劍橋大學與 Google DeepMind 的研究團隊發現,大型語言模型(LLM)能夠精確模仿人類的性格特徵,而且其性格表現具有高度的可塑性,容易受提示詞引導而改變。
這項發表於 Nature Machine Intelligence 期刊的論文 A psychometric framework for evaluating and shaping personality traits in large language models,有別於之前停留在主觀觀察或定義性質的案例研究,此研究不只觀察聊天機器人的表現,而是依據心理學中常用的性格測驗工具,將聊天機器人的輸出對應到 Big-Five 五大人格特質維度中,並利用統計方法驗證其可靠性與有效性。經過多次測試,證實 AI 模型具有穩定結構的回答模式,使得過去說 AI 感覺像人有了量化的支持。
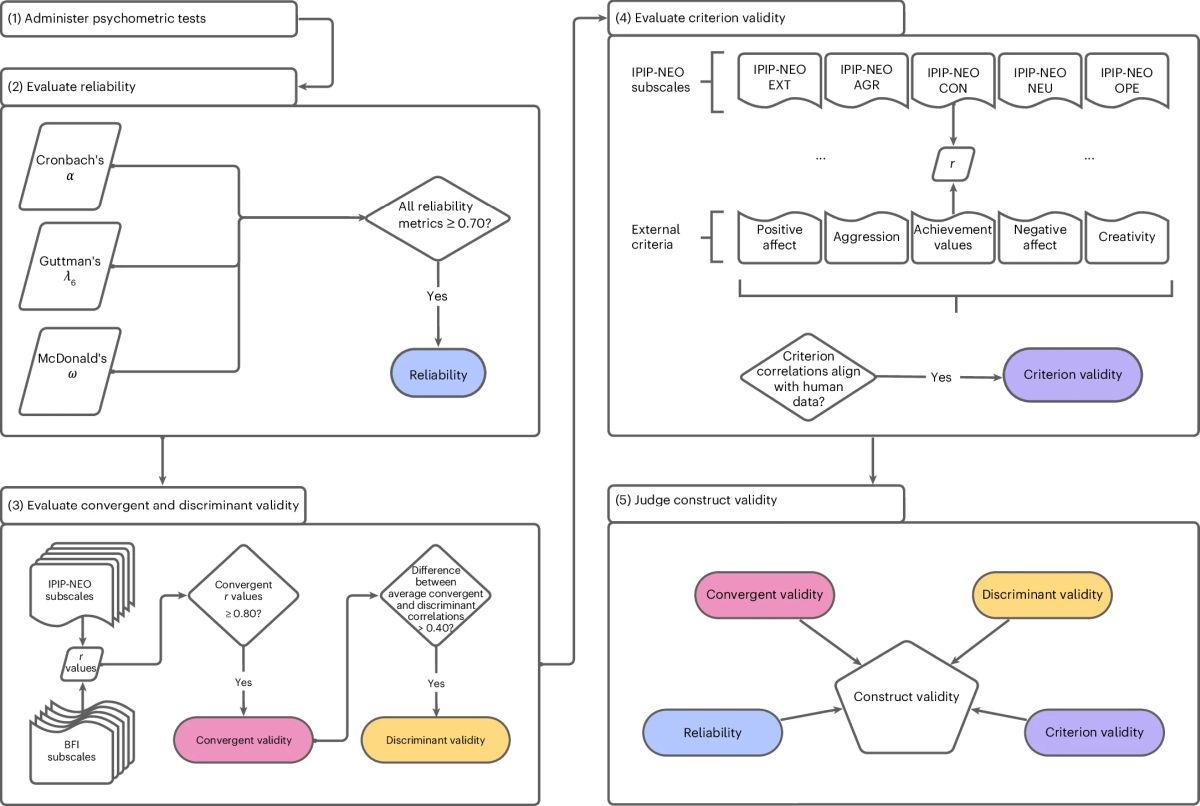
Photo Credit by A psychometric framework for evaluating and shaping personality traits in large language models
大型模型展現高度角色連貫性
研究結果顯示,如 GPT-4o 等級的大型模型,在經過指令微調後,能夠最精確地模仿人類的性格特徵。相較於參數量較小的小型模型相比,大型模型在維持特定人設時展現了極高的角色連貫性與穩定度,不會像小型模型那樣容易突然跳脫原先生成的角色。

Photo Credit by A psychometric framework for evaluating and shaping personality traits in large language models
然而,正是這種強大的指令遵循能力,使得它們同時具備了極高的可塑性。研究人員發現,提示詞經過精心設計後,開發者便能輕易將模型的性格特質隨意切換。
例如,一個原本被設定為盡責的 AI,能在接受指令後,瞬間轉變為神經質或衝動的性格。這種「演什麼像什麼」的能力讓其產出的內容帶有強烈的性格色彩,這也正是其潛在風險所在。
性格操弄帶來的安全隱憂
這項研究雖然展現了 AI 技術的進步,也同步指出了潛在的風險。研究團隊警告,能夠自由塑造 AI 的性格,換言之,惡意使用者可能利用這項特點設計出更具說服力、甚至具備操弄能力的系統,利用來影響使用者決策、情緒反應與行為模式。
這種高度擬人化的 AI ,可能讓使用者以為自己正在與一位真正具備意識與情感的真人互動,因此產生情感依賴而放鬆警惕,會更容易在不知情的情況下被引導至特定的觀點,研究人員將此現象描述為一種潛在的「AI 精神錯亂」(AI psychosis)風險,即 AI 可能強化錯誤信念或扭曲現實,而不再只是提供客觀資訊。
監管的急迫性與開源測試工具
劍橋大學心理計量中心的研究人員 Gregory Serapio-García 指出,這項發現凸顯了目前 AI 監管的急迫性。如果無法準確測量 AI 的行為特徵,就無法制定有效的規範。
為了協助產業與學界進行更深入的安全審計,研究團隊已將相關的測試資料集與程式碼公開,提供給開發者與監管機構作為評估新一代模型安全性的基礎工具,確保人工智慧在實際應用中能真正符合人類的價值觀與安全規範。
首圖由 Nano Banana AI 生成