隨著人工智慧技術的普及,許多公司正積極採用開源權重模型,也就是公司把訓練好的參數檔案開放下載,可以裝在自己的伺服器上跑,不需要網路也能用,比方說美國 Meta 的 Llama 3、OpenAI 的 gpt-oss、法國的Mistral、中國阿里巴巴的千問 Qwen 等等,透過這些 AI 模型來建構企業內部的應用程式與服務。
然而 Cisco AI Defense 團隊近期發布的一份研究報告指出,這些廣受歡迎的開源模型在面對複雜的互動式攻擊時,防禦能力存在顯著的弱點。研究資料顯示,雖然大多數模型在處理單次惡意指令時能有效啟動防護機制,但若攻擊者採用多輪對話的策略,便能輕易繞過現有的安全防線,導致模型產出有害內容或洩露敏感資訊。
多輪互動的提詞注入手段使防禦機制失效
研究團隊針對八款目前市面上主流的開源大型語言模型進行了深入測試。測試結果發現,當攻擊者僅發送單一惡意指令時,模型通常能識別並拒絕回應。然而當攻擊者改用漸進式的多輪對話手法,例如透過角色扮演或層層遞進的引導式問答(Crescendo),模型的防禦能力便會大幅下降。
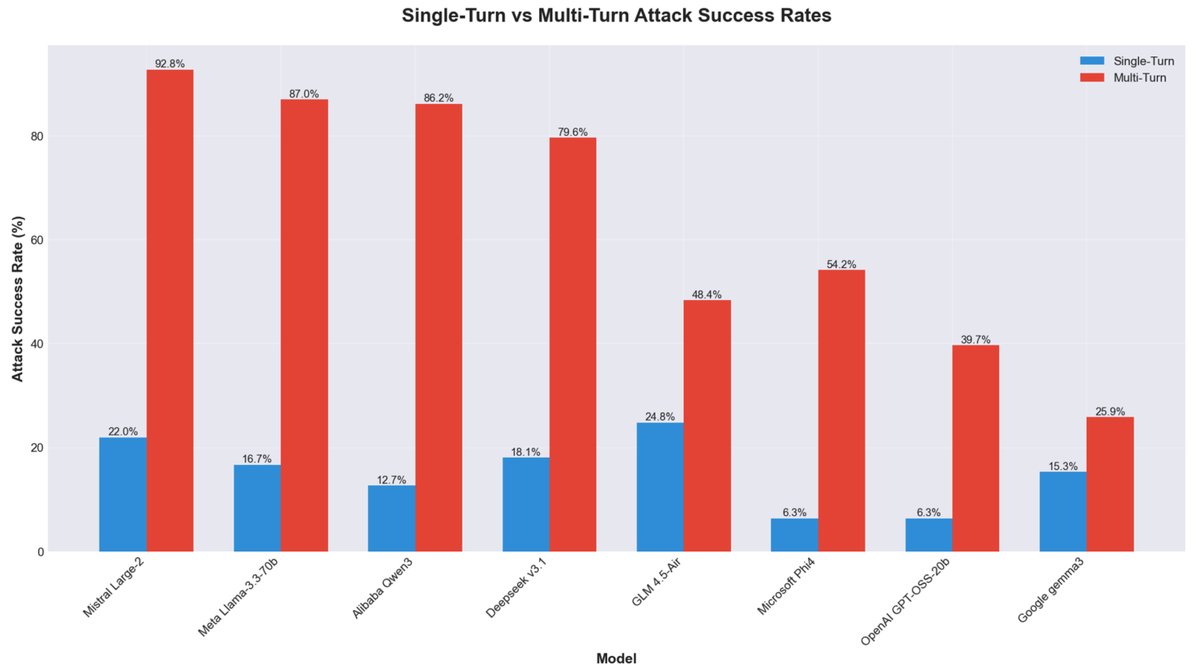
(Figure Credit: Cisco, Death by a Thousand Prompts: Open Model Vulnerability Analysis 2025)
在這種情境下,攻擊成功率從單次互動的低成功率,飆升至百分之九十以上。特別是部分具備高效能推論能力的模型如 Mistral Large-2 與 Qwen3-32B,在面對持續性的誘導對話時,極容易失去判斷力並滿足攻擊者的要求。
模型開發策略影響安全性
Cisco 的分析指出,不同開發團隊在模型設計初期的優先順序,直接影響了最終產品的安全性。部分開發者將重心放在提升模型的推理能力與應用廣度,傾向將安全防護的責任轉交給下游的應用開發者自行處理。相較之下,Google 與 OpenAI 等機構在模型訓練階段便導入了較為嚴格的安全對齊機制,因此在測試中展現出較高的韌性。
思科的資料顯示,Google 的 Gemma 系列模型在多輪攻擊測試中,被成功誘導的比例顯著低於其他同級模型。這顯示在追求模型效能的同時,內建的安全機制仍是決定防禦力的關鍵因素。

公司應建立多層次防護網
CyberQ 認為,面對日益複雜的攻擊手法,單純依賴模型內建的防護機制已不足以確保系統安全。資安專家建議採用這類開源模型的公司,應導入具備上下文感知能力的動態防護系統,而非僅針對單一輸入內容進行關鍵字過濾。
此外,公司也應定期施行模擬駭客入侵測試,以及嚴格限制模型與外部自動化服務的直接串接,都是降低風險的必要手段。透過即時監控與嚴格的系統提示詞設定,公司才能在享受 AI 開源模型帶來的便利與彈性時,有效保障內部資料與系統運作的安全。
首圖及配圖由 Google Gemini AI 生成