近年生成式 AI (GenAI) 已從概念驗證迅速滲透至知識工作者的核心流程,主要應用仍多聚焦於個人助理、代碼生成與資料檢索。
然而,日前 OpenAI 推出「群組聊天」功能,象徵著 GenAI 正式跨越了「個人生產力」的邊界,進入「多人協作與資訊共享」的企業級場景。
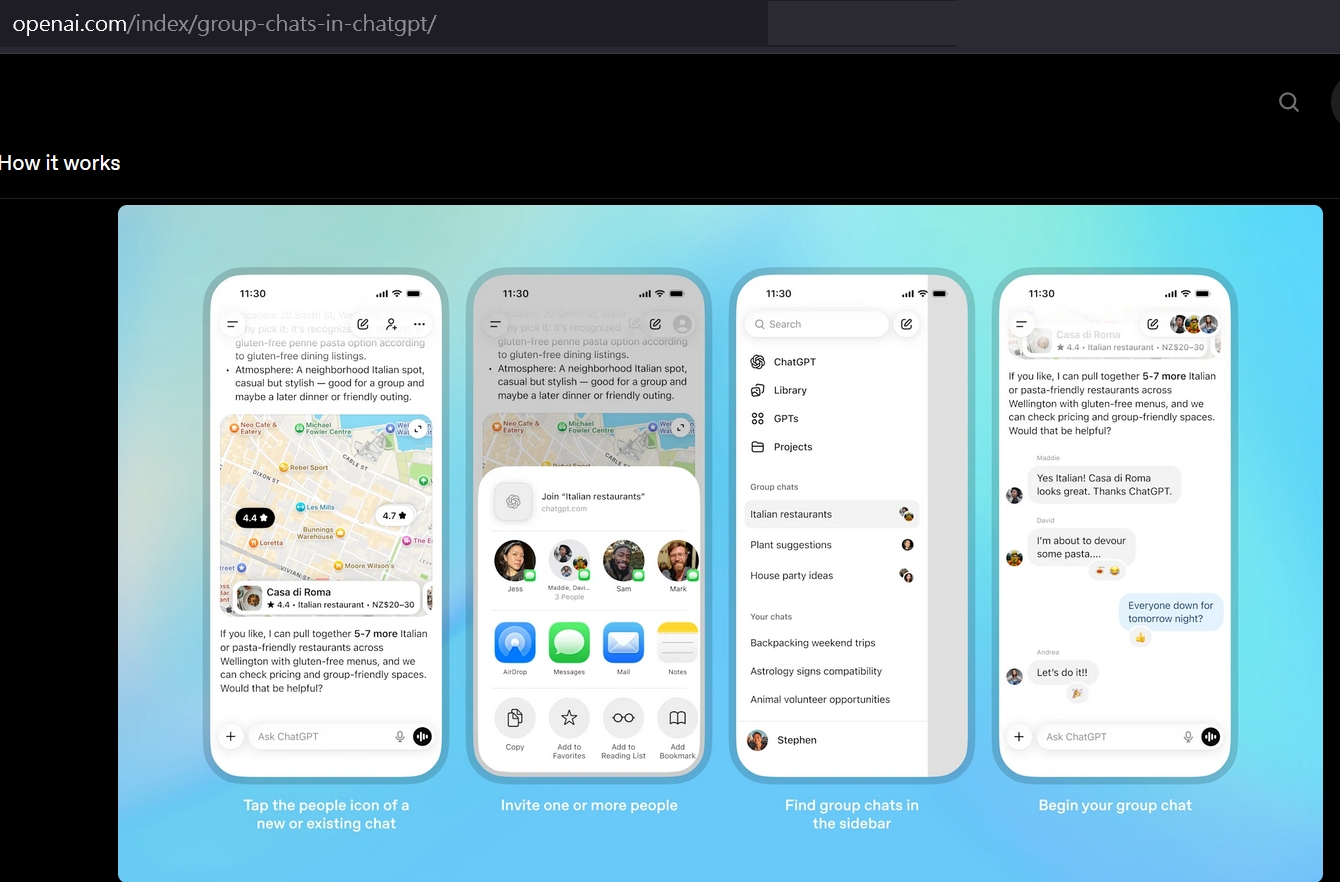
從資安架構與技術治理的視角審視,這不僅是功能的更新,更是一場對現有防護體系的挑戰,當 AI 介入多方對話,資料傳輸的安全性、身份權限的界定、輸出內容的可追溯性(Traceability),以及產生資料、知識的所有權歸屬,皆需重新定義。這迫使企業必須從單純的工具使用,升級至對協作流程 (Workflow)、資料治理 (Data Governance) 與風險模型 (Risk Model) 的全面重構。
AI 角色從「工具」升級為「智慧協作節點」
若將傳統的一對一對話視為「個人思維的延伸」,那麼群組聊天模式則可被定義為「集體智慧的整合層」。在此架構下,AI 不再是被動等待指令的終端,而是具備上下文感知能力(Context Awareness)的主動參與者。
現階段的 AI 已經逐漸能解析多方使用者的脈絡,協助釐清觀點差異、識別邏輯矛盾,甚至進行沙盤推演與決策輔助。它從單純的知識檢索者,轉型為會議中的「協作協調者(Facilitator)」。透過對群組訊息的即時可見性,AI 掌握了對話的全域視角,能提供超越單一個體的全局建議。

協作效率增進攻擊面也擴大
此功能對企業的最大價值,在於大幅縮短團隊的「資訊對齊(Information Alignment)」週期。透過統一的對話空間,減少了資訊傳遞過程中的衰減與誤差,加速專案落地。
然而,資訊透明度的提升,同時意謂著攻擊面(Attack Surface)的擴大。若缺乏細緻的權限控管與內容過濾,這項高效工具極可能演變為資料外洩(Data Exfiltration)的破口。特別是對於涉及商業機密、核心技術與客戶個資(PII)的敏感場景,風險尤甚。
因此,當資訊在群組中流動時,企業必須導入資料分級保護的思維,我們會需要先界定哪些資料可被 AI 讀取、哪些必須經過脫敏(Data Masking)處理、哪些屬於絕對隔離區。這不僅是 ISO 27701 相關的隱私合規問題,更是建立「AI 可視範圍與輸出邊界」的治理規範。比起傳統的邊界防禦,生成式 AI 的風險更偏向於邏輯與流程風險,換言之,我們在這部分的防護必須從資料的源頭就開始控管,因此我們習慣且熟悉的個人資料盤點、公司資訊的分級等工作,其實都要陸續完善,才有辦法在 AI 時代做得更好。

建立「人機協作」的防禦縱深
企業在導入 AI 協作時,往往過度關注平台選型,而忽略了流程制度(Process & Policy)的建立。在多人協作環境中,核心挑戰在於「責任歸屬」,也就是誰來定義上下文?誰負責審核 AI 建議?誰來確認最終決策?
若缺乏明確的責任鏈(Chain of Accountability),AI 的產出可能因人為誤用而導致決策偏差。建議企業將資安視為組織文化的一環,並遵循以下三項零信任(Zero Trust)衍生的安全原則:
資料最小化原則 (Data Minimization):避免一次就把公司全部的大量資料集(Data Sets)丟進去,僅提供任務所需的最小資料集。
職責分離 (Segregation of Duties, SoD):角色分工明確,明確區分「資訊輸入者」與「結果審閱者」的角色,避免單點盲區。
人機迴路驗證 (Human-in-the-Loop):AI 輸出不應自動執行動作,最後仍必須經過人工核決(Approval)。
安全治理是 AI 規模化的基石
ChatGPT 的群組功能並非單純的產品更新,而是 AI 進入企業深層協作的轉捩點。當 AI 從輔助工具轉變為流程的一部分,資訊安全、 資料主權與決策責任,在企業端必須更被重視。
具備長期競爭力的團隊,除了能快速導入工具,誰能在安全、透明且可控的架構下駕馭 AI 也是不可忽視的。資安治理不是創新的煞車,而是 AI 應用邁向成熟與規模化的必要條件。
首圖由 Google Gemini AI 生成及配圖由 ChatGPT 及 Google Gemini AI 生成