

在開源 AI 社群中,如果說 Ollama 是讓大語言模型「飛入尋常百姓家」的親民推手,那麼 vLLM 則是支撐企業級高吞吐服務的幕後巨人。
就在幾天前,vLLM 團隊釋出 vLLM-Omni。這對於手握 DGX 等高階算力的開發者來說,意味著以前需要串接 Whisper (STT) 和 TTS 的複雜語音互動流程,現在可以在一個模型內、以極低的延遲完成。
vLLM-Omni:打破模態的高牆
過去我們使用 vLLM,著眼於它的 PagedAttention 技術,解決了 KV Cache 的記憶體碎片化問題,讓推論速度與併發量(Concurrency)提升。但長久以來,vLLM 主要聚焦於 LLM(純文字模型)。
這次的 vLLM-Omni 更新,核心在於對 Audio-to-Audio 和 Video-to-Text 的原生支援。
技術亮點:
端對端(End-to-End)處理: vLLM-Omni 支援像 GPT-4o 或 Qwen2-Audio 這類模型,直接輸入音訊特徵(Audio Tokens)並輸出音訊特徵。這意味著我們不再需要「語音轉文字 -> LLM 思考 -> 文字轉語音」的冗長管線(Pipeline)。這帶來的直接效益是極致的低延遲,對於打造即時語音助理至關重要。
多模態的 PagedAttention: vLLM 團隊將記憶體最佳化技術移植到了視覺與聽覺的 Token 上。在處理長影片或長對話錄音時,vLLM-Omni 能比傳統 HuggingFace Transformers 節省約 40%-60% 的 VRAM,這對於只有 16GB VRAM(如 RTX 5060 Ti)的邊緣設備來說,是能否跑得動多模態模型的關鍵。
張量並行(Tensor Parallelism)的擴展: 對於使用 DGX Spark 或多卡環境的用戶,vLLM-Omni 能自動將巨大的多模態模型切分到多張 GPU 上。這一點在處理 70B 以上的視覺模型時尤為重要,是目前 Ollama 較難以企及的效能領域。
vLLM vs. Ollama
隨著 vLLM 支援多模態,許多開發者會問:「我該選 vLLM 還是 Ollama?」
事實上,兩者的賽道雖然重疊,但核心哲學截然不同:
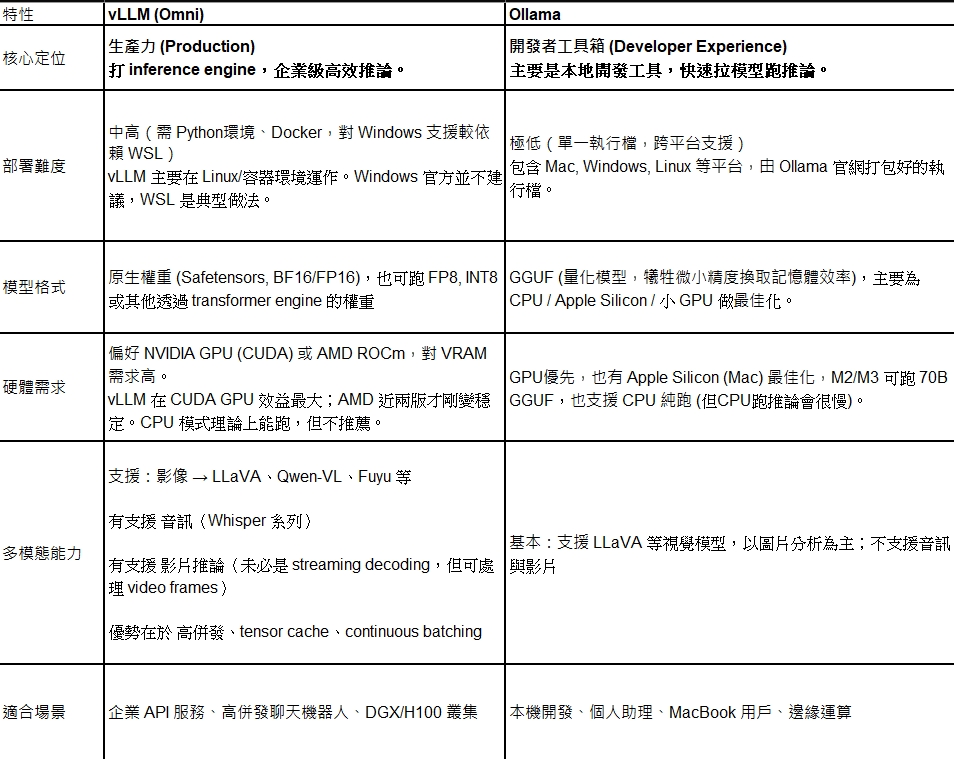
CyberQ 建議,如果你手邊有一台 DGX Spark 或是多張高階顯卡,且目標是服務多個使用者(例如公司內部的 AI 客服),vLLM 是唯一解。它的吞吐量(Throughput)是 Ollama 難以比擬的。
但如果你是在筆電上測試 Prompt,或者只是想在自己的 PC 上快速跑一個 gpt-oss-20b 或 qwen3 來輔助寫程式,Ollama 依然是王者。它的 ollama run 指令簡單到令人感動,且 GGUF 格式讓 8GB/16GB VRAM 的顯示卡也能跑大參數模型。
Open WebUI:這兩大引擎的「統一介面」
無論你底層選擇 vLLM 還是 Ollama,這對於終端使用者(你的同事、老闆或客戶)來說都不重要。他們需要的是一個好用的介面。這就是 Open WebUI (原 Ollama WebUI) 存在的價值。
Open WebUI 已經不僅僅是 Ollama 的前端,它是一個與模型無關(Model-Agnostic)的調度平台。
Open WebUI 如何串聯兩者?
混合調度:你可以在 Open WebUI 的後台同時連接 Ollama(處理簡單的聊天任務)和 vLLM(處理繁重的多模態任務)。使用者在下拉選單中選擇模型時,根本感覺不到後端的切換。
發揮 vLLM-Omni 的潛力: vLLM 本身沒有圖形介面,只有 API。Open WebUI 提供了麥克風輸入、圖片上傳和視訊播放器。當你使用 vLLM-Omni 的語音模型時,Open WebUI 可以直接透過瀏覽器錄音,發送給 vLLM API,並直接播放回傳的音訊,這完美釋放了 Omni 模型的互動能力。
企業級功能:Open WebUI 補足了 vLLM 缺少的「使用者管理」功能。你可以設定誰能使用 vLLM 的算力,並透過 RAG(檢索增強生成)掛載公司的知識庫。
CyberQ 認為,vLLM-Omni 的出現,讓開源社群有更多好用的工具並拓展打造更好的應用。
給你的建議: 鑑於你擁有 DGX Spark 和 RTX 5060 Ti 兩種截然不同的環境:
在 DGX Spark 上:強烈建議部署 vLLM-Omni。利用其強大的 VRAM 和張量並行能力,建立一個公司內部的多模態 API 中心。
在 5060 Ti / 個人電腦上:繼續使用 Ollama。GGUF 的量化優勢能讓用戶在有限的 16GB VRAM 中跑更大的模型,且維護輕鬆。
整合層:使用 Open WebUI 作為統一入口。將 DGX 的 vLLM API 端點接入 Open WebUI,這樣你在個人電腦上也能無縫調用 DGX Spark 的強大算力,享受「混合雲」般的體驗。
最後就是建議大家,也可以多試試看 SGLang ,這個新的 AI 快速框架已經證實在很多領域的速度是超越 vLLM 的,看你的任務需求和用途,再來選擇適合的 AI 平台去部署吧。
首圖由 Google Gemini AI 生成








