

NVIDIA DGX Spark (GB10) 自發表以來,便以其精巧的體積、低功耗與官方補充說明效能後,在 AI 圈掀起了不小的波瀾。然而,任何新技術都免不了從行銷的聚光燈下,走入現實應用的嚴苛檢驗。
NVIDIA DGX Spark (GB10) 在產品發布數月後,當第一批用戶(包括我們自己戲稱自己為「白老鼠」)開始實際部署時,究竟遇到了什麼?NVIDIA 官方開發者論壇與相關開發者交流的討論,確實有不少使用情境的調整與運用挑戰。
CyberQ 以合作夥伴測試和實際觀察的情形來看,DGX Spark 的使用狀況在接近 11月中算是進入了「第二階段」。原本開賣後的首月,包括大家關心最致命的「更新變磚」問題已獲得 NVIDIA 官方解決。而「Wi-Fi 失效」問題雖有手動解法,先前 GB 10 系統更新或特定軟體安裝時,會錯誤地移除了 linux-modules-extra 套件,導致 Wi-Fi 模組(mt7925e)的驅動程式遺失。萬一碰到的解法其實是透過乙太網路或接上 Realtek 晶片的 USB 網路卡去進行連線,進入終端機後,手動下指令執行 apt install linux-modules-extra-$(uname -r) 來重新安裝對應核心版本的 Wi-Fi 模組驅動程式。
不過呢,新的問題也浮上檯面,NVIDIA AI Workbench 軟體套件的安裝與驅動程式互相衝突,導致一小部分使用者修復 Wi-Fi 後又因安裝 AI Workbench 而再次失效的循環。
這顯示出 DGX Spark 的硬體雖已陸續交貨,但其核心的 DGX OS 軟體堆疊(Software Stack)仍處於需要再最佳化的階段。這與官方對外提供的資訊,隨貨物附上基於 Ubuntu Linux Desktop 打造的 DGX OS,並預先配置了完整的 AI 軟體堆疊,如 CUDA、cuDNN、TensorRT、AI Workbench、容器和工作流程教戰手冊 (playbook),團隊可立即執行實際工作負載的描繪有落差。
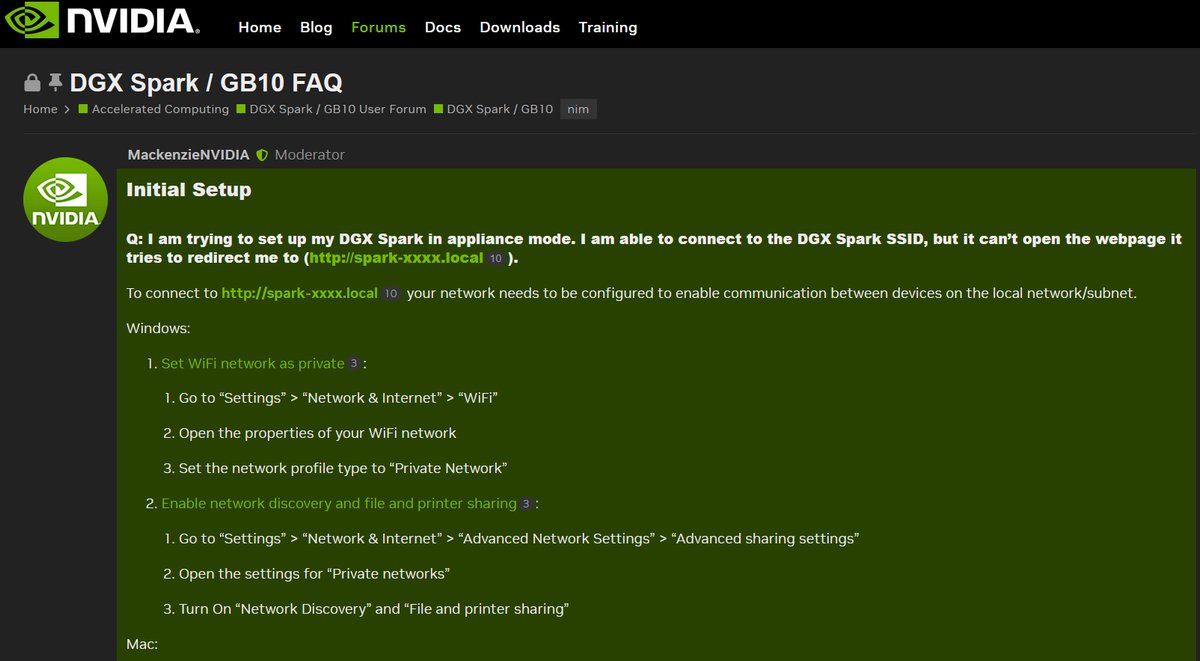
官方在論壇列出的 Nvidia DGX Spark GB10 FAQ ,將重點問題解法列上去。
社群的真實回饋反應 GB10 強大潛力與待修補的現實
近期 DGX Spark (GB10) 的官方相關系列論壇,可說是全球開發者們在第一線奮戰的真實足跡。彙整近期的社群反應,我們可以探討幾個核心焦點當作參考。
首先是軟體堆疊的磨合陣痛期,大量的討論集中在如何在 GB10 上執行當今主流的 LLM 推理框架,例如 vLLM 和 SGLang。雖然 GB10 的硬體規格強悍,但用戶在建置容器(Container)、處理 vLLM 問題,甚至尋找官方原生的 ARM64 NIM 映像檔(例如 Llama 3)時遇到了不少阻礙。這顯示出,從硬體潛力轉化為實際生產力,軟體生態系的成熟度仍是關鍵。有使用者反映說,PyTorch/CUDA 等堆疊存在針對 sm121/GB10 架構最佳化尚未完整的情況。
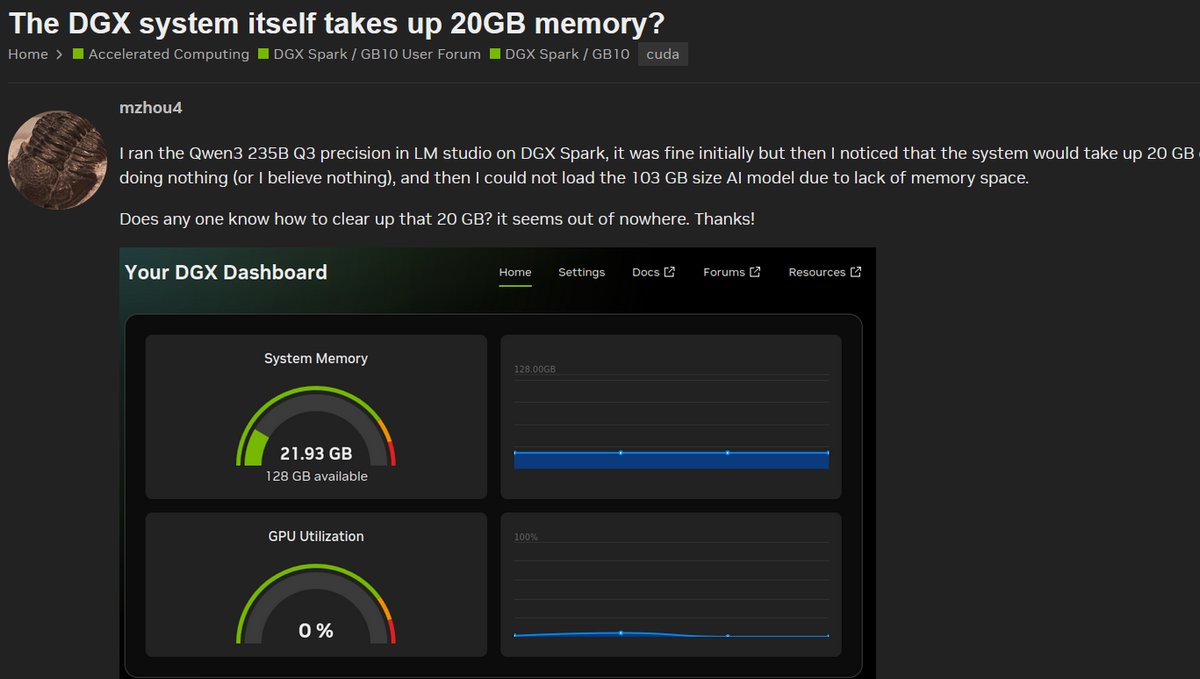
其次,是對 GB10 效能的期望落差,部分用戶直言,在執行一些簡短的 LLM 測試時,感覺「異常緩慢」(extremely slow)。同時,有熱烈討論串在質疑「DGX 系統本身是否佔用了 20GB 記憶體?」,以及 DGX 儀表板上顯示的 RAM 數值與實際 free 指令兜不攏。這些疑問反映出用戶對於系統資源佔用和效能調校的困惑,他們渴望榨出 GB10 的每一分效能,但現實卻充滿挑戰。
再來是系統穩定性與設定的門檻,當然包括類似這種「DGX Spark 每 20-30 分鐘就自動重啟」此類的嚴重問題雖然可能是個案,但也足夠令人警惕,或許它機器放的位置散熱不佳,部署的軟體太吃效能或有軟體衝突,甚至是買到機王都有可能。此外,從「初始設定卡在 NVIDIA Logo 畫面」、「無法從恢復映像檔還原」,到希望「改善系統還原機制」的呼聲,都指向了初始設定(Onboarding)和系統維運都需要琢磨一番,不是某些人想像中的簡單。
最後則是硬體整合與比較的現實考量,社群中不乏實務派的提問,例如「如何將 Spark 連接到 Apple Studio Display」、「如何從 Windows 客戶端 RDP 遠端連線」,甚至「如何連接外部儲存 / NFS」。更有一個熱門話題在直球對決:「我該買 ASUS GX10 還是 NVIDIA DGX Spark?」這顯示了各國用戶正非常務實地評估其在現有工作流中的定位與替代方案。
不妨從個人 AI 工作站升級成 AI 叢集戰力
社群的反應,恰好印證了許多人觀察到 NVIDIA DGX Spark 的重點,它其實是一台很好用又省電的 AI 運算節點。光是二台 NVIDIA DGX Spark 疊在一起,用 200GbE 高速網路互連組成一個小的運算叢集,可以跑更大參數的模型就很實用了。更別提說堆疊更多台,再透過高速網路交換器來達成更大的小型 AI 運算叢集,會比購置一整套 NVIDIA DGX 系統更省成本,也更省電,能執行大型 AI 模型的訓練。在官方論壇與 Reddit 等社群中,有不少用戶討論把 DGX Spark 用於 RAG(Retrieval Augmented Generation)/AI Agent(具自主行為或多模態)/大型語言模型(LLM)推論與微調 的情境。同時,雖然硬體規格亮眼(128 GB 統一記憶體、200 Gb/s 網路等),但要真正達成「大規模模型/大併發用戶/多機聯合」的場景,仍受到驅動、韌體、軟體棧、互連設計、擴展性等限制。
CyberQ 觀察,有使用者在部署 LLM 微調(如 120 B 參數)於 Spark 上時,雖能在 128 GB 統一記憶體內操作,但需要工具如 Unsloth 來最佳化記憶體使用。
另外,在 NVIDIA 開發者論壇裡,有一篇標題為「Updated blueprints for DGX Spark」提問:使用者計畫在 Spark 上跑「量化或較小終端 LLM」及 AI Agent 模板(Blueprints)是否會更新以支持 Spark 平台。其實這問題反應出我們實際使用 GB10 感受到的問題,那就是我們原先看到的 AI Agent 模板,其實大多針對 H100/80GB 環境,而並非特化為 GB10/ Spark,這大概就是 NVIDIA H100 應用在 x86 處理器平台環境 VS 聯發科晶片搭配 NVIDIA GPU 的軟體堆疊差異,所以 NVIDIA 官方目前「有 Blueprints 可用」,但尚未完成針對 Spark 平台的最佳化工作。就有開發者戲稱,我們大家其實都是 NVIDIA DGX Spark (GB10) 的全球公開 Beta 測試使用者,幫忙 debug 的。
在 Reddit 「Dual DGX Spark for ~150 Users RAG?」的討論中,有使用者考量用兩台 DGX Spark 來支援約 150 名用戶、處理 10 k 份文件、建立 RAG + AI Agent 系統。 他們提到雖然 Spark 具備高速網路互連能力,以及記憶體共享的優勢,但網路互連仍可能成為瓶頸。
我們仍需好好動手實做
從社群的真實反饋來看,DGX Spark (GB10) 絕非一款最適合 AI 工作站解決方案。它比較像是一塊有潛力、但邊緣仍需打磨的璞玉,NVIDIA 必須加快腳步,透過韌體與軟體更新來解決社群回報的穩定性與效能問題。繼 11 月初 LMSYS Org 的初步評測後,更多開發者,以及包含成功開機的使用者們的實測證實了此觀點。畢竟之前我們報導與討論過的 LPDDR5x 記憶體頻寬(約 273 GB/s)是主要效能瓶頸。DGX Spark 其實比較適合「AI 模型迭代與原型設計」,能快速載入如 Llama 3.1 70B 這樣的大模型,但在「推論吞吐量」(Tokens/sec)上,表現不如配備 GDDR6X 或 HBM 記憶體的高階桌上型 GPU,比方說 RTX 5070/50805090。
在我們與客戶的 AI 實驗室,也正採用各種方案來嘗試,如讓一台 GB10 透過網路交換器和 QNAP NAS 做整合,再搭配其他具備 NVIDIA GPU 顯示卡的 AI 工作站,將 AI 訓練與 AI 推論的工作分流,資料統一彙整到 QNAP NAS 上給大家掛載的 NFS 磁區,也是不錯的應用方式。
DGX Spark (GB10) 的故事才剛開始。它不是一台人人都需要的 AI 超級電腦,但對於那些願意捲起袖子、深入系統底層、並看懂「叢集」價值的人來說,它無疑是一個充滿魅力的挑戰性「AI 運算積木」。








