

近期一篇由 Google 研究員發表的最新論文提出了一個簡單卻違反人類直覺的發現,只要在輸入時重複兩次同樣的提示詞 Prompt,就能在不增加推理延遲的情況下,顯著提升模型的回答準確度。這項研究打破了許多人對於提示詞工程的既定印象,證明了有時候最簡單的暴力法反而最有效。
一次輸入雙重內容為何會是關鍵?
這項名為 Prompt Repetition Improves Non-Reasoning LLMs 的研究提出了一個核心概念,為了避免讀者誤解,這裡必須清楚說明操作方式。這並非要求使用者與模型進行兩輪對話,也不是先講一次等模型回答後再講一次。
研究中所謂的重複,是指在按下傳送鍵之前,直接將你的指令或文本內容複製貼上兩次,也就是「指令+指令」的長字串,然後一次性發送給模型。例如你原本想問「什麼是量子運算?」,現在改成輸入「什麼是量子運算?什麼是量子運算?」。就算是針對長篇文章的分析任務,也是將整篇文章內容連續貼上兩次。
這麼做的原因在於大型語言模型的注意力機制。目前的模型多半是基於因果關係進行訓練,當模型在處理第二遍重複的內容時,能夠參考第一遍已經出現過的資訊。換句話說,這就像是強迫模型在開始作答前,先把問題或資料多讀一遍,進而對提示詞進行更深層的注意力運算,這樣做能夠有效彌補模型在處理長文本或複雜指令時,容易發生的看過就忘問題,也能減少其注意力缺失問題。
47 : 0 的完勝 ! 實測顯示資料檢索準確率翻倍
Google 研究團隊針對目前市面上主流的語言模型皆進行了測試,包括 Google Gemini、OpenAI ChatGPT 系列、Anthropic 的 Claude 以及 DeepSeek 等模型。測試結果顯示,總共 70 項基準測試中,這種重複提示詞的策略在 47 項測試中均取得了統計上顯著的領先。
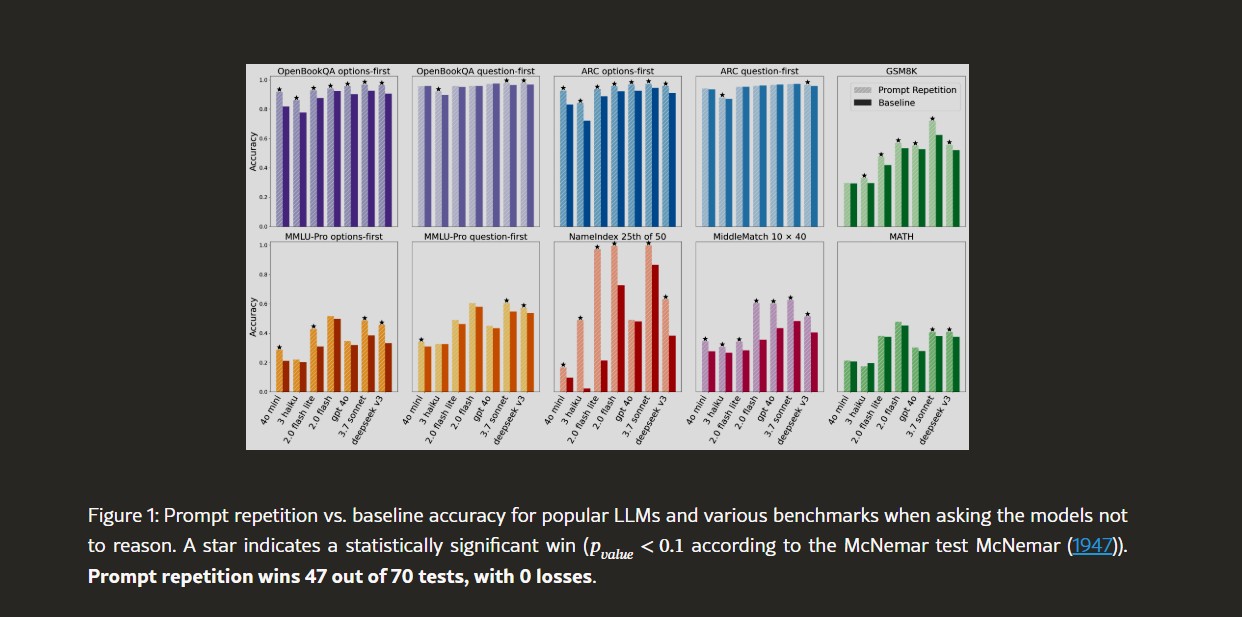
Figure Credit by Prompt Repetition Improves Non-Reasoning LLMs
其中在 NameIndex 這類需要精確對照的任務上,研究團隊以 Google 的 Gemini 2.0 Flash-Lite 模型為例,在未使用重複提示詞的情況下,準確率僅有 21.33%。但在將輸入內容重複兩次後,準確率便驚人地提升到了 97.33%。這對於某些需要精確檢索或對照的任務,重複輸入能夠帶來巨大的效益。這對於許多依賴模型進行精準資料處理的專案或公司來說,也是一個極具價值的發現。
重複輸入提示詞能同時提升效能與效率
許多人可能會擔心,輸入內容變成兩倍長,是否也會導致運算時間加倍。但是研究結果指出,這種方法並不會增加模型處理問題的等待時間。這是因為重複的部分主要是在「預填充(Pre-filling)」階段處理,而現代的圖形處理器(GPU)在處理這類平行運算時效率極高,NVIDIA 的顯示卡在這部分的表現相當好。
而對於使用者最在意的生成延遲,也就是模型回答問題的速度,幾乎沒有任何影響,因為模型輸出的內容長度並沒有因為提示詞變長而改變。這代表可以在不更換更昂貴模型的情況下,直接透過軟體層面的調整,也就是簡單的「複製貼上」策略,來顯著提升服務品質。
未來應用展望
CyberQ 認為,這項研究為提示詞工程開啟了新的方向,畢竟在過去我們為了讓模型有最佳表現,往往花費大量時間在精雕細琢每一段提示詞。但現在看來,其實簡單地將輸入內容加倍,會是一個更通用且穩定的解決方案。這對於一般使用者來說,也是一個超級容易上手的小技巧,只要記得把重要的事情講兩次,就和你對老是聽不清楚或常忘記你表達內容的人講二次類似,這樣就能讓手邊的 AI 助手變得更聰明呢。
首圖由 Nano Banana AI 生成







