隨著大型語言模型(LLM)技術的普及,本地端執行 AI(Local LLM)已經成為許多工程師與重度使用者的日常。本地部署的優勢不言而喻,零 API 訂閱費、無限 Token 吃到飽、加上極致的隱私保護,完全不怕機密資料外洩。
然而,當你想在自己的電腦上安裝最新開源的 Google Gemma 4、Llama 3 或是 Qwen 模型時,新手往往會面臨第一道勸退的高牆,市面上模型這麼多,我的電腦硬體到底跑不跑得動?
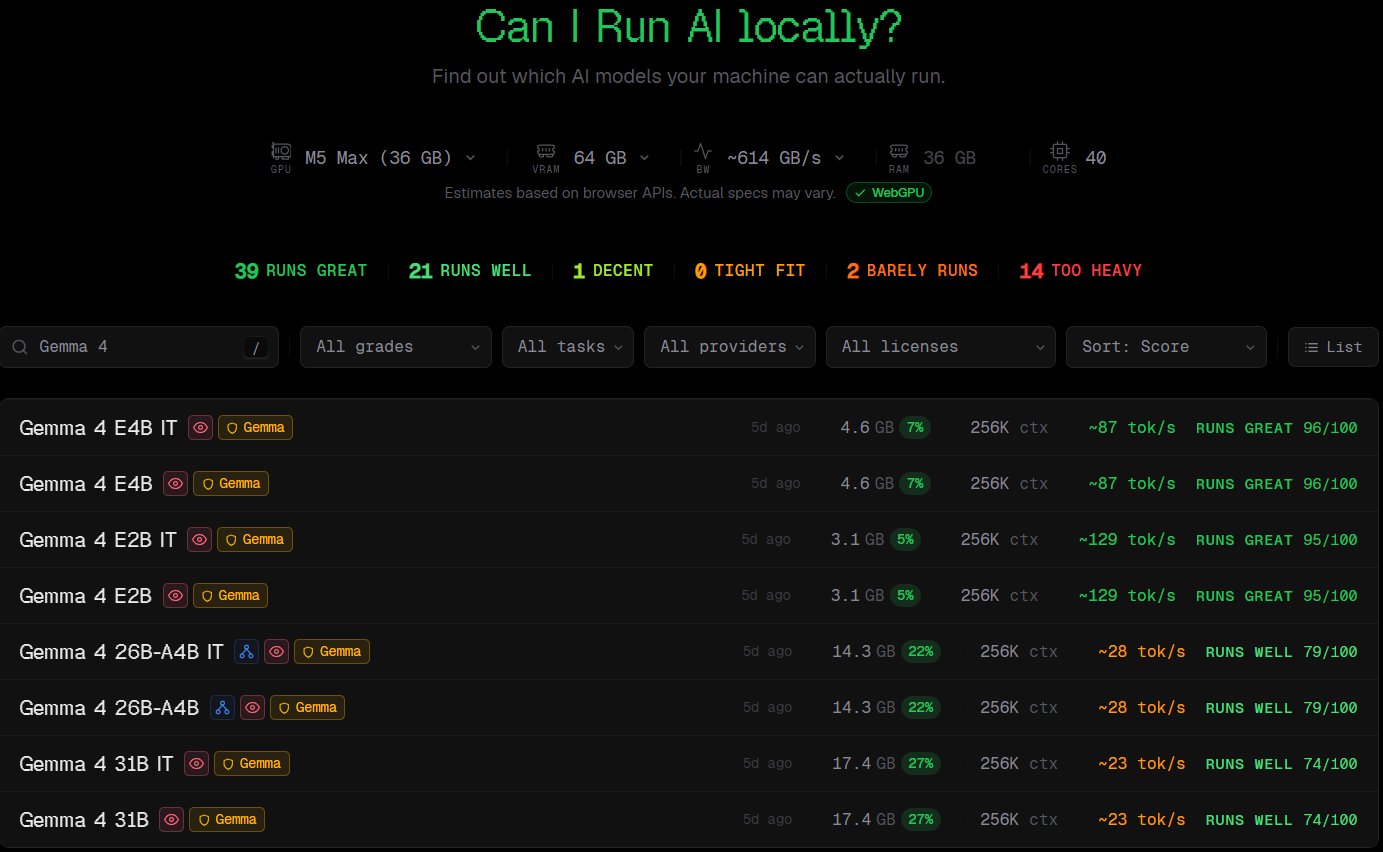
在過去你可能需要去各大論壇爬文、自己計算 VRAM(顯示記憶體)、研究艱澀的量化格式(Quantization)來做判斷。但現在呢,一個爆紅的免費網頁工具 CanIRun.ai 完美解決了這個問題,CyberQ 根據實作經驗評估過這個網站,它確實有做了很好的整理,連最新的 Gemma4 模型的評估資料都有,我們可以很快地用手邊的硬體規格在這網站查詢能不能夠順利執行相關模型,CyberQ 也根據這網站的資料,彙整出硬體的實測效能表格提供各位參考。
CanIRun.ai 核心功能就是讓你打開網頁,一鍵看透自己設備的 AI 戰力
CanIRun.ai 是一個純網頁端的 AI 硬體檢測與決策中心,最大的重點在於免安裝與全自動。CanIRun.ai 的核心邏輯在於利用瀏覽器的 WebGPU API 讀取使用者的硬體資訊。相比於手動查閱規格表或安裝探測軟體,這種做法帶來了極大的便利性。
| 檢測方法 | 傳統方法 (如 llmfit / 手動比對) | CanIRun.ai 網頁檢測 |
| 使用門檻 | 需下載軟體或熟悉命令列操作 | 極低,開啟網頁即可自動分析 |
| 跨平台支援 | 侷限於特定作業系統 (通常為 PC 或伺服器) | 支援手機、筆電、桌機等多平台 |
| 硬體讀取方式 | 本機系統層級 API 呼叫 | 透過 WebGPU API 讀取硬體環境 |
| 結果呈現 | 終端機介面 (TUI) 或純文字清單 | 網頁視覺化清單與推論速度估算 |
當你使用 Chrome 或 Edge 瀏覽器(註,Firefox 與 Safari 因隱私權限阻擋,較易導致硬體偵測失敗)打開網站時,它會透過最新的 WebGPU API 技術,瞬間自動讀取你電腦的底層硬體配置,包含,GPU 型號、VRAM 容量、記憶體頻寬(Bandwidth)與系統 RAM。
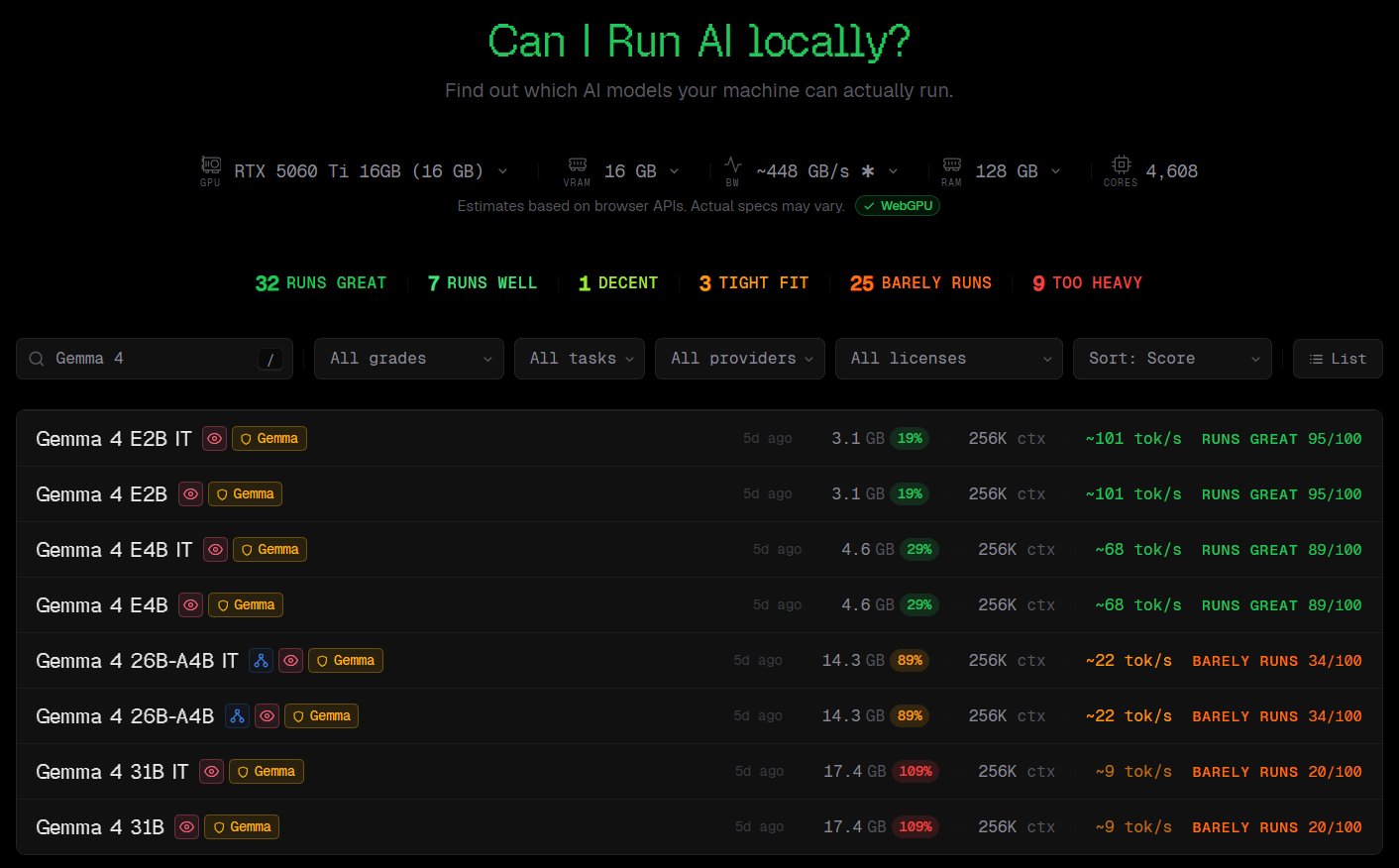
讀取完畢後,網站會從後台龐大的模型資料庫中(涵蓋 0.8B 的超輕量模型一路到上千億參數的巨型模型),即時運算出各個主流 AI 模型在你電腦上的預期表現,並估算出推論速度(Tokens / 秒),上圖就是自動偵測的結果,你可以再篩選指定的模型家族看跑起來如何,決定要下那些你可以跑得動的模型。。
資料呈現 S 到 F 的無情分級與硬體升級模擬器
根據最新的網站功能更新,CanIRun.ai 不只是一個檢測工具,更升級成了不錯的硬體採購指南。
為了讓大家更好理解,我們將網站的評分邏輯與實際體驗整理成下表 :
表一 CanIRun.ai 效能評分等級表
| 評分等級 | 網站狀態描述 | 實際體驗預估 (Token/s) | 適用應用場景 |
| S | Runs Great (運作極佳) | 約 20 ~ 800+ tok/s (肉眼難以追上) | 即時語音對話、即時編程輔助、長文極速摘要 |
| A ~ B | Decent (表現良好) | 約 10 ~ 19 tok/s (貼近一般雲端版體驗) | 日常問答、文案撰寫、邏輯推演 |
| C ~ D | Tight Fit (勉強運行) | 約 1 ~ 9 tok/s (字是一個個吐出來) | 背景自動批次處理、低頻率學術測試 |
| F | Too Heavy (無法負荷) | 記憶體溢出 (OOM) 或直接卡死 | 建議放棄,或改用參數量更小、量化更低的版本 |
除了自動檢測,網站近期最受歡迎的新功能是 GPU Comparison 硬體比較。買新顯卡前怕踩雷?你可以將自己目前的硬體,直接與夢幻清單上的硬體(例如頂規的 RTX 顯示卡或 Apple M 系列晶片)進行下拉式模擬比對,看看升級後生成速度能翻多少倍。
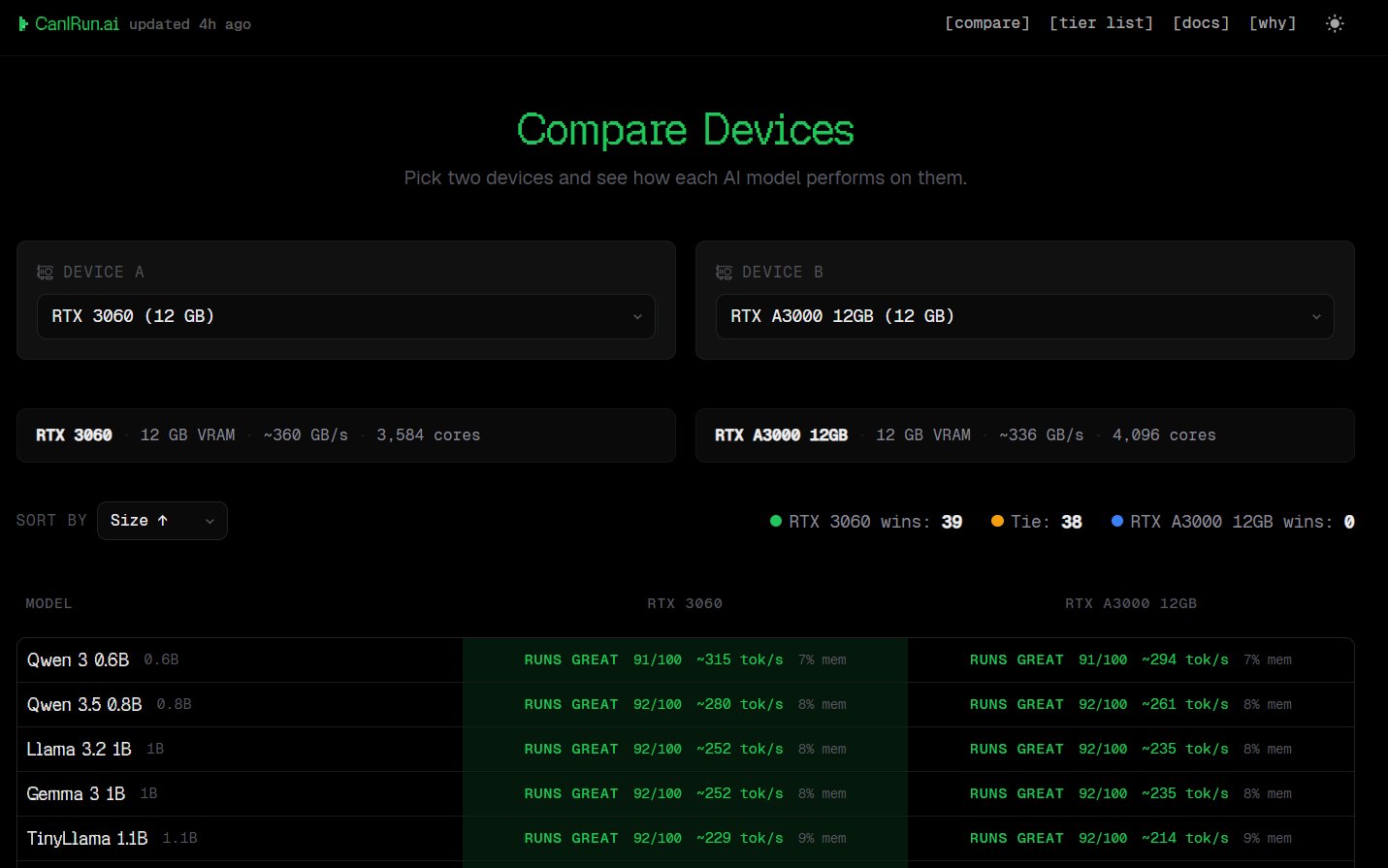
主流硬體 vs 最新 AI 模型實測成績舞台
CyberQ 實際在網站觀察最新估算資料與科技媒體的實測資料,彙整出目前最具代表性的硬體 vs 模型對應表現預估。
表二 主流設備 AI 模型推論效能實測預估 (結合最新硬體資訊)
| 測試硬體規格 | 輕量全能模型(例: Qwen 3.5 0.8B / Llama 3.2 1B) | 中量主流模型(例: Llama 3.1 8B) | 重量級進階模型(例: Qwen 3.5 35B) | 企業級大模型(例: Llama 3.3 70B) |
| 一般輕薄筆電 (無獨顯,依賴 CPU) | A 流暢可用 | E/F 極度緩慢 | F 無法執行 | F 無法執行 |
| Apple iMac (M4 晶片) (24GB 統一記憶體) | S 高達 156 tok/s | A 穩定約 19 tok/s | D 非常吃力 | F 記憶體不足 |
| 高階電競桌機 (RTX 5070 Ti, 16GB VRAM) | S 毫秒級回覆 | S 很順暢 | C/D 較慢 / 依賴量化 | F VRAM 爆滿無法跑 |
| 頂級旗艦顯卡 (RTX 5090, 32GB VRAM) | S 效能過剩 | S 非常順 | S/A 輕鬆應對 | B 具備實戰能力 |
| 頂規 Apple 工作站 (M5 Max, 128GB RAM) | S 飆升至 798 tok/s | S 非常順 | S 順暢執行 | A/B 穩定約 11 tok/s |
CyberQ 指出,從該網站資料可以發現,8B 參數模型是目前多數設備的黃金甜蜜點。此外,蘋果的 Unified Memory (統一記憶體) 架構在本地 AI 領域展現了極大的優勢。即便是地表最強的 NVIDIA 頂級顯卡 RTX 5090 (32GB VRAM),在遇到 70B 企業級模型時也會因記憶體限制而感到吃力,但擁有高達 128GB 記憶體的頂規 Mac,卻能依靠龐大的共用記憶體,從容吞下這些龐然大物。
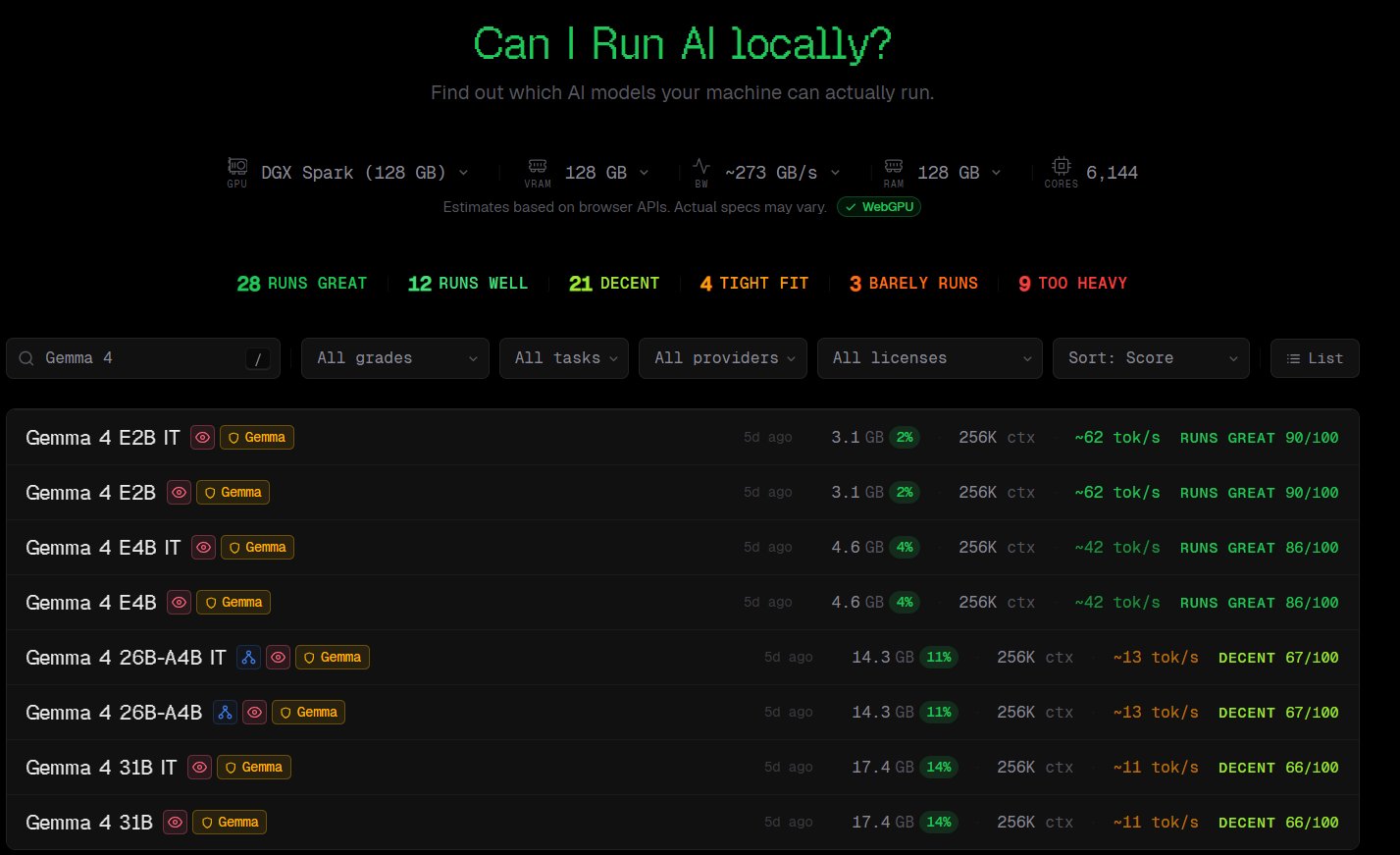
NVIDIA DGX Spark 可以應付大部分的模型,有疊加之後載入大模型的效果會更好。
CP 值相對高又好用的 Mac 系列電腦,只要記憶體夠大,載入大模型不是問題。
好用,但有隱藏陷阱
儘管 CanIRun.ai 被譽為新手一目了然的工具行網站,但 CyberQ 提醒幾個你使用該網站時必須注意的小細節。
1、Mac 用戶專屬的VRAM 誤判陷阱
由於瀏覽器 WebGPU 對硬體資源讀取的安全限制較為保守,網站經常會低估 Mac 電腦的 VRAM。例如,一台擁有 24GB RAM 的 M4 iMac 可能只會被網站預設偵測出 16GB VRAM,導致許多原本能跑的模型被誤判為Too Heavy (F)。
CyberQ 建議,請善用網站側邊欄的手動修改功能。建議 24GB RAM 的 Mac 用戶手動將 VRAM 參數上調至 18GB,128GB 的用戶可調整至 98GB,就能瞬間解鎖真實的 AI 模型潛力清單。
2、跑得動不等於夠聰明
CanIRun.ai 提供的是一份硬體的體能報告,解決了速度(Token/s)的檢測,但缺少了模型的智力測驗。目前工具無法告訴你這個模型適不適合寫 Code 或邏輯推理。我們是希望該網站或其他類似網站,能夠在未來把整合模型能力的基準跑分(Benchmark)也列出,提供更全面的選型建議。
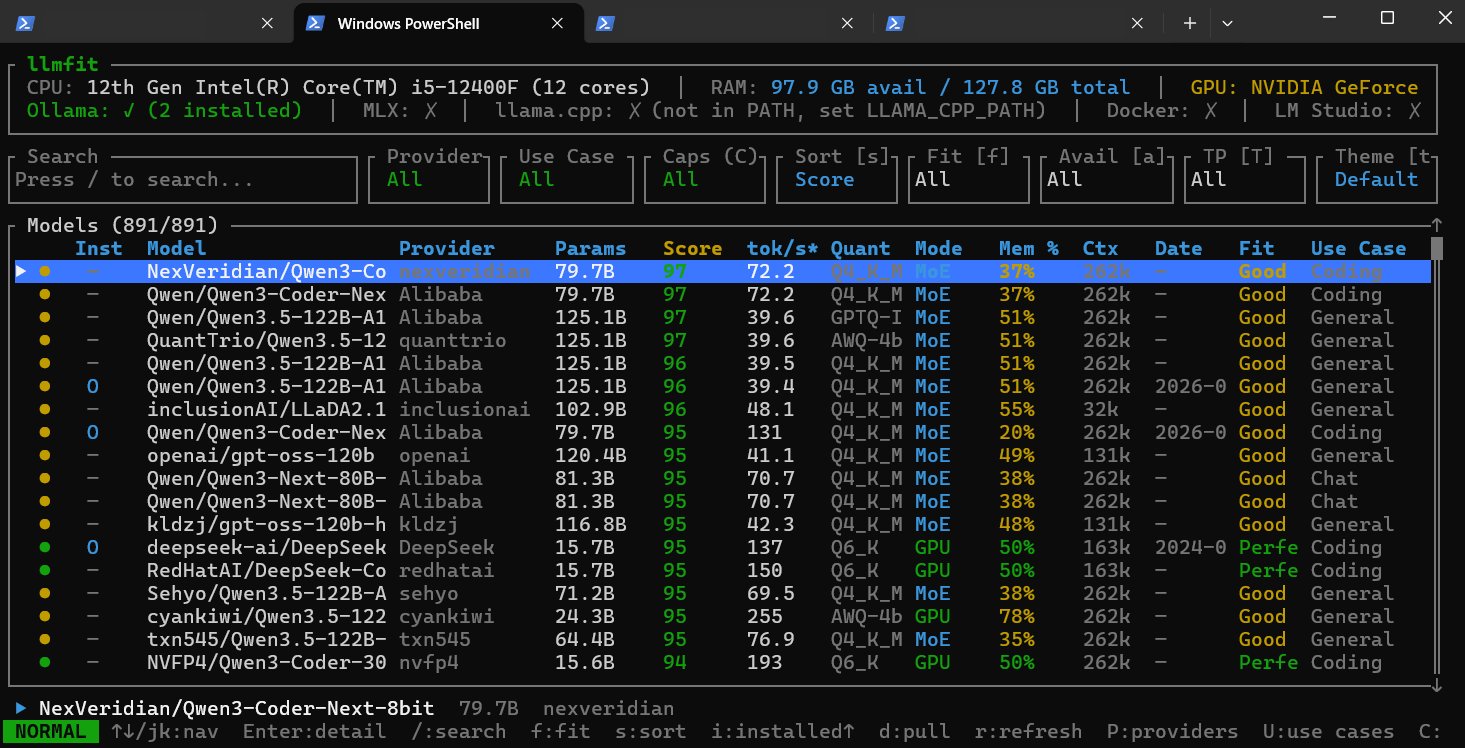
3、硬核玩家的替代方案,llmfit
如果你覺得網頁版不夠底層或精準,CyberQ 也推薦你用用看另一款命令列開源工具 llmfit。它不依賴瀏覽器 API,而是直接呼叫系統層(如 nvidia-smi)取得精確資訊,並提供你的硬體跑主流模型的效能,每秒多少 token 數的呈現,對於需要精準計算 MoE 模型記憶體卸載邏輯的高階玩家來說,是另一個值得參考的進階選項,自行評估會更精確一些。
踏出你 Local AI 世界的第一站
CyberQ 認為,在 AI 工具大爆發的時代,不把 AI 用到極致,就等著被淘汰的說法,確實只是一種誇大的市場恐慌。但是實際上,確實也有許多企業在採用末位淘汰制時,用 AI 輔助 review 工程師成果,甚至是檢視員工使用 AI 的程度,這些也早就不是新聞。
在花費大量時間下載動輒數十 GB 的模型和操作不當,導致電腦當掉,或是準備盲目砸大錢升級昂貴的顯卡之前,不妨先打開瀏覽器前往 CanIRun.ai,花十秒鐘健檢一下你的設備。讓資料顯示當前的狀態,協助你評估自己的設備或公司的設備,在追求本地 AI 自由的路上,是否可行,再來判斷能否省下的試錯成本與時間。
CyberQ 指出,未來最理想的發展方向,是將這類硬體偵測與模型搭配的邏輯,直接整合進本機端的開源工具中。例如,若 Ollama 能夠內建自動硬體篩選功能,讓開發者在命令列環境中,就能根據實際的硬體資源,無論是一般的 RTX 顯示卡,還是掛載了 NFS 網路儲存的 DGX 運算節點,去精準拉取並執行最合適的模型,既能兼顧準確性與效能最佳化,也能將硬體資料的安全管控確實留在本機環境中。