

由 Dongchao Yang 等 28 位研究人員組成的團隊,近日發布了名為 HeartMuLa 的開源音樂基礎模型家族。這項研究完全由學術界完成,結果卻展現出能與 Suno 等商業大廠相抗衡的生成品質,為開源社群注入了一劑強心針。
打破商業壟斷的開源新星
過去高品質的音樂生成模型多由商業公司把持,技術細節往往不對外公開。HeartMuLa 的出現卻改變了這個現狀。研究團隊指出,這是首度證明僅利用學術規模的資料與運算資源,也能重現出商業級別的音樂生成系統。
HeartMuLa 並非單一模型,而是一套完整的解決方案,主要的任務是推進大規模音樂理解與生成的發展。該專案目前已在 GitHub 上開源,並採用 Apache 2.0 授權,允許開發者與研究人員自由使用與修改,這對於推動音樂 AI 產業的發展具有指標性意義。
下圖是 HeartMuLa 公布的測試成績,可以看到以開源模型來說,它的成績已經不輸商業 AI 音樂頂尖模型 Suno v5,相信未來在經過社群貢獻與更多次的迭代後,會有更多可能的發展。
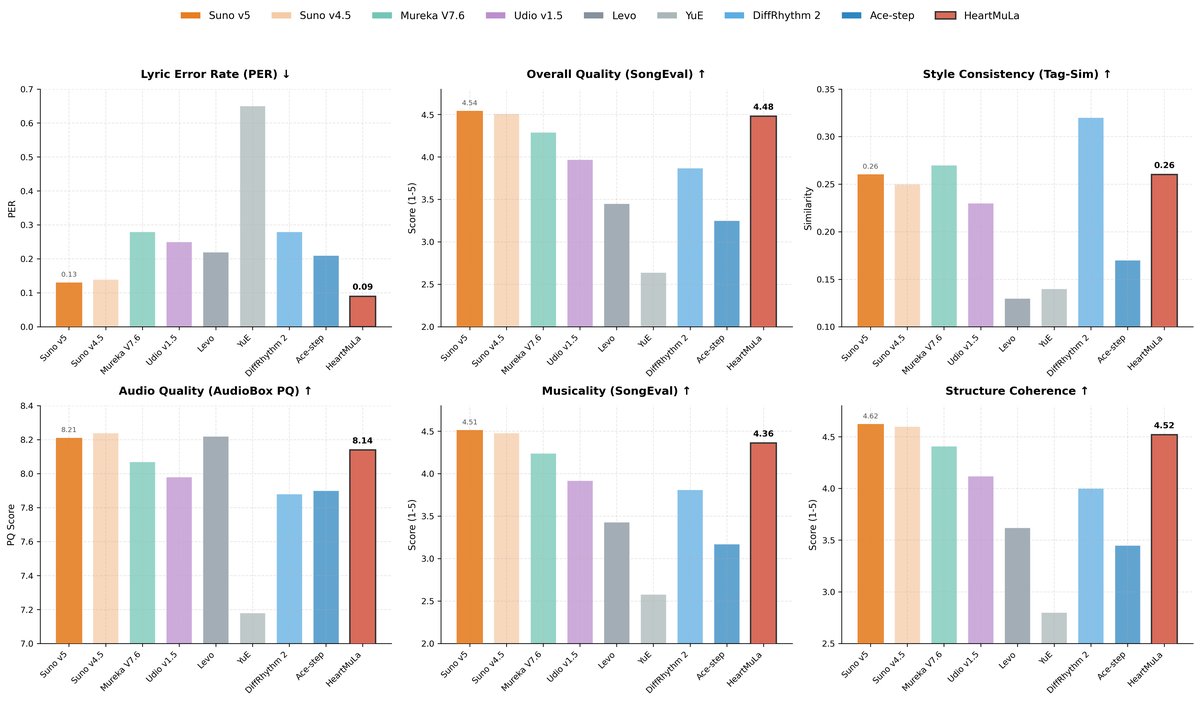
(Figure Credit:HeartMuLa )
四大核心組件解析
HeartMuLa 的強大能力來自於其精心設計的四大核心組件,這些組件共同協作,涵蓋了從理解到生成的各個環節。
其中 HeartCLAP 是一個音訊與文字對齊模型,負責理解音訊內容與文字描述之間的關聯,為精準的生成控制打下基礎。HeartTranscriptor 則是專為真實音樂場景最佳化的歌詞辨識模型。即使在複雜的背景音樂下,也能準確辨識歌詞,提高歌詞生成的連貫性。
再來是 HeartCodec ,這是一款特殊的音樂編解碼器,能以極低的 12.5 Hz 頻率運作,並擷取足夠長度的音樂結構,因此它能用更少的資訊量保留更豐富的音樂細節,大幅提升了生成效率。
最後是 HeartMuLa ,基於大型語言模型(LLM)構建的歌曲生成核心,能根據豐富的使用者條件例如文字描述、歌詞、參考音訊等合成高傳真音樂。
突破性的細粒度控制
HeartMuLa 與其他現有的開源模型相比,最顯著的特點在於其對音樂生成掌控的精細度。之前的 AI 音樂生成 AI 多半屬於粗粒度操作,使用者只能給予模糊的大方向,像是給我一首悲傷的流行歌,成品往往如同開盲盒,無法控制細節,結果也難以預測。
HeartMuLa 則導入了細粒度音樂屬性控制(Fine-grained Music Attribute Control),將控制權交還給使用者。 透過這項技術,使用者能像音樂製作人般,精準定義時間軸上的每一個環節。你可以明確指令模型 0 到 10 秒為鋼琴獨奏的前奏,11 秒開始加入小提琴伴奏,並在 30 秒時進入節奏強烈的副歌。
這種對結構、樂器編排與時間點的精確拆解,讓 AI 音樂生成從單純的靈感產生器,進化為具備生產力的創作工具。模型還提供了專為社群媒體設計的短影音生成模式,讓使用者能快速產出能讓人有記憶點的背景音樂。
HeartMuLa 還展現了良好的擴展性,研究顯示當模型參數擴展至 70 億時,性能呈現顯著提升,特別是在歌詞可懂度方面,其英語歌詞的錯誤率可低至 0.09,在複雜編曲下依然清晰可辨。
AI 音樂未來展望
CyberQ 認為,HeartMuLa 證明了高品質音樂生成不再是大廠的專利,發布後旋即在開發者社群引發討論,並被技術媒體 GitHub Awesome 選入今日熱門榜單,顯示其低資源、高品質的特性非常符合目前 AI 音樂開發者所需。
隨著 HeartMuLa 的開源,我們可以預見未來會有更多基於此架構的創新應用誕生,無論是輔助音樂創作、影視配樂,還是互動式娛樂體驗,都將迎來更多新的可能性。
首圖由 Nano Banana AI 生成








