AI 在 2026 年 2 月的第一週很熱鬧,OpenAI 與 Anthropic 不約而同地在同一天籤後發布了旗下的最新王牌 AI 模型,分別是ChatGPT 5.3 (GPT-5.3) 與 Claude Opus 4.6,在新的 AI 代理人 (Agentic AI) 逐步進入成熟的階段,他們新的模型是否有更好的表現呢 ?
核心差異呈現兩條截然不同的進化之路
2025 年是 AI 多模態之年,2026 年則是 AI 自主代理之年。GPT-5.3 與 Opus 4.6 雖然都主打更強的推理能力,但在底層邏輯上展現了不同的哲學。
Claude Opus 4.6 是記憶與脈絡的強者
Amazon 等科技大公司投資的 AI 新創公司要角 Anthropic,他們這次的殺手鐧是 「自適應思考 (Adaptive Thinking)」 與 「上下文壓縮 (Context Compaction)」。
自適應思考是 Opus 4.6 的特點,不再需要使用者手動設定思考預算,它能根據問題的複雜度,動態決定何時該進入深層推理模式,何時該快速回應。
另外則是無限延伸的記憶這個功能最被矚目,這次新推出的 Beta 版 Compaction API 解決了長對話的問題。它能在伺服器端自動將舊的上下文進行「無損摘要」,讓開發者在理論上能維持無限長的對話歷史,這對於法律檢索、醫療病歷分析等需要超長記憶的場景是相當顯著的優勢哪。
如果看它的實測資料表現,在 MRCR v2 (資訊檢索基準測試) 中,Opus 4.6 拿下了驚人的 76% 分數,遠超前代 Sonnet 4.5 的 18.5%。
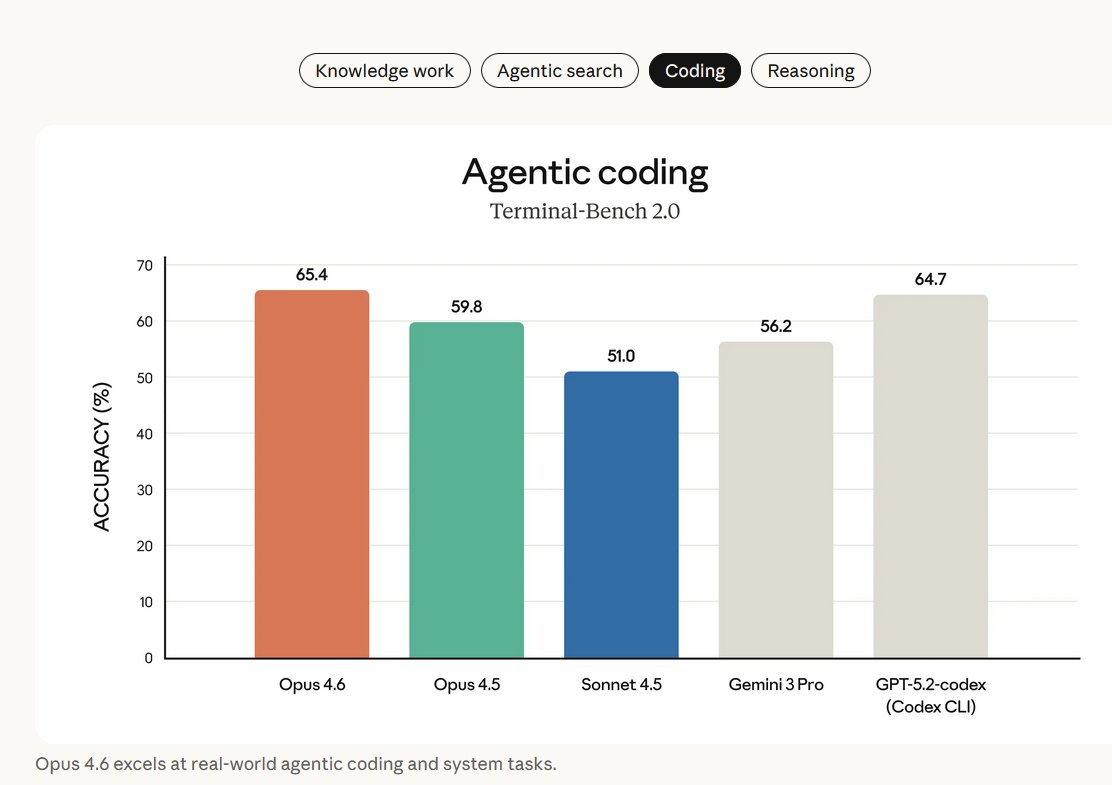
寫程式的能力也很強,不輸其他模型,可說是當前表現相對優異的新版主流模型。
ChatGPT 5.3 (GPT-5.3-Codex) 在速度與執行創新猷
OpenAI 這次顯然將重心放在了「行動力」與「程式碼執行」。他們的重點放在 Codex 原生代理,繼續設法鞏固開發者生態,讓大家能多一點人留在 OpenAI 生態系。這次的GPT-5.3 並不僅是一個語言模型,它更像是一個原生整合了高階 Codex 的作業系統,它在執行多步驟寫程式的任務時,展現了比 5.2 快 25% 的速度。
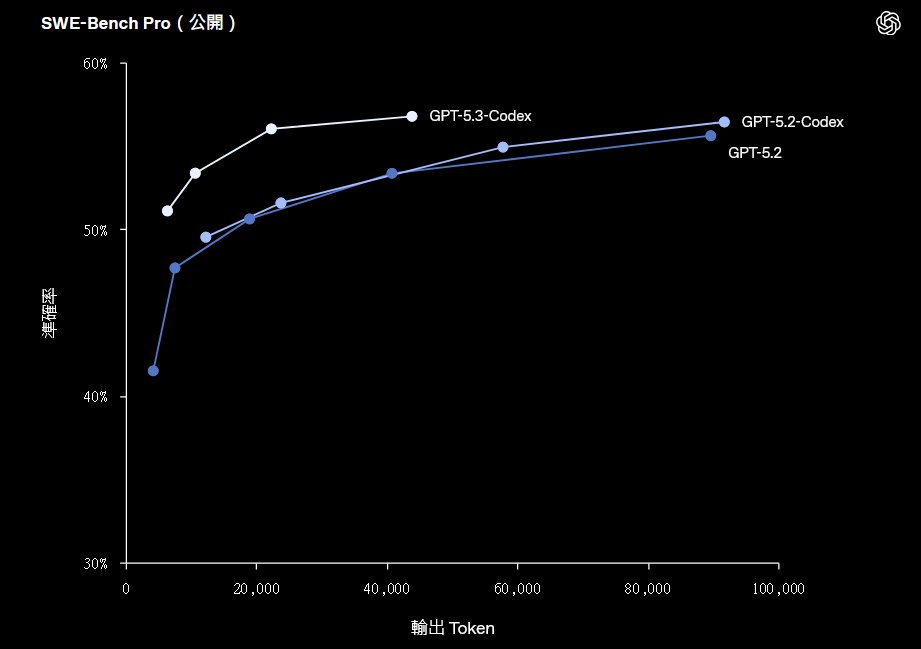
深度思考最佳化在這次是透過調整了「Deep Think」模組來實現的,現在更傾向於平行假設測試。在解決複雜的架構設計問題時,GPT-5.3 能夠同時模擬多種解決路徑並自行除錯,這讓它在 DevOps 和自動化腳本撰寫上具有相當的能力提升。
主流模型 API 價格比較表 (2026 最新版)
對於企業與開發者來說,性能固然重要,但 Token 的推論經濟學才是落地的關鍵。以下整理了截至 2026 年 2 月 7 日的最新 API 定價(以美金計價,每百萬 Tokens):
| 主流AI模型 (Model) | 輸入價格 (Input / 1M) | 輸出價格 (Output / 1M) | 上下文窗口 (Context) | 特性 |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M (Beta) | 最聰明但最貴。適合需要極高準確度、長文本分析與複雜推理的任務。 |
| GPT-5.3 | ~$1.75* | ~$14.00* | 128K | CP 值極高的旗艦。在寫程式與邏輯執行上展現了不錯的性價比 (價格基於 5.2 版本推估)。 |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 1M | 平衡型選手,但在 Opus 4.6 發布後,定位比較適合中高階任務。 |
| Gemini 3 Pro | $2.00 | $12.00 | 2M | 超大窗口首選。Google 的定價策略非常激進,且 2M 的窗口在影片分析上有獨佔優勢。 |
| GPT-4o / 5-mini | $0.15 | $0.60 | 128K | 依然是高頻、簡單任務(如客服、簡單翻譯)的成本王者。 |
| DeepSeek R1 | $0.55 | $2.19 | 128K | 開源界的低價選項。雖然安全性與穩定性稍遜,但推理成本極低,適合學術研究或內部工具。 |
其他主流模型細項選擇 API 價格列表 :
| 提供商 | 模型 | 輸入定價 (USD/百萬 Tokens) | 輸出定價 (USD/百萬 Tokens) | 備註 |
|---|---|---|---|---|
| OpenAI | GPT-5.2 | 1.75 | 14.00 | 標準階層;快取輸入 0.175。 |
| OpenAI | GPT-5.2 Pro | 21.00 | 168.00 | 高性能。 |
| OpenAI | GPT-5.1 | 1.25 | 10.00 | 平衡型。 |
| OpenAI | GPT-5 Mini | 0.25 | 2.00 | 高效型。 |
| OpenAI | GPT-4o | 2.50 | 10.00 | 多模態。 |
| OpenAI | GPT-4o Mini | 0.15 | 0.60 | 低成本。 |
| Anthropic | Claude Opus 4.6 | 5.00 (≤200K Tokens) / 10.00 (>200K) | 25.00 (≤200K) / 37.50 (>200K) | 旗艦模型。 |
| Anthropic | Claude Sonnet 4.5 | 3.00 (≤200K) / 6.00 (>200K) | 15.00 (≤200K) / 22.50 (>200K) | 平衡型。 |
| Anthropic | Claude Haiku 4.5 | 1.00 | 5.00 | 高效型。 |
| Gemini 3 Pro | 2.00 (≤200K) / 4.00 (>200K) | 12.00 (≤200K) / 18.00 (>200K) | 高性能。 | |
| Gemini 2.5 Pro | 1.25 (≤200K) / 2.50 (>200K) | 10.00 (≤200K) / 15.00 (>200K) | 平衡型。 | |
| Gemini 2.5 Flash | 0.30 (文字/圖像/影片) / 1.00 (音頻) | 2.50 | 高效多模態。 | |
| Mistral AI | Mistral Large 3 | 2.00 | 6.00 | 高階型。 |
| Mistral AI | Mistral Medium 3 | 0.40 | 2.00 | 平衡型。 |
| Mistral AI | Minstral 8B | 0.10 | 0.10 | 低成本。 |
| xAI | Grok 4.1 Fast | 0.20 | 0.50 | 高效型;支援長上下文。 |
| xAI | Grok 4 | 3.00 | 15.00 | 旗艦模型。 |
| Cohere | Command R+ | 2.50 | 10.00 | 高性能。 |
| Cohere | Command R | 0.15 | 0.60 | 平衡型。 |
CyberQ 提醒,GPT-5.3 的定價策略尚未完全透明,其價格可能與 GPT-5.2 持平 ($1.75/$14.00),這顯示 OpenAI 試圖透過加量不加價來鞏固市佔率,不然按照市場上的激烈競爭,它要是漲價了其實會有點難留住更多客戶。相比之下,Claude Opus 4.6 維持了相對較高的定價,明確鎖定「不在乎成本,只在乎結果」的頂級企業用戶。
GPT-5.3-Codex API 目前使用方式僅限於付費的 ChatGPT 訂閱方案(如 Plus、Pro、Business、Enterprise)中使用,尚未開放 API 存取。
Claude Opus 4.6 和 GPT-5.3 的取捨?
CyberQ 建議在實務工作中這樣選。
選擇 Claude Opus 4.6 的時機:
資安鑑識與合規,當你需要 AI 分析數百頁的 Log 檔或法律合規文件,且絕對不允許出現幻覺時,Opus 4.6 的上下文壓縮與高檢索力是不錯的解法。
複雜決策代理也是另一個選 Opus 4.6 的好時機,如果你的 AI Agent 需要自行判斷是否需要尋求人類協助或處理極度模糊的指令,Opus 4.6 的自適應思考能力現在是很適合的選項。
選擇 GPT-5.3 的時機:
軟體開發與 DevOps 會滿適合的,不論是最近熱門的 OpenClaw AI 代理,或者是我們想要請 AI 協助自動修復程式中的 Bug、轉換程式語言或生成單元測試,GPT-5.3 的 Codex 原生能力加上較低的 API 成本,是開發團隊的最佳夥伴,畢竟拿去跑 Claude API 花的錢會更多一些。
即時互動應用的領域也很適合,由於 GPT-5.3 的推論速度提升了約 25%,在需要快速回應的消費端 AI 應用,如高階教育家教、即時翻譯等領域,GPT-5.3 的延遲感明顯低於 Opus。
2026 年工作或學習用的 AI 模型該怎樣選好呢?
CyberQ 認為,2026 年的 AI 戰場不再是單純比誰懂的知識多,而是繼續搶誰能更穩定地替人類工作的位置。
Claude Opus 4.6 像是一位資深且謹慎的顧問,貴但值得信賴,適合做決策與審查。
GPT-5.3 則像是一位執行力超強的工程師,快且高效率,適合將想法落地為代碼與行動。
但是,如果加入考量 Google Gemini 3 Pro 呢 ?
Gemini 3 Pro 已經敲敲佔據了一個獨特且不容易被取代的 AI 位置,也就是 AI 原生多模態 (Native Multimodality) 的綜合能力。
在處理真實世界的混雜訊號,比方說影片 + 音訊 + 程式碼時,Gemini 3 Pro 是目前市面上較佳的選擇,可以同時多資訊給它協作去完成任務,畢竟它的電腦視覺能力已經有導入。但另外幾個主流模型如果要處理這種複雜任務,在介面上的調用就比較複雜,串接 API 來跑時要做更多工和找適當工具。
另一方面,Google 在 Workspace 中的整合度佳,我們在開發時會喜歡它能直接調用 Google Search 的即時資料來減少幻覺,這一點比 GPT-5.3 的 Web Browsing 更穩定。在處理圖片和影片分析的 API 成本上,Gemini 3 Pro 雖然單價不低,但考慮到它可以降低額外的 OCR 或轉錄成本,綜合 TCO 總擁有成本反而相對較低。
對於企業而言,混合使用(Hybrid Use)是不錯的主流架構選擇和規劃,我們可以用 Opus 4.6 進行高層規劃與審核,再交由 GPT-5.3 進行具體執行,這將是平衡成本與效能的多面向兼顧解法。
在 2026 年的下半年,CyberQ 預測企業級應用會出現這樣的黃金組合:「用 Gemini 看,用 Opus 想,用 GPT 做。」 (See with Gemini, Think with Opus, Do with GPT.),這個是滿有可能出現的場景呢。
首圖由 Nano Banana AI 生成