Google DeepMind 近日讓旗下的 AI 模型 Gemini 3 Flash 導入了Agentic Vision 強化 AI 視覺功能 ,這次更新是針對開發者對於 AI 代理人的進階需求,讓模型具備主動式的視覺推理能力,能透過撰寫並執行程式碼來與圖片互動,大幅改善過去 AI 模型在處理高解析度影像時,容易忽略細節的問題。
Think-Act-Observe 從靜態瀏覽進化為主動偵測
過去的 AI 模型在處理視覺資訊時,大多採取靜態瀏覽模式,如同瞥一眼圖片便直接回答問題,這導致模型在面對微小文字或複雜圖表時經常出錯。
這次Gemini 3 Flash 引入了全新的「Think-Act-Observe」循環機制,打破了過去看圖即回答的單向路徑,讓 AI 像真人一樣,懂得在看不清楚時主動湊近反覆檢視。
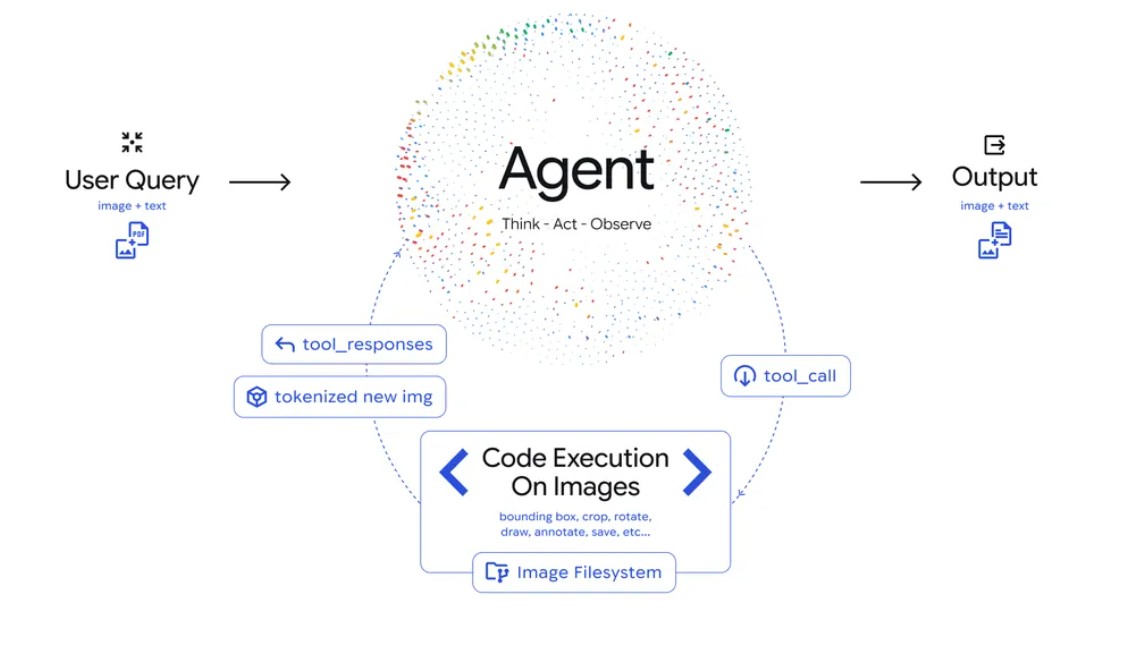
Photo Credit by Introducing Agentic Vision in Gemini 3 Flash
Think 階段時,模型會先分析使用者的問題與原始圖片,擬定出一套具備多步驟形式的解決計畫。
Act 階段則是遇到如建築藍圖細節或晶片序號等需要細看的資訊時,模型會主動生成並執行 Python 程式碼來處理圖片,例如裁切特定區域或旋轉視角,或是直接進行資料運算。
Observe 階段會把處理後的圖片細節或運算結果,被重新加入模型的脈絡中,再進行二次檢視。
Google 藉由這種循環的實作,讓 AI 不再是依賴模糊的視覺印象,而是能針對關鍵區域反覆驗證,直到確認答案無誤後才產出最終回應。
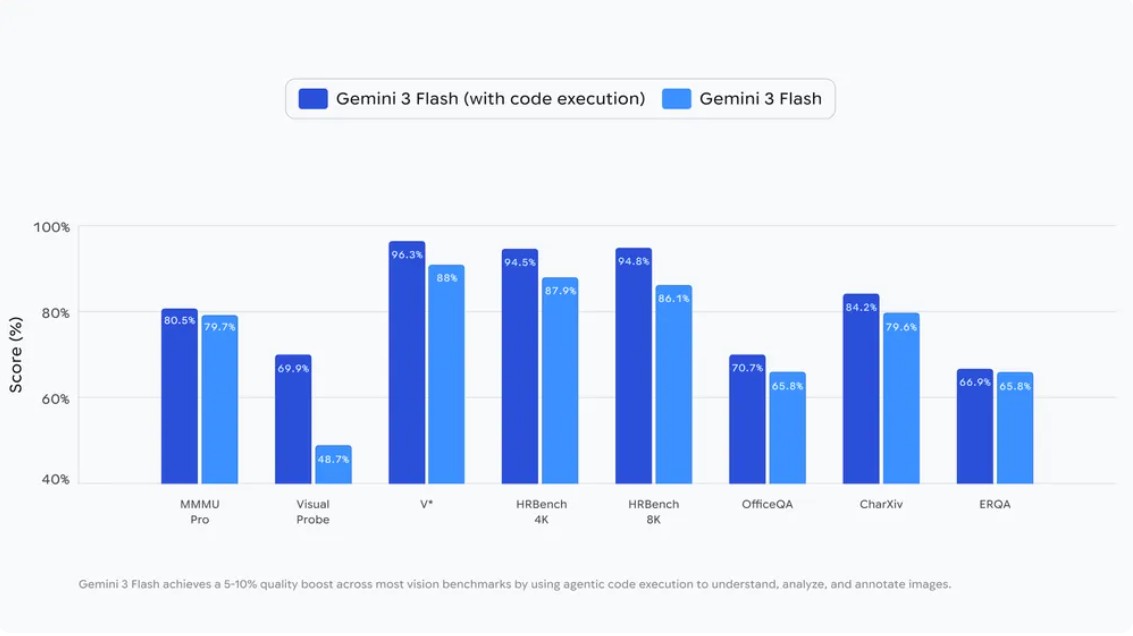
Figure Credit by Introducing Agentic Vision in Gemini 3 Flash
視覺化標記讓推論過程有據可查
除了主動放大檢視之外,更新過的模型還具備視覺註解能力。也就是在執行計算數量或物件辨識的任務時,Gemini 3 Flash 不再僅是給出文字答案,還會直接在影像上繪製邊框或標籤。
例如當使用者要求計算畫面中的物件數量,模型會在每個辨識到的物件上直接標示數字。這種視覺化草稿,強迫模型必須將推論過程與影像精準對應,這個做法能夠有效降低 AI 產生幻覺的風險。

以程式邏輯解決視覺運算難題
CyberQ 以客戶案例實際測試,過去在處理含有大量資料的圖表或財報時,傳統大型語言模型是依照統計學上的機率來預測下一個字,而不是進行真正的邏輯推演。這就像是一個為了讓句子通順而憑感覺回覆,雖然說話流利,但在面對需要精確答案的數學計算或細節辨識時,就容易因為猜錯而產生幻覺。
而Gemini 3 Flash 是透過 Agentic Vision 精準解析圖表中的原始資料,並透過執行 Python 環境進行數學運算或繪製全新圖表。這種將視覺理解與程式邏輯結合的作法,讓 AI 代理人在處理科學資料與金融報表時的可靠度有所提升。
實際執行可以透過 Google AI Studio 和 Vertex AI 進行程式開發時調用 Gemini API 來進行,以下是 Google 給的實作程式碼範例 :
from google import genai
from google.genai import types
client = genai.Client()
image = types.Part.from_uri(
file_uri=”https://goo.gle/instrument-img”,
mime_type=”image/jpeg”,
)
response = client.models.generate_content(
model=”gemini-3-flash-preview”,
contents=[image, “Zoom into the expression pedals and tell me how many pedals are there?”],
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
print(response.text)
從看見到更能看得懂的進步
CyberQ 認為 Google 這次推出的 Agentic Vision,在技術層面上可說是從直覺式感知轉向驗證式推論。
過去的大型語言模型在處理影像時,往往依賴機率性的預測,就像憑直覺快速掃視一眼,雖然速度快,但面對需要精確計算或辨識微小細節的任務時,就經常產生誤判。Gemini 3 Flash 透過導入程式碼,賦予了 AI 自主調用工具的能力。這就好比給了 AI 一把放大鏡與計算機,讓它在回答問題前,能先經過嚴謹的邏輯驗證。
CyberQ 觀察,對於一般公司應用來說,這項改變也降低了企業撰寫程式碼呼叫 API 來導入 Google 應用到實務上落地的門檻。像是產品的瑕疵檢測、報表數位化,以及醫療影像的初步辨識等場景中,AI 的準確率與可解釋性是重要關鍵。
Agentic Vision 只要是能夠留下視覺化的推論軌跡,讓使用者知道 AI 是如何得出結論,這將有助於建立人類與 AI 代理人之間的信任感。換言之,多模態 AI 的競爭焦點,除了參數量規模外,解決實際問題的能力更重要。Google 此舉增加了一些 AI 代理人能真正落地,未來逐步成為更備生產力的數位勞動部署可能性。
首圖及部分配圖由 Nano Banana AI 生成