

AI 助理市場正經歷一次顯著的市場變化,有不少使用者開始將工作流程從 ChatGPT 遷移至 Claude,這並非單純的品牌偏好轉換,而是由底層技術突破與新功能所驅動。特別是 Claude 4.6 Sonnet 的發布,不僅將新款 AI 能力下放給免費及輕量級訂閱用戶,更推出了跨平台的脈絡匯入(Context Import)與記憶(Memory)功能。
CyberQ 實測這項功能,確實只要將 ChatGPT 的資料匯出給 Claude 就能實現,且不只是 OpenAI 的 ChatGPT,連 Google Gemini 的資料也可以匯出,餵給 Claude 使用。
Claude 4.6 掀起遷徙潮的三大推力
近期 AI 平台轉換潮,CyberQ 也在 Claude 進行了實測,這主要建立在以下幾個核心優勢上:
首先是免費階層的算力解放,Claude 4.6 Sonnet 證明了頂尖的推論與編碼能力不再是高價訂閱的專利,這大幅降低了企業與開發者測試、導入 AI 工具的門檻。
其次是無縫的脈絡匯入,這是促成搬家潮的關鍵殺手鐧。Claude 允許使用者將 ChatGPT 等競爭對手的歷史對話與自訂指令(Custom Instructions)直接匯入,許多使用者們其實在各大 AI 平台都有紀錄和記憶,這樣可讓使用者的 AI 數位資產 不被單一平台綁架。
再來是跨越對話邊界的記憶,由於這些 AI 大平台能夠記住使用者的偏好、開發環境設定、甚至是資安合規的標準要求,並在未來的對話中自動調用,這讓主流市場的 LLM 繼續進化為更具備連續性的數位協作者。
從 ChatGPT 到 Claude 的無縫大遷徙實作指南
將工作流程從 ChatGPT 轉移至 Claude,絕非只是換一個網址登入這麼簡單。過去幾年累積的對話脈絡、自訂指令(Custom Instructions)與開發除錯歷史,都是極具價值的個人化 AI 數位資產。
要實現無痛且符合資安規範的遷移,CyberQ 進行以下四個階段的實作流程:
階段一:提取 ChatGPT 數位資產 (Data Export)
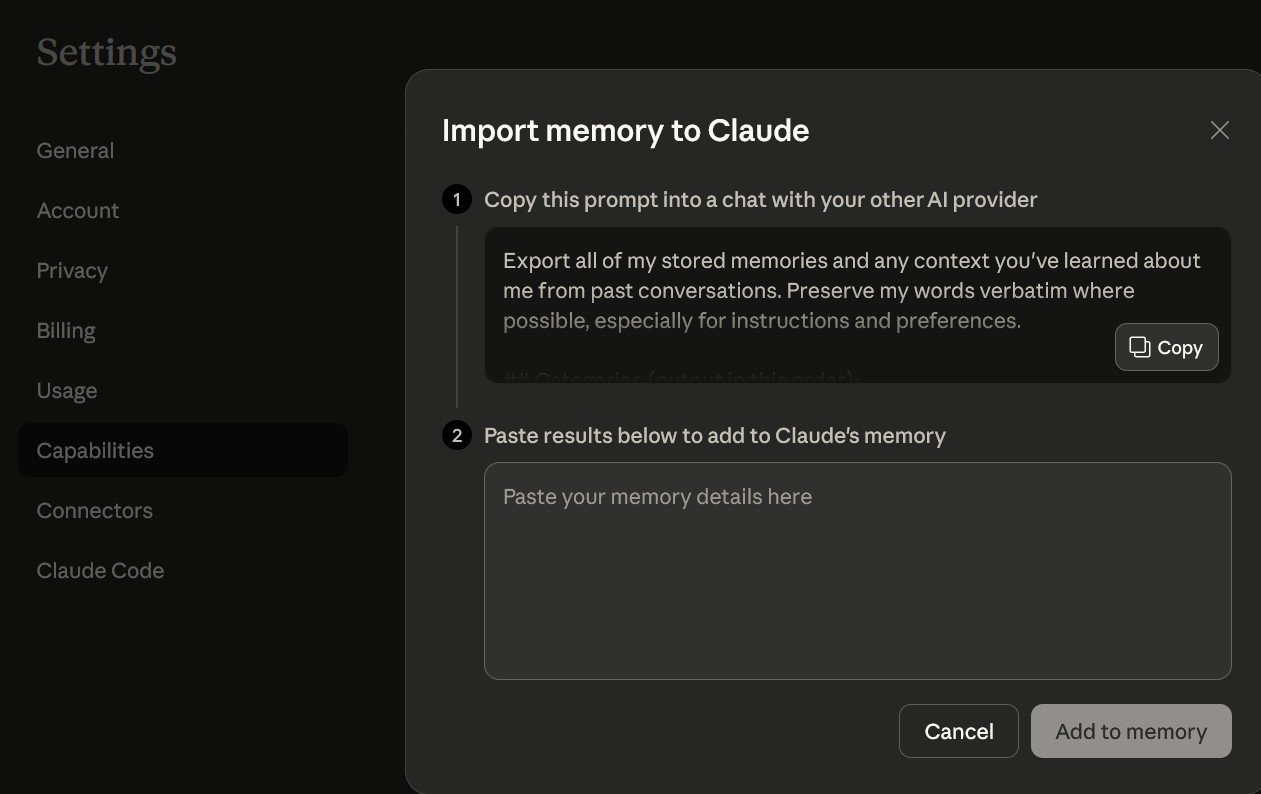
首先,必須將我們在 OpenAI 生態系中的歷史資料完整「打包」帶走。Claude 提供兩種方式,第一種是複製使用下列他們設計的提詞 Prompt 貼到 ChatGPT 或 Google Gemini 等其他 AI 平台上。
Export all of my stored memories and any context you've learned about me from past conversations. Preserve my words verbatim where possible, especially for instructions and preferences.
## Categories (output in this order):
1. **Instructions**: Rules I've explicitly asked you to follow going forward — tone, format, style, "always do X", "never do Y", and corrections to your behavior. Only include rules from stored memories, not from conversations.
2. **Identity**: Name, age, location, education, family, relationships, languages, and personal interests.
3. **Career**: Current and past roles, companies, and general skill areas.
4. **Projects**: Projects I meaningfully built or committed to. Ideally ONE entry per project. Include what it does, current status, and any key decisions. Use the project name or a short descriptor as the first words of the entry.
5. **Preferences**: Opinions, tastes, and working-style preferences that apply broadly.
## Format:
Use section headers for each category. Within each category, list one entry per line, sorted by oldest date first. Format each line as:
[YYYY-MM-DD] - Entry content here.
If no date is known, use [unknown] instead.
## Output:
- Wrap the entire export in a single code block for easy copying.
- After the code block, state whether this is the complete set or if more remain.第二種方式是去 AI 平台的設定,去匯出資料,下面的案例是 CyberQ 進入 OpenAI ChatGPT 個人後台設定中的畫面。
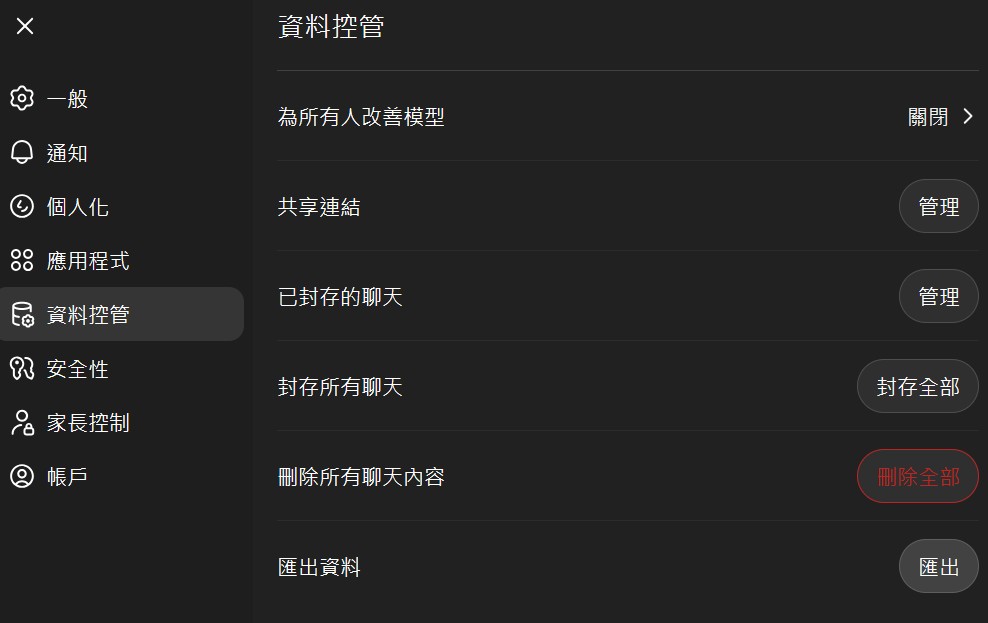
登入 ChatGPT 網頁版,進入 Settings (設定) > Data Controls (資料控管)。
點擊 Export Data (匯出資料)。
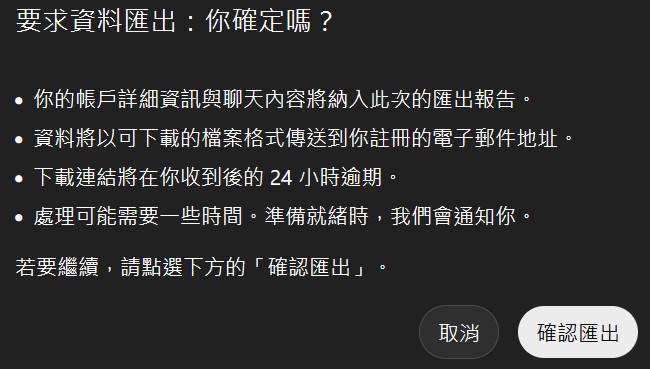
系統會將包含所有對話紀錄的打包檔發送至我們自己的信箱。
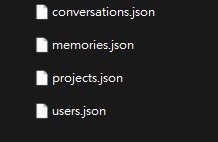
解壓縮後,會得到關鍵的 conversations.json 檔案,這正是我們自己在這個平台中所有 AI 記憶的原始碼。
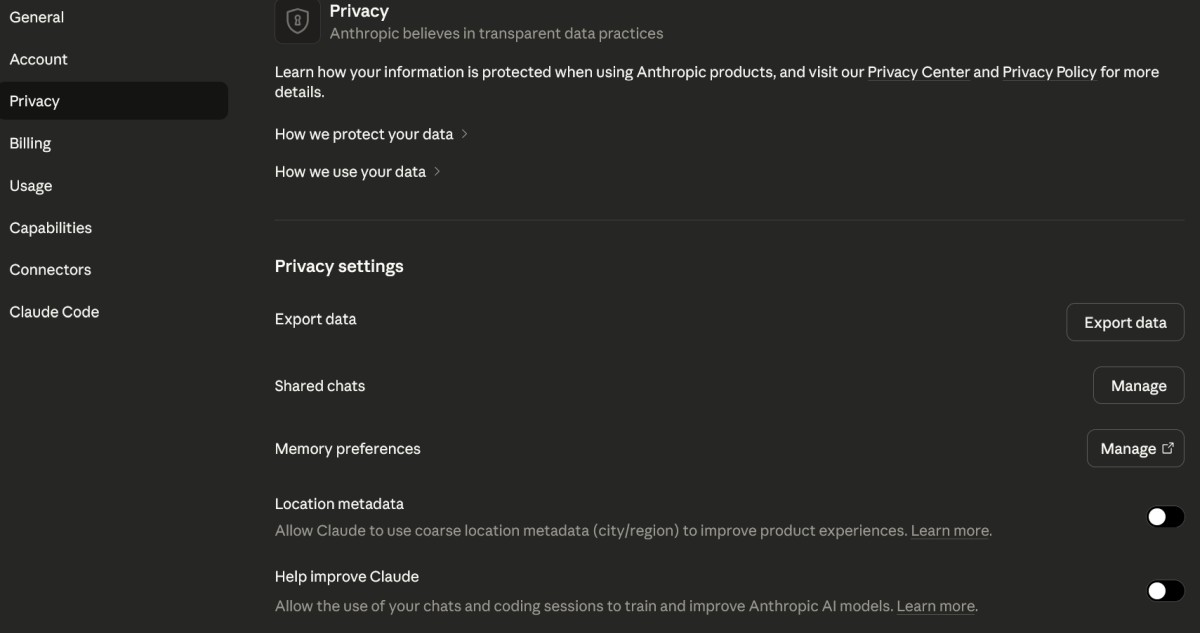
Claude 也支援這樣的功能,同樣可以匯出,如果對個人隱私有注重,上方截圖中的右下角兩個選項核取可以關閉。
階段二:資料盤點與清洗 (Data Sanitization)
在將龐大的歷史紀錄轉移到新平台或自建庫之前,這是一個絕佳的合規審查時機。
剔除機敏資訊是優先的事項,過去使用這西平台十,我們在急於解決問題時,可能不慎將帶有 API Keys、資料庫連線字串或內部伺服器 IP 的程式碼貼入對話中。在匯入新系統前,建議透過腳本(如正則表達式)掃描並清洗這些 .json 檔案中的 Hardcoded Secrets。
篩選高價值脈絡也很重要,並非所有對話都需要保留(例如日常的閒聊或早期的無效測試)。這時候可以過濾出包含架構決策、系統設定檔或特定領域知識等等之類的對話,能大幅提高未來 AI 檢索的精準度。
階段三:雙軌匯入策略 (The Dual-Track Import)
有了乾淨的資料後,針對 Claude 4.6 的新特性與我們自己擁有的 NAS 架構,可以採取雙軌併行的匯入方式:
路徑 A:匯入 Claude 雲端 (適用於常規對話與偏好)
利用 Claude 4.6 最新的「脈絡匯入 (Memory Import)」功能,位置在設定中的隱私,選 Memory 來進行匯入。
我們可以將清洗過的部分對話紀錄與原先在 ChatGPT 的「Custom Instructions」直接上傳,貼進去選 Add to memory。這能讓 Claude 迅速掌我們原本在 ChatGPT 的對話使用風格或程式碼排版偏好(例如:預設使用 Python、縮排四個空白),以及常用的溝通語氣。
路徑 B:寫入 NAS 本地向量庫 (適用於企業機密與合規記憶)
對於高度敏感的開發文件與合規歷史,我們則繞過雲端,直接將 conversations.json 轉換為向量。透過撰寫一支簡單的 Python 腳本,剖析 JSON 中的 mapping 與 message 結構,將高價值的問答對(Q&A pairs)切塊(Chunking),並寫入我們在 QNAP 上部署的 Qdrant 資料庫中。
階段四:提示詞工程 (Prompt Engineering) 的思維轉換
完成資料轉移後,最後一步是人腦的遷移。ChatGPT 與 Claude 的底層解析邏輯有著顯著的差異:
擁抱 XML 標籤是個需要注意的小細節,Claude 的模型對於 有著極高的敏銳度。過去在 ChatGPT 中習慣用換行或分隔線來區隔上下文,現在應全面改為使用 , , 等 XML 標籤來封裝資訊,這將能發揮 Claude 4.6 在處理長文本與複雜指令時的駭人精準度。
這波大遷徙的測試或好奇嘗試,也讓部分用戶在提升生產力的同時,無可避免地觸碰到了資訊安全與資料治理的敏感神經。當我們將累積多年的 AI 對話脈絡與個人/企業記憶交給雲端服務商時,資料的主權該如何確保?這正是我們需要探討的下一個關鍵架構,將 AI 記憶與上下文儲存於自建 NAS(網路附加儲存)的可能性。
資安視角聚焦 AI 記憶雲端化的隱憂
當 AI 變得越來越懂你,它所掌握的機敏資訊甚至個人資料也就越多。無論是架構程式碼、伺服器組態、還是企業內部的合規稽核草案,這些被系統化儲存的記憶,本質上就是高度敏感的資料庫。
雖然主流雲端 AI 供應商皆承諾保護隱私,但對於具備嚴格合規要求的環境而言,將完整的歷史脈絡與企業 Know-how 留存在第三方伺服器上,始終存在資料外洩或被用於模型訓練的潛在風險。
奪回資料主權,採用 NAS 作為 AI 記憶庫的架構思考
如果我們能享受 Claude 或其他 AI 平台的強大推論能力,同時將記憶的物理儲存位置多一組放到本地端的設備或 NAS,可以平衡效能與資安合規。這種運算在雲,記憶在地的混合架構,在技術上是可行的。
技術實現路徑 (BYOC – Bring Your Own Context)
要在 NAS 上實現 AI 記憶託管,核心概念是建立一套本地化的檢索增強生成(RAG)系統:
我們可以先在本地實作向量資料庫(Vector Database),透過 NAS 上的 Docker 容器(如 Qdrant 或 Milvus),將使用者過去的對話紀錄、程式碼片段、技術文件轉化為向量嵌入(Embeddings)並儲存在本地硬碟中。
接著將中介層(API Gateway / Agent)在 NAS 上部署,我們可以透過輕量級的 AI 代理程式來實現。當使用者發出提示詞(Prompt)時,代理程式會先在本地 NAS 的向量資料庫中搜尋最相關的記憶與脈絡。
再來是動態注入(Dynamic Injection),可以將檢索到的本地記憶,與使用者的原始問題打包,透過 API 發送給 Claude 4.6。如此一來,Claude 每次運算都具備完整的上下文,但會話結束後,核心資料依然安穩地躺在自家的設備或 NAS 裡。
架構優勢與合規效益
CyberQ 指出,這樣的方式可以讓資料的自主掌控度提高,企業或個人可以實體切斷外部對記憶庫的存取。當合規政策(如 ISO 27701、GDPR 或特定產業的資安法規)要求刪除資料時,只需清空 NAS 上的紀錄,無須等待雲端供應商的同步週期,接著再去雲端刪掉相關資料即可。
我們也能夠進行阻斷未授權訓練,避免包含商業機密或零日漏洞(Zero-day)測試的對話紀錄,不會成為下一代大語言模型的訓練素材。另一個考量的點是無上限的記憶容量,雲端 AI 提供的記憶空間通常受限於 token 數量或平台配額,而 NAS 能提供 TB 級別的儲存空間,足以容納整個企業十幾年的開發文件與稽核歷史。
CyberQ 認為,Claude 4.6 Sonnet 透過開放的脈絡匯入與記憶功能,成功打破了 AI 服務的生態系壁壘。然而,在擁抱這些強大工具的同時,如果能將資料庫從雲端託管多一個 NAS 混合架構的型態,可以是未來高階使用者、資安人員與企業合規部門考量部署的下一步演進。








