

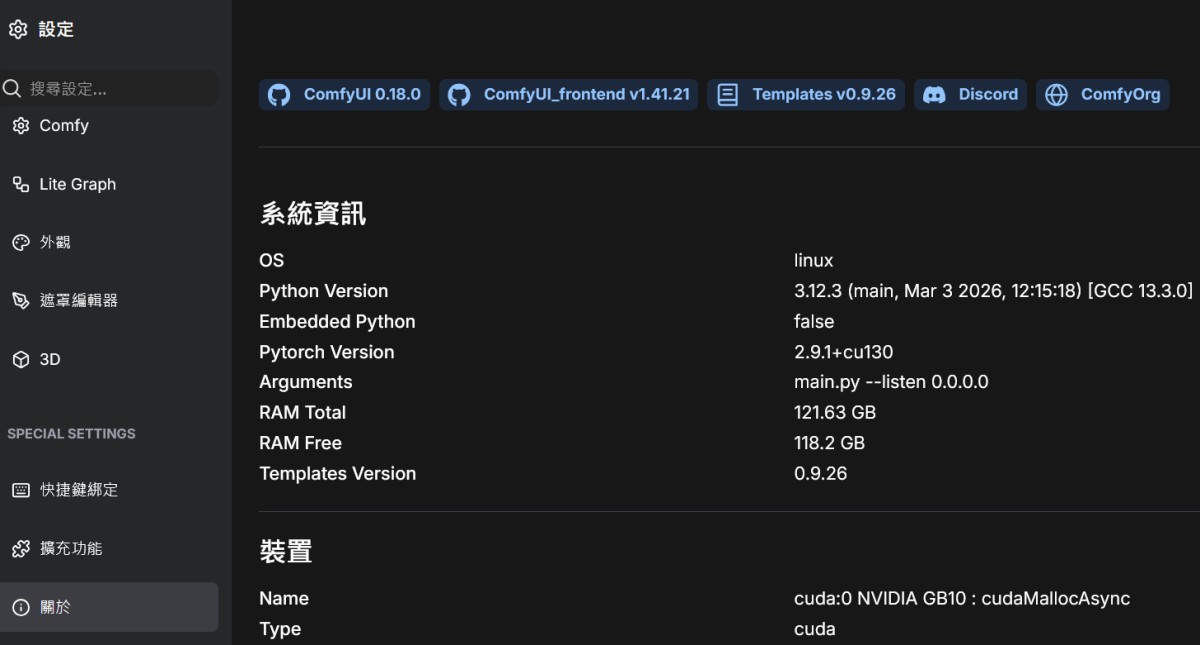
知名 AI 繪圖與節點式生成工具 ComfyUI 正式推出了 v0.18.0 版本。作為廣受 AI 開發者與創作者青睞的開源專案,本次更新不僅在核心效能與顯示記憶體(VRAM)的管理有強化,並改善對 AMD GPU 的支援,還針對多種模型精度(如 MXFP8、FP16)與外部 API 節點提供了更完善的實作。
對於時常面臨系統資源瓶頸的使用者而言,這次的更新精準解決了許多記憶體耗盡(OOM)的關鍵問題。CyberQ 實測 ComfyUI v0.18.0,也彙整理本次 v0.18.0 版本的核心重點。
記憶體與 VRAM 消耗大幅下降
在處理高解析度影像或影片生成模型時,記憶體管理一直是開發者的主要挑戰。本次更新在記憶體釋放與 VAE 處理機制上進行了深度最佳化:
LTX 與 WAN VAE 的 VRAM 最佳化:針對 LTX 與 WAN 影片生成模型的 VAE 進行了深度的 VRAM 佔用縮減,並透過分塊編碼器(chunked encoder)與 CPU IO 分塊技術,大幅減少記憶體峰值,有效拯救許多原本會導致 OOM(Out of Memory)的生成情境。
原地處理(Inplace Processing)機制:採用原地 VAE 輸出處理技術,進一步降低執行過程中的最高 RAM 消耗。
RAM 壓力釋放策略:更新至 comfy-aimdo 0.2.12,改進了系統的 RAM 壓力釋放策略,特別針對 Windows 環境帶來了顯著的速度提升。
多精度支援與底層運算升級
為了在生成品質與硬體資源之間取得更好的平衡,v0.18.0 引入了更多彈性的資料型態(dtype)支援:
新增 MXFP8 支援:正式支援 MXFP8 精度,提供更高效的運算選擇。
FP16 中間值運算:新增 –fp16-intermediates 啟動參數,允許在模型運算過程中強制使用 FP16 來處理中間值。同時,包含 EmptyLatentImage 與 EmptyImage 節點也已同步調整,以遵循中間層的資料型態與設備設定。
AMD 硬體支援擴展:針對 AMD gfx1150(Strix Point)架構啟用了 Pytorch Attention 支援。
Trainer 訓練模組升級:原生支援 FP4、FP8、FP16 訓練,並加入了量化線性層的自動微分(autograd)功能。
系統穩定性與 UI 介面改進
除了底層效能,前端介面與資料安全性也獲得了實用性升級:
使用者資料安全:針對 userdata 引入了「原子寫入(atomic writes)」機制,能有效防止應用程式崩潰或當機時造成的資料遺失。
前端快取防呆:設定了 no-store 快取標頭,防止前端載入過期的程式碼區塊(stale chunks),確保使用者介面始終保持最新狀態。目前前端套件已更新至 1.41.21。
Essentials 專屬分類:為節點與藍圖新增了 essentials_category,讓 Essentials 分頁的分類更加直覺與整潔。
API 與外部節點整合
對於將 ComfyUI 作為後端引擎的開發者,本次更新也豐富了 API 節點的生態系:
外部快取 API:新增 CacheProvider API,正式支援外部的分散式快取服務。
新節點支援:修復並更新了騰訊(Tencent)的 TextToModel 與 ImageToModel 節點,同時新增了 Quiver SVG 相關節點。
API 節點擴充:在 Nano Banana 2 API 節點中新增了對「thought_image」的支援。
模型棄用:將 seedream-3-0-t2i 與 seedance-1-0-lite 標記為棄用(deprecated),建議開發者及早移轉。
有誠意的效能升級
CyberQ 指出,ComfyUI v0.18.0 是一次極具誠意的效能升級。無論是透過 –fp16-intermediates 節省運算資源,還是針對 LTX 等大型 VAE 的記憶體極限瘦身,都為本地端執行 AI 模型的玩家提供了更流暢的體驗。如果您的硬體資源有限,或是時常處理大量高解析度生成的專案,強烈建議進行本次更新。
相關連結:
ComfyUI v0.17.0 至 v0.18.0 完整差異比較





