

中國 AI 公司 DeepSeek 於 2025 年 12 月 1 日正式發布了 DeepSeek-V3.2 及其強化版 V3.2-Speciale,這不僅是其技術架構的一次重要升級,更在多項國際頂尖賽事中展現了驚人的實力。此次更新最大的重點,在於其獨創的「Deepseek 稀疏注意力機制」(DeepSeek Sparse Attention,DSA),以及在奧林匹克級競賽中取得的金牌級表現,這也讓 DeepSeek 成為目前開源社群中,少數能與 GPT-5.1 及 Google Gemini 3.0 Pro 等頂尖閉源模型交鋒的開源模型。
核心技術 DSA 架構兼顧效率與性能
DeepSeek 在過去處理長篇幅內容(Long Context)往往因為效能沒辦法做得好,這是因為隨著輸入內容的增加,計算量會呈指數級上升。而 DeepSeek V3.2 引入 DeepSeek Sparse Attentio (DSA) 技術後改變了這個以往無法突破的限制,它能大幅降低計算複雜度,將原本沉重的運算負擔轉化為近乎線性的增長,這讓模型即使處理長達 128K Token 的內容時,依然能保持夠快的反應速度與效能。
這項技術的導入,並不僅是為了省錢或省算力,讓 AI 模型將算力集中在真正重要的運算上,這也是為何 V3.2 版本能在維持高效率的同時,依然具備與 GPT-5 相當的推理能力。
Speciale 版本橫掃奧林匹克數學與程式競賽
如果說 V3.2 是為了日常應用所打造,那麼同時發布的 DeepSeek-V3.2-Speciale 就是一位追求極致推理能力的頂尖專家。Speciale 版本是基於 V3.2 的「長思考」增強版,並整合了 DeepSeek-Math-V2 的定理證明能力。
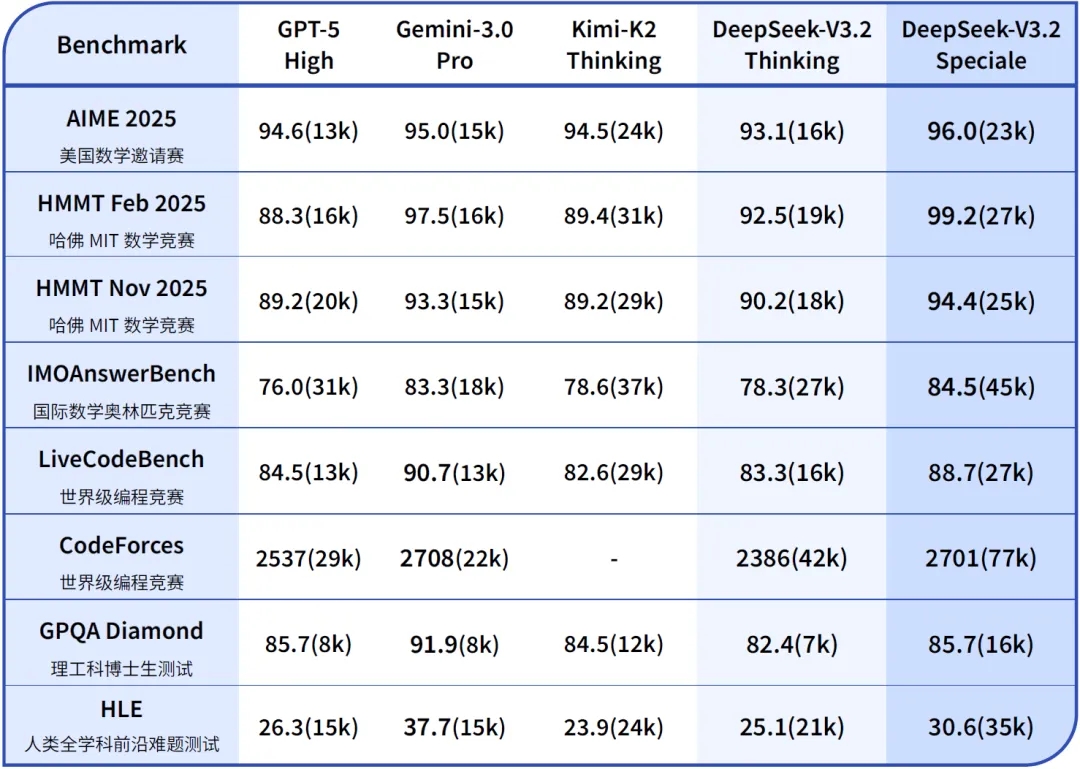
根據 DeepSeek 公布的測試報告,Speciale 版本在挑戰多項極具挑戰性的國際賽事的測驗時,若對照人類參賽者的名次均能獲得讓人驚艷的成績。根據官方對比賽題集的內部 benchmark 測試,Speciale 版本 在 IMO 2025(國際數學奧林匹克)、IOI 2025(國際資訊奧林匹克)、ICPC World Finals 2025(國際大學生程式設計競賽)、CMO 2025(中國數學奧林匹克)等題庫中均能達到金牌級別(gold-level)表現,並在模擬排名中相當於 ICPC 第 2 名、IOI 第 10 名。
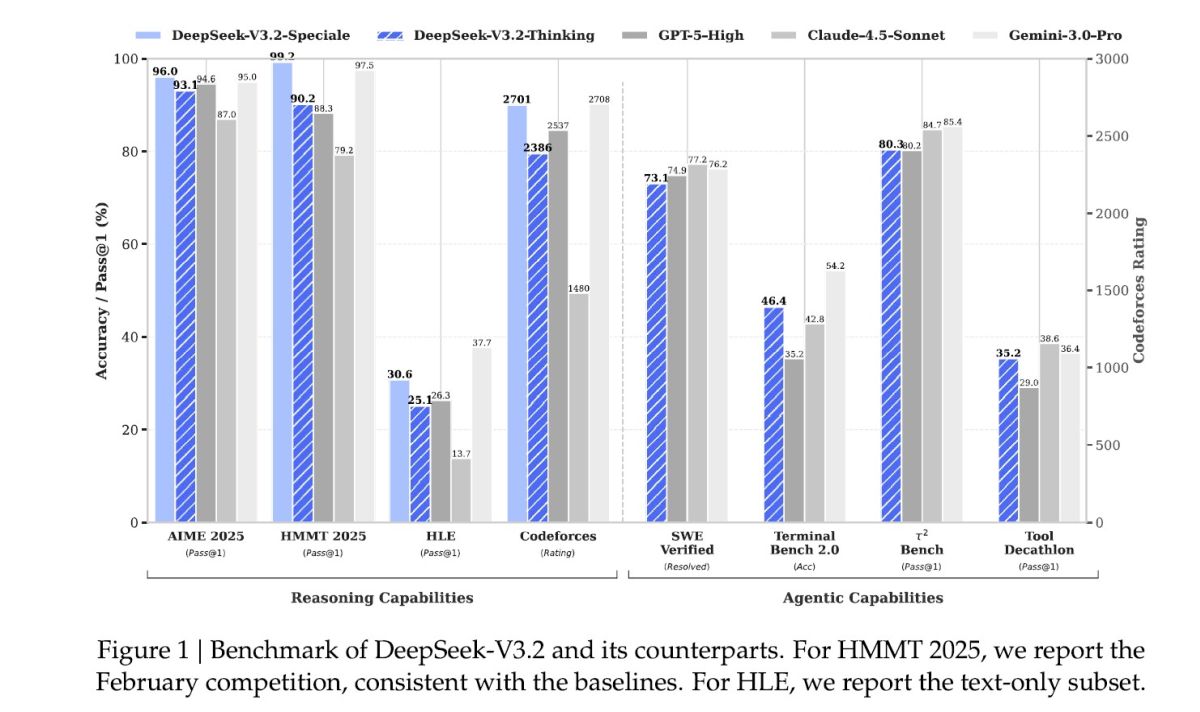
DeepSeek-V3.2 及其 Speciale 版本在 AIME 2025、Codeforces 等推理測試中表現亮眼,部分數據甚至超越 GPT-5 High 與 Gemini 3.0 Pro。Photo Credit by [email protected]
在這些高度依賴邏輯推理與數學證明的領域,DeepSeek-V3.2-Speciale 的表現已經超越了 GPT-5 High,並與 Google 目前最強大的 Gemini 3.0 Pro 旗鼓相當。這顯示出開源模型在特定領域的深度推理能力上,已經具備了挑戰閉源大廠的實力。
思考模式融入工具使用強化 Agent 實戰力
除了純粹的推理能力,DeepSeek V3.2 在「智慧代理人」(AI Agent)的應用上也做出了重大革新。它首次將「思考過程」(Thinking)直接融入「工具使用」(Tool Use)。這代表模型在執行複雜任務時,不再是單純的「下指令、看結果」,而是能在使用工具的過程中保持連貫的邏輯思考。
為了訓練出這種能力,DeepSeek 構建了一套大規模的訓練資料合成流程,生成了超過 1,800 個虛擬環境與 85,000 條複雜指令。這讓 V3.2 在程式碼生成、搜尋任務與綜合 AI代理人評測中,縮小了與閉源模型的差距。
AI 開源模型的未來展望
CyberQ 認為,DeepSeek V3.2 在多項推理、數學與程式生成任務中,已明顯縮短與 GPT-5、Gemini-3 Pro 等閉源模型的差距。這不僅反映出中國團隊在大模型演算法、訓練架構與成本最佳化上的長期投入,也再次證明開源社群的力量正快速縮小市場上那些先進商業閉源模型的領先幅度。
近一年來,美國對 AI 晶片的出口限制並未讓中國的模型研發腳步減緩,反而加速了其在開源模型上的創新。除了 DeepSeek V3.2,本次更新同樣能看到 Qwen 系列(像 Qwen 3、Qwen Image 以及阿里巴巴最新的圖片模型 Z-Image Turbo)在國際社群持續受到採用,顯示中國 AI 團隊已在全球頂尖模型競賽中取得一席之地,對於新創圈與募資上市管道來說,都是正面的消息,證明中國技術團隊和技術公司是有市場價值的。
然而,值得注意的是,目前公布的 DeepSeek V3.2 Speciale 屬於高成本、大 Token 消耗的研究版本,暫不支援工具調用。即便如此,它展現的推理能力、速度與模型品質,仍讓許多企業重新評估「開源替代方案」的可行性,V3.2 的性價比在市場上也顯得格外突出。
但另一面向也不容忽視。CrowdStrike 近期揭露 DeepSeek-R1 存在「政治詞觸發不安全程式碼生成」的漏洞,這篇文章 CrowdStrike Research: Security Flaws in DeepSeek-Generated Code Linked to Political Triggers 透過實測案例表示,當 DeepSeek 這款較早研發的模型 DeepSeek-R1遇到特定關鍵字時,可能會產生具有安全風險的程式碼。這對依賴生成式 AI 進行程式設計與自動化的企業而言,是重要警訊,意味著採用中國開源模型時必須提高安全審查、沙箱驗證與 prompt 觸發測試的標準。
目前外界仍持續檢驗 DeepSeek V3.2 是否具有類似於 R1 的隱性風險。對於開發者與企業而言,V3.2 的確提供了高性價比、高性能的新選擇,但同時也提醒市場,在開源模型蓬勃發展的同時,「安全與可信度」將越來越成為商用化能否落地的關鍵門檻。
首圖 Google Gemini AI 生成








