

隨著生成式 AI 應用持續火熱,訓練與推論間的硬體架構效率和生態系發展成為市場焦點。NVIDIA主導的GPU 市場正面臨 Google TPU 與 Groq LPU 的挑戰,三者在架構設計與應用場景上各有千秋,也牽動台灣供應鏈的佈局策略。
市場關注焦點逐漸從模型訓練(Training)轉向推論(Inference),如何在最短時間內產出準確內容,同時控制電力與硬體成本,成為各大廠角力的戰場。除了業界已經普遍熟悉的 GPU 之外,Google自行研發的 TPU 以及近期爆紅的 LPU,都代表著不同的技術路徑。
CyberQ 指出,市場格局已從單純的「硬體規格戰」轉變為「應用場景分工競爭」。NVIDIA x Groq 的布局,當然是改變過往試圖用 GPU 解決所有問題但耗電的情況,轉向「混合架構」,試圖同時吃下高吞吐量的訓練市場與極低延遲的推論市場,以及在與 TPU 陣營的競爭中保有更多市場競爭力。
以下是我們針對 GPU、TPU 與 LPU 的比較:
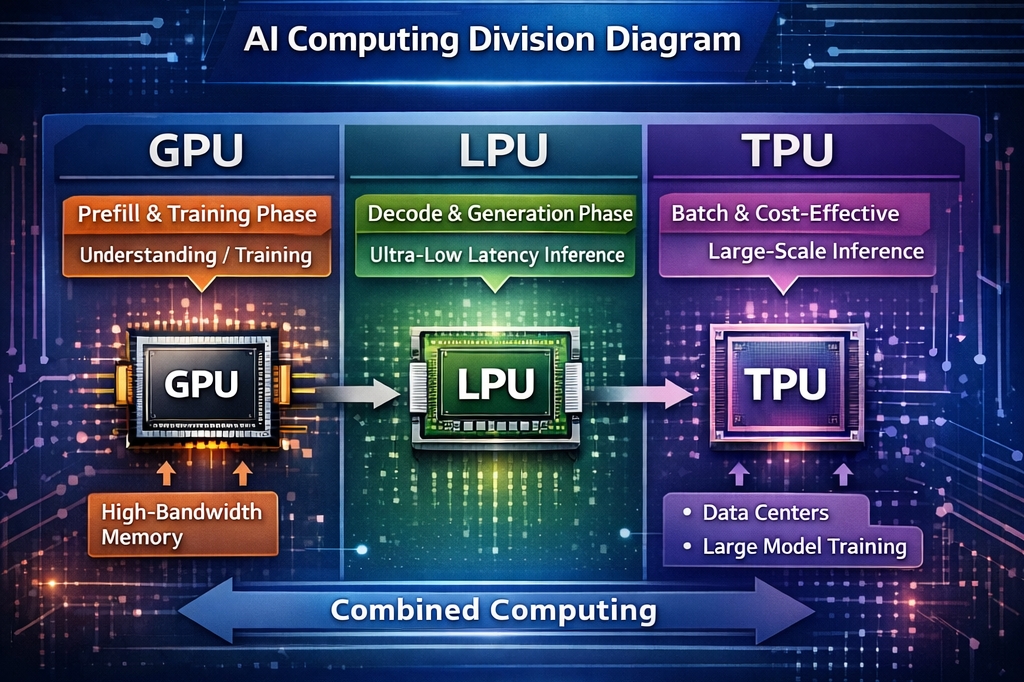
GPU 通用運算的王者與記憶體瓶頸
NVIDIA 依然是 AI 訓練的絕對霸主。但面對推論需求暴增,NVIDIA 其實正在面對這個問題, GPU 的 HBM(高頻寬記憶體)架構在「單一使用者即時推論」上存在物理瓶頸。GPU 最初是為了處理影像繪圖而生,具備大量平行運算核心。由於AI深度學習本質上是大量的矩陣運算,與圖形處理邏輯相似,因此NVIDIA 透過 CUDA 軟體生態系的整合,讓GPU成為目前AI領域最主流的硬體。
GPU 的優勢在於通用性極高。無論是訓練龐大的大型語言模型(LLM),還是執行後端的推論任務,GPU都能勝任。然而GPU高度依賴高頻寬記憶體(HBM)來傳輸資料。隨著模型參數量越來越大,記憶體頻寬往往跟不上運算核心的速度,形成所謂的記憶體牆(Memory Wall),這也是為何 HBM 產能會直接影響 AI伺服器出貨的主因。
架構弱點在於,GPU 依賴複雜的硬體動態調度(Dynamic Scheduling),資料流向需即時指揮,這在處理需要極速反應的「生成階段」時會產生不可預期的延遲。
未來在新的混合架構中,GPU 可以主力去專注於 Prefill(預填充/理解) 階段。憑藉其強大的平行運算能力,負責在第一時間消化使用者輸入的大量提示詞(Prompt)。
目前 NVIDIA 與 AMD 皆為採用此架構的主力廠商,台灣供應鏈受惠程度相對較深,包括晶圓代工龍頭台積電的 CoWoS 先進封裝、以及負責伺服器組裝的廣達、技嘉、緯穎與鴻海(鴻佰)。
TPU Google專為矩陣運算打造的ASIC
TPU 是Google為了自家TensorFlow機器學習框架所量身打造的特殊應用積體電路(ASIC)。不同於GPU需要兼顧繪圖等多種用途,TPU的設計目標相當單純,就是為了加速矩陣乘法運算。
Google 的 TPU 是目前唯一能與 NVIDIA 抗衡的獨立生態系。最新的 Gemini 3 模型完全在 TPU 上訓練,且包括 Meta 等雲端業者正採購 Google TPU 算力與 Infra 架構 ,這顯示 TPU 已從 Google 自家用走向提供給外部業界使用。
核心優勢是採用脈動陣列(Systolic Array)架構,專精於矩陣乘法。資料在晶片內部流動的路徑經過高度最佳化,大幅減少存取資料的次數。這讓 TPU 在執行特定 AI 負載時,能展現出比 GPU 更高的能源效率。雖然在通用性上不如 GPU,但在大規模部署的「推論成本」上具有顯著優勢,成本約為 GPU 的 20%,但考量其他整體成本可能會再更高些。Google 目前在內部的搜尋引擎、翻譯以及 Gemini 模型的訓練與推論上,均大量採用 TPU。
未來定位將繼續是雲端巨頭的護城河,Google 透過「晶片+模型+雲端」的一條龍策略,提供比 NVIDIA 更具性價比的大規模推論服務,特別適合不需要極致低延遲但需要處理大量客戶端請求的場景。
由於 TPU 並不對外單獨販售晶片,公司必須透過 Google Cloud 才能使用TPU算力。在供應鏈方面,台積電負責晶片製造,而緯穎則是 Google 在 TPU 伺服器機櫃系統整合上的長期合作夥伴。
LPU 以速度突圍的推論專家
近期由新創公司 Groq 提出的語言處理單元(LPU),則是完全針對大型語言模型推論(Inference)所設計的架構。LPU 的最大特點在於捨棄了昂貴且複雜的 HBM,改為在晶片內部整合極大容量的靜態隨機存取記憶體(SRAM)。雖然 Groq 維持形式上的獨立,但核心技術已授權給 NVIDIA,這被視為一種「捕獲並扼殺」(Catch and Kill)的策略,但也確立了 LPU 技術的價值。
LPU 的核心技術靈魂在於前述的 SRAM 與 Compiler(編譯器),資料路徑在編譯時就已「排好時刻表」,較能實現確定性(Deterministic)運算。
這種設計讓 LPU 在處理資料時,不需要等待外部記憶體的傳輸,能夠實現極致的低延遲與高吞吐量。根據實測,LPU 在生成文字的速度上遠快於傳統 GPU 架構,特別適合需要即時互動的語音對話或聊天機器人應用。換言之,LPU 解決了 GPU 在推論時的延遲問題。
未來有機會在市場上專攻 Decode(解碼/生成) 階段。當 AI 開始逐字生成回應時,將由整合了 LPU 技術的模組接手,提供如高鐵般的極速體驗。
GPU TPU與LPU 關鍵比較
為了更清晰理解三者差異,以下列出關鍵比較:
| 比較項目 | GPU (圖形處理單元) | TPU (張量處理單元) | LPU (語言處理單元) |
|---|---|---|---|
| 技術定位 | 通用型AI運算王者 | Google專用ASIC | 專為LLM推論設計 |
| 核心優勢 | 生態系完整(CUDA)、訓練與推論皆可、高吞吐量 | Google Cloud深度優化、矩陣運算效率高 | 極致低延遲、採用SRAM架構解決記憶體頻寬瓶頸 |
| 主要應用 | AI模型訓練(Training)、通用推論、繪圖 | Google內部業務(Search, YouTube)、Google Cloud AI | 即時生成式AI(Chatbot)、語音互動、高頻推論場景 |
| 記憶體架構 | 高度依賴HBM(高頻寬記憶體) | 依賴HBM | 依賴SRAM(晶片內記憶體)、不依賴HBM |
| 全球代表大廠 | NVIDIA、AMD | Google (Alphabet)、Broadcom (協助設計) | Groq (目前主要定義者) |
| 台灣受惠供應鏈 | 晶圓代工: 台積電 (CoWoS先進封裝是關鍵) 伺服器: 廣達、鴻海(鴻佰)、緯穎、技嘉 IP/ASIC: 世芯-KY、創意 | 晶圓代工: 台積電 伺服器: 緯穎 (Google主要合作夥伴)、廣達 | 網通與模組: 智邦 (晶片互連交換技術)、鴻海 (伺服器組裝) 潛在受惠: 專注於ASIC設計服務業者 |
| 投資風險與觀察 | HBM產能缺口、高耗電問題 | 僅限 Google 生態系與資料中心 Infra、外部無法直接採購硬體 | 晶片製造目前由三星 (Samsung) 拿下主要代工單、SRAM容量限制模型大小 |
混合架構將成未來常態
CyberQ 觀察,GPU、TPU 與 LPU 並非零和遊戲。未來 AI 資料中心將走向混合架構,AI 算力市場也有可能會呈現「NVIDIA 混合體(GPU+LPU)」競合「Google(TPU)與其他共通或個別自研客製化 AI 晶片生態系 」的局面一段時間,直到更有效率的架構和合作方法出來又會是新的局面了。
要特別注意的是 Groq 的 LPU 並非獨家授權給 NVIDA,意味著其他廠商也能夠與之合作產生有意思的產品線來,這點很值得觀察。
NVIDIA 藉由技術授權,試圖打造一個「既能載重(訓練)又能跑快(推論)」的新生態,而 Google 和產業其他廠商、合作夥伴與競爭者們,預期會繼續利用 TPU 的成本優勢,築起雲端服務的護城河。
市場的觀察重點除了算力大小,包括推論成本與能源效率的最佳化指標,正隨著越來越多 AI 應用落地而有了不同各擅其場的風貌。
首圖由 Google Nano Banana AI 生成








