthropic 定位為能夠真正放手讓 AI 自己工作的模型。它具備極強的自我驗證能力,例如能夠從零開始自主建立完整的 Rust 文字轉語音(TTS)引擎,並自己編寫測試程式來驗證輸出是否正確。
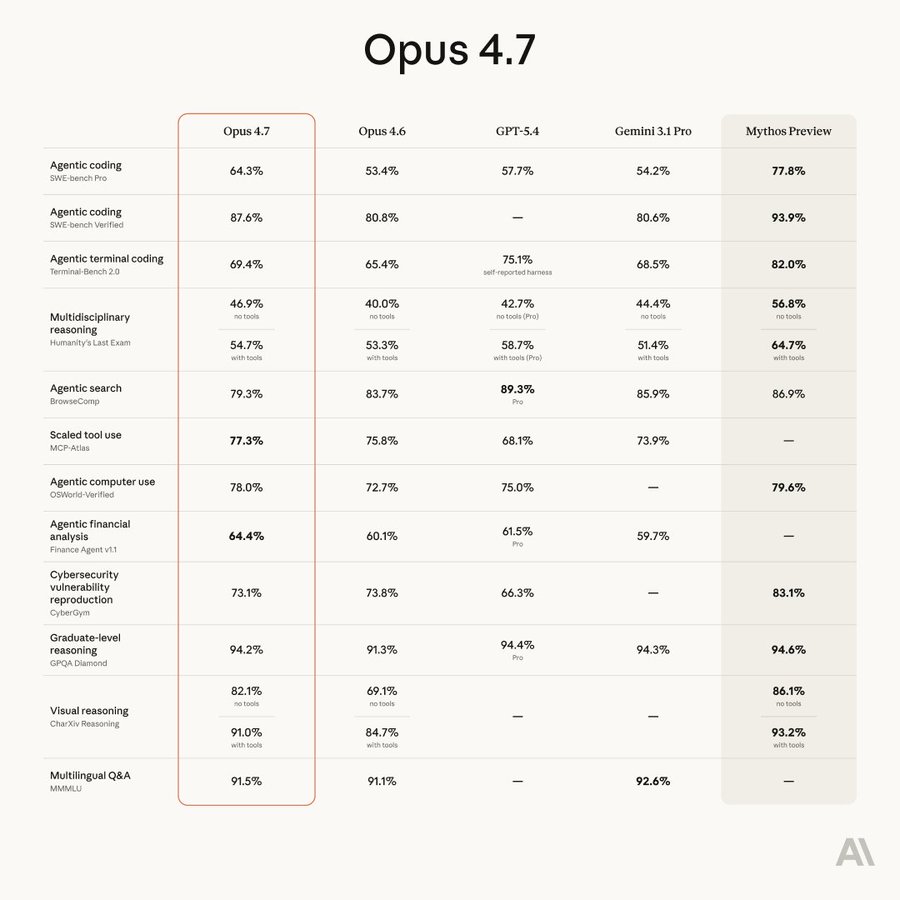
在測試成績上,Opus 4.7 在多項關鍵指標上刷新了業界標準,甚至跨越了競爭對手 OpenAI 的 GPT-5.4 與 Google 的 Gemini 3.1 Pro:
軟體工程與自主程式碼撰寫(SWE-bench Pro)
在衡量真實世界軟體工程問題的 SWE-bench Pro 測試中,Opus 4.7 的任務解決率從前代 Opus 4.6 的 53.4% 大幅躍升至 64.3%,一舉擊敗了 GPT-5.4 (57.7%) 與 Gemini 3.1 Pro (54.2%)。
Humanity’s Last Exam, HLE
在號稱最難的多模態測試 HLE 中,根據 Mashable 的綜合評測報導,Opus 4.7 在無工具輔助下獲得了 46.9% 的高分,超越了 Gemini 3.1 Pro (44.4%) 與 GPT-5.4 Pro (42.7%)。
視覺解析度提升 3 倍
Opus 4.7 現在支援最長邊達 2,576 像素的圖像輸入,這讓它在讀取密集的技術圖表、文件與複雜的使用者介面(UI)時,擁有極高的像素級精準度。
全新的xhigh思考層級
模型引入了自適應思考(Adaptive Thinking),並新增了介於 high 與 max 之間的 xhigh (Extra High) 推理層級,專門處理極端困難的程式碼除錯與邏輯推演。
被封印的神級模型 Claude Mythos 與 Project Glasswing
在討論 Opus 4.7 時,必須提到它背後的安全考量。事實上,Anthropic 在發表聲明中承認:Opus 4.7 並不是他們手裡最強大的模型。
真正擁有高跑分的實力,是目前並未公開發布的實驗性模型 Claude Mythos Preview(其 HLE 分數高達 56.8%)。然而,隨著 AI 寫程式的能力攀升,其尋找系統漏洞(Zero-day)的駭客能力也變得異常危險。
為此,Anthropic 發起了 Project Glasswing 資安計畫,聯合各大科技大廠,先將強大的 Mythos 應用於防禦性地修補全球關鍵基礎設施以及加固。而我們現在使用的 Opus 4.7,其實是刻意限制了網路攻擊能力的版本,並內建了極為嚴格的資安護欄(Cybersecurity safeguards),以防止技術遭惡意濫用。
開發者社群討論隱形漲價、API 閹割與檢索退化
儘管 Opus 4.7 的跑分卓越,但其底層改動卻在開發者社群引發了正反兩極的激烈討論。在 Reddit (r/ClaudeAI) 的熱門貼文中,開發者們揭露了幾個實務上的嚴重痛點:
Tokenizer 更新帶來的「隱形漲價」
雖然 Opus 4.7 官方定價維持不變(每百萬輸入 $5 / 輸出 $25 美元),但它採用了全新的 Tokenizer。這意味著同樣長度的文字,現在會被計算為原本 1.0 倍至 1.35 倍的 Token 數量。加上模型在 xhigh 模式下預設會產出更長的思考過程,許多使用者的 API 配額提早耗盡,被社群強烈質疑是變相漲價。
長文本檢索(MRCR 基準測試)下滑
CyberQ 查閱技術文件發現,Opus 4.7 在長文本精準檢索(MRCR)的準確率,竟從 4.6 版本的 78.3% 暴跌到了 32.2%。雖然 Anthropic 解釋新模型的訓練偏向長文本多節點推理,而非死板的海底撈針,但這對於高度依賴 RAG(檢索增強生成)的企業而言是一大退步。
強制移除採樣參數(Temperature, Top_p)
Opus 4.7 API 做出了一個極具爭議的破壞性改動,徹底移除了 temperature、top_p 與 top_k 參數。開發者無法再透過設定 temperature=0 來獲取絕對穩定的輸出,只能完全依賴 Prompt(提示詞)來控制,讓許多企業的自動化流程被迫重寫。
過度敏感的安全護欄(Claude Code 誤判)
由於 Opus 4.7 搭載了嚴格的網路安全防護,許多使用者抱怨它有時會將正常、無害的簡單程式碼誤判為惡意軟體(Malware)並拒絕執行編輯,反而拖慢了開發效率。
Claude Opus 4.7 的部署
Claude Opus 4.7 模型已經同步在 Claude API、Snowflake Cortex AI、Amazon Bedrock 以及 Google Cloud Vertex AI 平台上線。
CyberQ 建議如果你的專案核心是複雜軟體工程、長時間多步驟的 Agent 工作流,或是需要處理高解析度的 UI 介面分析,Opus 4.7 強悍的自主執行與除錯能力絕對是當今地表最強的 AI 助理。
但如果對於 API 預算與 Token 使用量極為敏感,在全面把自己呼叫 API 的程式做轉移前,先以少量流量進行測試,並重新微調你的 Prompt 以適應新模型極度字面化的指令遵循特性。