如果說 2025 年的 11 月是各家 AI 模型的激烈戰役月,Anthropic 自然不缺席也參戰了。
在 OpenAI 推出 GPT-5.1-Codex-Max 和 Google 釋出 Gemini 3 Pro 短短幾天後,Anthropic 不甘示弱地亮出了底牌,Claude Opus 4.5,可說是針對開發者社群的重點產品。
這次的新版 ,Claude Opus 4.5 模型除了性能上的顯著提升,最讓社群震驚的其實是它的定價策略,Anthropic 這次不講武德,直接將價格砍到了原本的三分之一,試圖用性價比去搶占高階 AI 模型市場。
不只是強,是聰明得像人,甚至通過自家面試
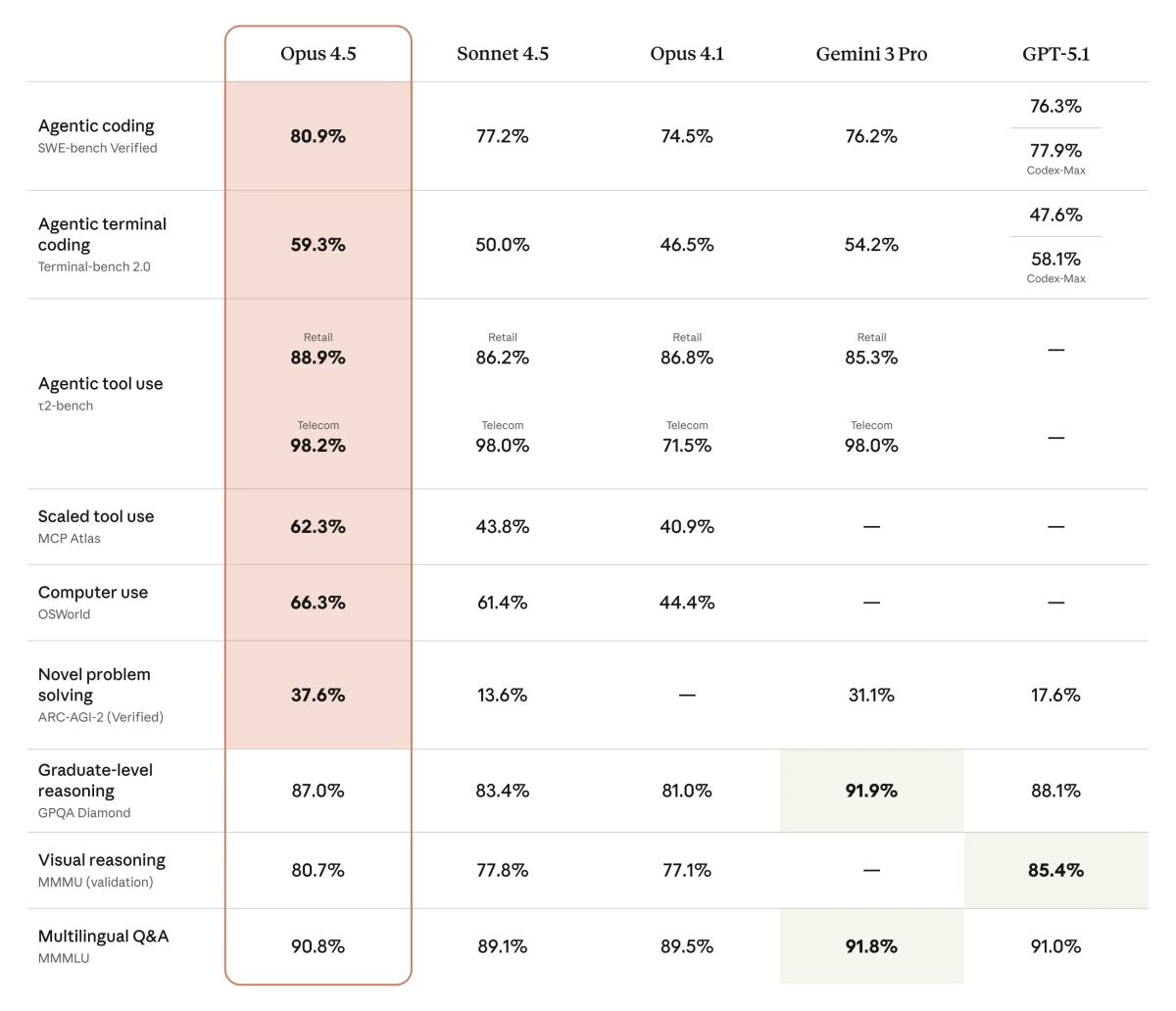
根據 Anthropic 官方與最新的基準測試資料,Claude Opus 4.5 在多項關鍵指標上都創下了紀錄,尤其是開發者最在意的程式碼能力。
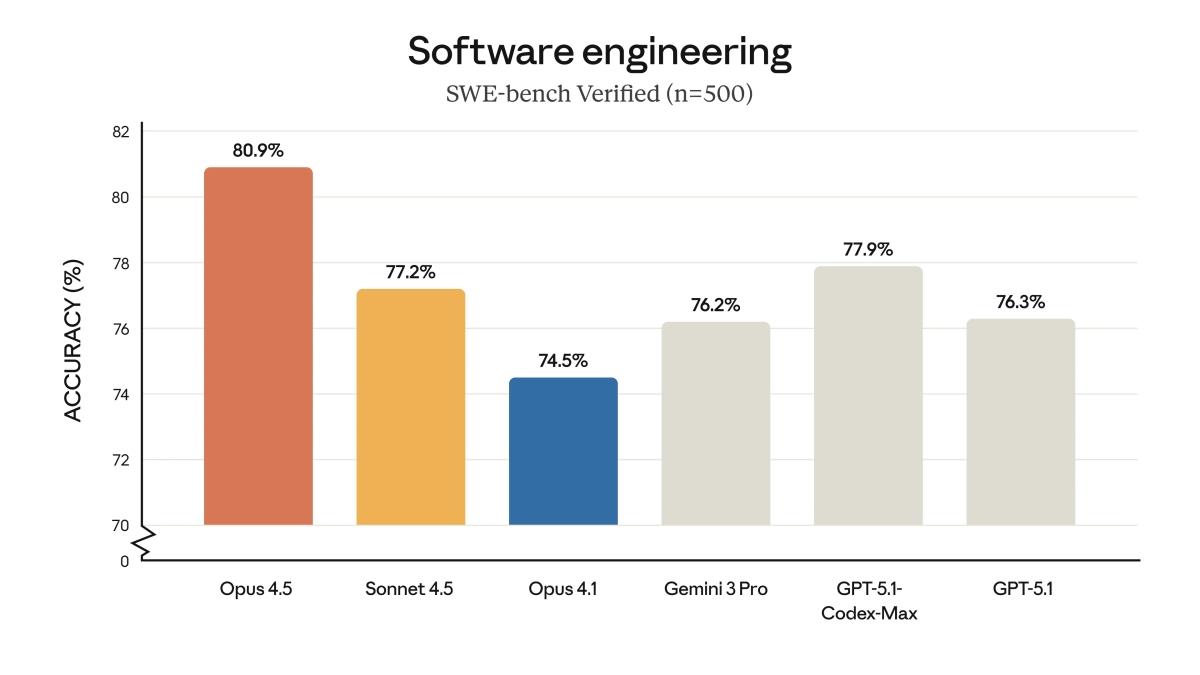
Coding 能力重回 SWE-bench Verified 榜首
在 SWE-bench Verified 這個真實軟體工程問題解決能力測試中,Claude Opus 4.5 拿下了 80.9% 的高分,正式超越了 GPT-5.1-Codex-Max (77.9%) 和 Gemini 3 Pro (76.2%)。換言之,在處理複雜、多步驟的程式碼修復任務時,它目前相關測試中成績最好的。
Claude Opus 4.5 通過了人類面試
這是一個非常有趣的行銷重點,也是該公司對他們 AI 模型自豪的實力展示。根據官方資料,Anthropic 居然讓 Opus 4.5 參加了他們內部招聘「效能工程師」的考題。在 2 小時的時限內,Opus 4.5 的得分高於以往任何一位人類應徵者。雖然這不代表它具備人類的協作能力,但在純技術判斷力上,它已經達到了讓人信服的程度。

具體來說呢,該項考試是一份設計用來評估技術能力和時間壓力下判斷力的考試,限時兩小時內完成。在使用並行測試時間計算的方法下,Opus 4.5 的得分超過了歷史上所有參加過此測試的人類求職者。如果沒有時間限制,該模型在 Claude Code 環境中的表現等同於歷史上表現最佳的人類求職者。
官方針對這項內容的額外說明原文確實如此,This result was using parallel test-time compute, a method that aggregates multiple “tries” from the model and selects from among them. Without a time limit, the model (used within Claude Code) matched the best-ever human candidate.
值得注意的是,Anthropic 強調該測試並未涵蓋協作、溝通等關鍵專業技能,以及多年經驗所培養的直覺判斷能力,這點還是真實人類的強項。
更有彈性的思考模式
官方也對外展示了一個經典案例,當被要求修改一張「不可退改」的經濟艙機票時,Opus 4.5 展現了驚人的「鑽漏洞」能力(Creative Problem Solving)。它沒有死板地拒絕,而是建議:「先符合規定付費升等到商務艙,然後再符合規定更改商務艙的航班」。這種創造性解決問題的能力,正是過去 AI 模型最缺乏的。
價格戰役繼續,高階 AI 模型不再高不可攀
這恐怕是這次更新中最讓開發者關注的消息,過去 Opus 系列雖然強,但價格昂貴(Input $15 / Output $75),讓許多人卻步,轉而使用 Sonnet。但這次 Opus 4.5 的定價極具侵略性:
輸入:$5 / 百萬 tokens
輸出:$25 / 百萬 tokens
這是什麼意思?
它的價格只有前代的 1/3,直接殺進了與 GPT-5.1 和 Gemini 3 Pro 競爭的甜蜜點。配合它引入的 Effort Parameter(努力程度參數),使用者還可以選擇「低、中、高」三種思考強度,進一步控制成本與速度。Anthropic 出這個大絕招降價又加量,明顯是為了從 OpenAI 和 Google 手中搶回企業級用戶。
開發者們怎麼看?
在 Reddit (r/LocalLLaMA, r/ChatGPTCoding) 和 X (Twitter) 上,經過一整晚的發酵,CyberQ 觀察到幾個明顯的討論趨勢:
正面評價居然是解決了陳年老問題,一位 Reddit 用戶分享,他有一個困擾了 5 年的複雜程式碼庫問題,過去用 GPT-4、GPT-5.1 甚至 Sonnet 嘗試修復都失敗,但 Opus 4.5 在 1 小時內就給出了正確的解法。這種「專治疑難雜症」的口碑正在社群中快速擴散。
關於 Vibe 感覺的討論
這是一個很玄但很重要的指標。許多測試者表示,Opus 4.5 的對話風格「更像人」,少了很多 AI 常見的說教感(Sycophancy)或過度熱情的虛假感。有用戶形容:「它更懂得閱讀空氣,不會在你只需要一行指令時給你寫一篇論文。」
與 GPT-5.1 的對比
目前的共識似乎是:GPT-5.1-Codex-Max 在使用終端機(Terminal)和執行腳本上稍佔優勢(畢竟 OpenAI 的生態系整合很強),但在程式碼邏輯推演、架構重構(Refactoring)和除錯上,Opus 4.5 似乎略勝一籌,這與 SWE-bench 的結果相符。
懷疑論者的聲音
當然,也有一派聲音認為,目前的 AI 進步正在趨緩(Plateauing)。有觀點指出,雖然跑分高了,但在日常簡單任務上,使用者可能感覺不出與 Sonnet 4.5 的巨大差異。對於非重度 Coding 使用者來說,這次升級的「體感差異」可能不如帳面資料顯示地那麼大。
AI 開發的新分水嶺
CyberQ 認為 Claude Opus 4.5 的發布可說繼續讓 AI 高階推理模型(Reasoning Models)的價格戰持續,用戶可以精打細算不同任務需要用到的預算,透過 API 去呼叫雲端模型來完成任務,並搭配兼顧本地端模型來分擔成本。
對於台灣的開發者或技術主管來說,如果過去因為成本考量而只在關鍵時刻才捨得切換到 Opus 模型,現在確實可以考慮將其作為主力模型,特別是在涉及複雜系統架構或需要高度安全校準(Alignment)的任務上。
或許我們很多人可以趁著這波價格紅利,趕快去測試手邊那些積塵已久的舊 Bug,也許 Opus 4.5 就是一貼好解藥囉。
首圖由 ComfyUI 搭配本地端 AI 模型生成