

OpenAI 日前推出了全新一代尖端 AI 模型 GPT-5.5,它被定位為專為真實工作與驅動代理 (Powering Agents) 打造的新型態智慧 AI 代理人,可以自主理解模糊目標、原生調用外部工具、自我糾錯,並且能堅持執行長時程任務的數位同事。
CyberQ 實測 GPT-5.5 ,確實深深感受震撼,類似剛發表不久的 ChatGPT Image 2.0 和 Claude Design 等帶來的衝擊。
我們的看法是,該公司標榜的所謂全自主 AI 代理,並不代表 AI 已經可以在完全沒有邊界、沒有監督、沒有權限控管的情況下獨立取代人類工作者。更準確地說,GPT-5.5 代表的可被交辦更多重要任務的新階段。它能理解較模糊的目標,拆解步驟、使用工具、檢查輸出,並在長時間任務中維持較高的一致性,減少過去大量的 AI 幻覺。這也是為什麼 OpenAI 在介紹 GPT-5.5 時,不只談模型跑分,而是反覆強調 coding、research、data analysis、document-heavy tasks 與跨工具工作流程。
官方基準測試成績佳,但 API 價格翻倍
過去的模型擅長寫短文或單次問答,而 GPT-5.5 則是專為解決多步驟、高複雜度的耗時任務而生。在維持與前代 GPT-5.4 相同延遲速度的前提下,它達成了驚人的 Token 效率與跑分突破。
| GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro | |
| Terminal-Bench 2.0 | 82.7% | 75.1% | – | – | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | – | – | – | – |
| GDPval (wins or ties) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | – | – | 78.0% | – |
| Toolathlon | 55.6% | 54.6% | – | – | – | 48.8% |
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| CyberGym | 81.8% | 79.0% | – | – | 73.1% | – |
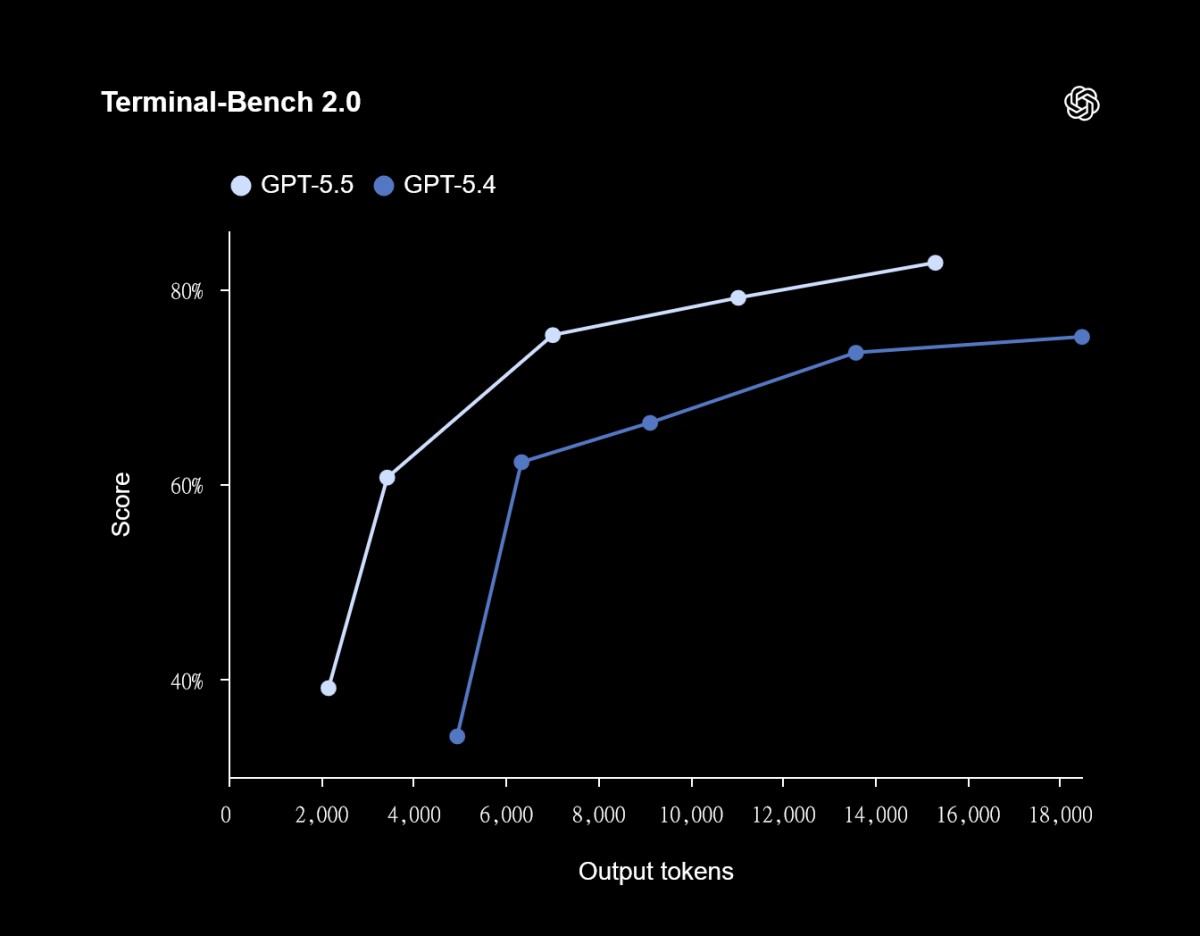
系統與電腦操作能力 (Terminal-Bench 2.0) GPT-5.5 拿下了高達 82.7% 的分數,展現極強的終端機環境導航與程式碼執行能力。
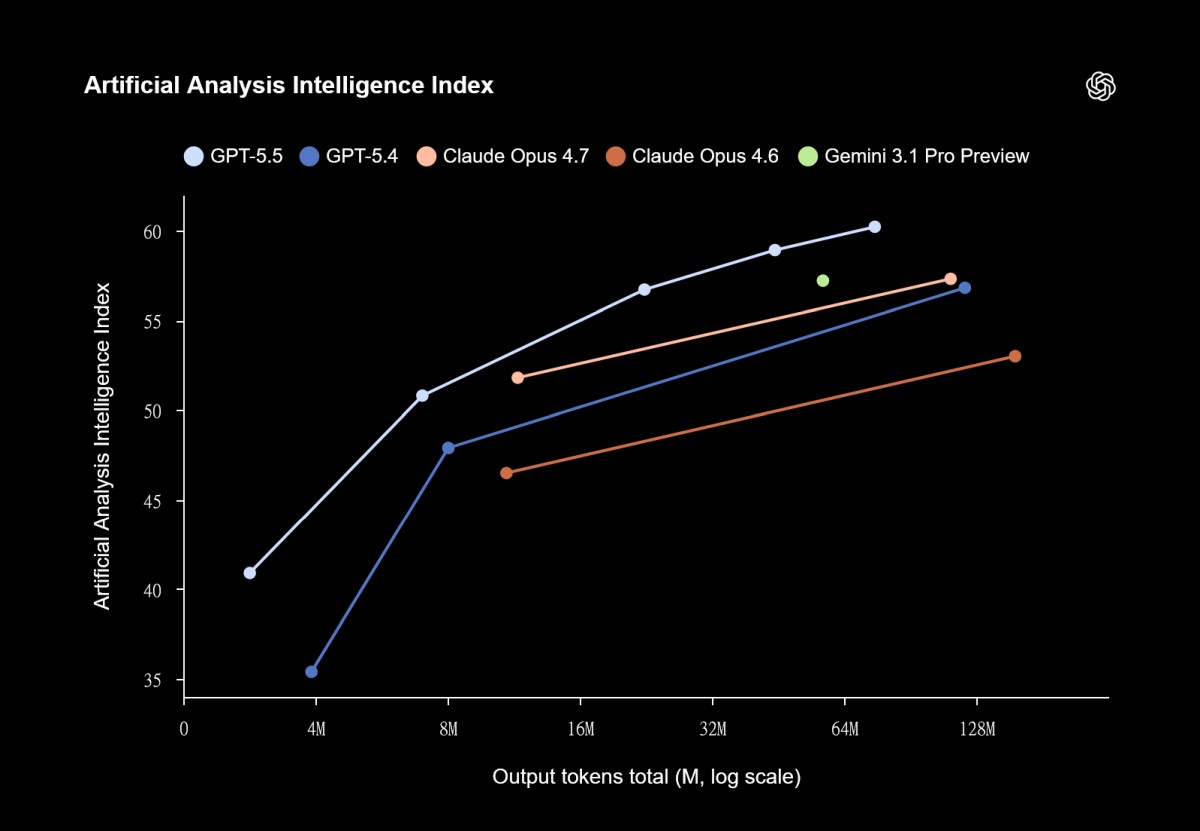
經濟價值與商業知識 (GDPVal) 的測試方面,它是一個評估 AI 在真實經濟職業任務表現的基準,GPT-5.5 以 84.9% 的勝率奪冠,大幅超越 Claude Opus 4.7 (80.3%) 與 Gemini 3.1 Pro (67.3%)。
至於高難度科學與極限測試,在物理、化學、生物的專家級測試 GPQA Diamond 中高達 93.6%,在允許使用工具的人類終極測驗 (Humanity’s Last Exam)中達到 52.2%(滿血版的 GPT-5.5 Pro 更高達 57.2%)。
高昂的 API 定價
不過新版的代價可不便宜喔,CyberQ 觀察,這次即將推出的 API 定價為 輸入 $5 / 輸出 $30(每百萬 Token),幾乎是前代 GPT-5.4 的兩倍,而算力更強的 GPT-5.5 Pro 更是高達 輸入 $30 / 輸出 $180。
從 GPT-5.5 的官方測試項目來看,真正值得關注的不是單一學科測驗分數,而是它在需要長時間操作、修正與驗證的任務上明顯變強。例如 Terminal-Bench 2.0 測的是複雜命令列工作流,OSWorld-Verified 則評估模型能否自行操作真實電腦環境,GDPval 更進一步測試 AI 在 44 種職業任務中的知識工作表現。
GPT-5.5 的 API 定價確實高,導入時不能只看模型能力,也必須重新計算每項工作流程的總成本。不過 OpenAI 的說法是,GPT-5.5 雖然單價更高,但在 Codex 等場景中因為更聰明、更有效率,可能用更少 Token 完成同樣任務,當然這是官方說詞啦,實際上的搭配和成本的控制,正在考驗各家 AI 架構師與ㄎ發主管、企業老闆的精算流程。
研究論文與安全防護採用史上最嚴格的系統報告與懸賞
伴隨強大自主能力而來的,是不可預測的風險。針對 GPT-5.5 在網路安全與生物技術上的潛在威脅,OpenAI 同步發布了兩項重要的安全文獻與計畫。
報告詳細記錄了模型發布前的紅隊演練(Red-teaming)過程。OpenAI 的系統報告指出,GPT-5.5 在寫程式、研究、文件與試算表、跨工具操作方面都有更強能力,同時在網路安全能力上也被視為需要更高等級防護的模型。這類模型對防禦者很有價值,例如協助漏洞分析、程式碼審查與系統強化;但若落入惡意行為者手中,也可能降低部分攻擊門檻。
CyberQ 認為這和 Anthropic 把之前發表的強大模型 Mythos 不對外發表,先交給大廠們加固軟體和平台類似,這些新版模型太強大,這會引起關於 AI 權限、身份驗證、資料邊界與監控機制的治理考驗。
為了防範模型被濫用於生化攻擊,OpenAI 開出高達 25,000 美元 的賞金,邀請全球資安專家在 Codex Desktop 專屬環境中,挑戰尋找能同時繞過五道生物安全防線的通用越獄 (Universal Jailbreak)提示詞。目前看起來, OpenAI 試圖把傳統資安界的漏洞揭露文化,延伸到 AI 生物安全與模型濫用風險管理。
企業導入與開發者實測
伴隨著模型逐步部署到 ChatGPT 與 Codex,CyberQ 也實測了 GPT-5.5 ,很喜歡它令人上癮的推理和實作能力。
另外,著名開發者 Simon Willison 等不及官方 API 全面開放,便透過逆向工程打造外掛,成功調用了半官方的 Codex API。他要求模型生成一張騎腳踏車的鵜鶘 SVG 向量圖,並強制開啟極高推理模式(-o reasoning_effort xhigh)。GPT-5.5 靜靜思考了將近 4 分鐘、消耗了高達 9,322 個內部推理 Tokens(預設模式僅需 39 個),最終跳脫常規,利用極度複雜的 CSS 漸層架構,刻畫出了一幅充滿細節的向量圖形。
這代表未來使用高階 AI 代理時,使用者可能需要像調校伺服器資源一樣,在速度、成本、推理深度與輸出品質之間做取捨。
NVIDIA 萬人企業級部署,除錯週期從數天降至數小時
在企業應用端,NVIDIA 宣布已在內部超過 10,000 名員工的電腦中 (OpenAI’s New GPT-5.5 Powers Codex on NVIDIA Infrastructure),部署了跑 GPT-5.5 的 Codex 代理 (他們比外界更早就部署和測試 GPT 5.5 了, NVIDIA 是 OpenAI 的重要股東和合作夥伴)。該系統執行於 NVIDIA 最新的 GB200 NVL72 叢集上。為確保資安,員工透過 SSH 連接安全的雲端虛擬機 (VMs) 讓 AI 處理資料(零資料外洩政策)。
NVIDIA 內部工程師驚嘆,過去需要耗費數天的複雜除錯週期,現在被壓縮到只需幾個小時內即可完成。
當勞動力轉化為無限資本
GPT-5.5 與 ChatGPT Image 2.0 等新品陸續發表後的驚人效果,讓人不禁思考經濟結構與未來的深度焦慮。
CyberQ 認為,目前的市場是建立在勞動力缺乏議價能力的前提上,可是呢,當企業的主要勞動力,開始由科技大廠的 AI 模型,它們可是一種不需要吃飯休息、且能隨時中斷服務的資本來提供勞務時,這將對傳統勞資關係將帶來很大的變化。
我們預期未來的勞動力市場將經歷巨大的轉變,整體雖然會可能大部分會是好的、正面的,大量改善各種工作流的進步與發展。但是呢,當中也會伴隨著不少社會陣痛與個人悲劇。人類的勞動價值會被重新討論與思考,部分工作者可能會轉移至 AI 無法輕易取代的實體與情感領域,比方說實體運動、健康管理、現場作業、手作、工藝與純藝術創作等等吧。
工作模式面臨的典範轉移
從測試成績到真實世界的實際使用的感想,CyberQ 認為 GPT-5.5 的發布真的越來越成功走向獨立工作者了,它的判斷能力與我們可以委託交辦的任務真的和以往大不同,這代表 AI 迭代的速度加快,終於有了相當的品質提升,OpenAI 在 2026 上半年的佈局十分精彩,讓人期待下半年各家在這個高水準領域的競逐。
我們的看法是,這會帶來效率紅利,也會帶來新的成本、治理與勞動分配問題, AI 代理正要逐步開始正式進入企業組織圖。無論你對其高昂的 API 定價感到卻步,還是對勞動市場的未來感到焦慮,這位不會喊累、甚至比你更懂底層架構的超級數位同事,已經要正式報到了噢。
首圖由 ChatGPT Image 2.0 所產生






