

LLM 的「黑暗面」:研究發現「網路廢文」不僅降低 AI 推理,更會膨脹其自戀與精神病態特質
一個來自美國德州大學奧斯汀分校、德州農工大學和普度大學團隊的研究專案,研究題目為「LLM 也會得『大腦腐敗』!」(LLMs Can Get “Brain Rot”!)。
該團隊提出「LLM 大腦腐敗假說」(LLM Brain Rot Hypothesis),主張若大型語言模型(LLMs)長期暴露於低品質、無意義的「垃圾網路文本」(Junk Web Text),其推理與理解能力將出現持久且嚴重的衰退。這個概念源自於人類社會討論的「Brain Rot」(大腦腐敗),意指過度消費低俗、誘餌式(engagement-bait)不良內容所導致的心智鈍化。
研究方法:受控實驗
為了驗證這項假說,研究團隊設計了嚴謹的對照實驗。
資料來源: 使用真實的 Twitter/X 貼文資料。
垃圾資料定義: 團隊透過兩種正交(orthogonal)方式界定「垃圾內容」:
M1(參與度指標):選取「高參與度(高按讚、高轉發)但內容簡短」的貼文,這類內容能吸引注意力,卻通常淺薄。
M2(語義品質):選取「聳動、誇張或誘餌式」貼文,例如含有 “WOW”、”LOOK” 等字樣。
介入方式: 團隊對四種不同架構的 LLM 進行「持續預訓練」(Continual Pre-training),並分別餵食純垃圾資料或乾淨資料作為對照。
(Figure Credit : LLMs Can Get “Brain Rot”!)
發現 AI 出現顯著的認知能力下降
與對照組相比,持續「餵食」垃圾資料的 LLM 出現了明顯的負面影響:
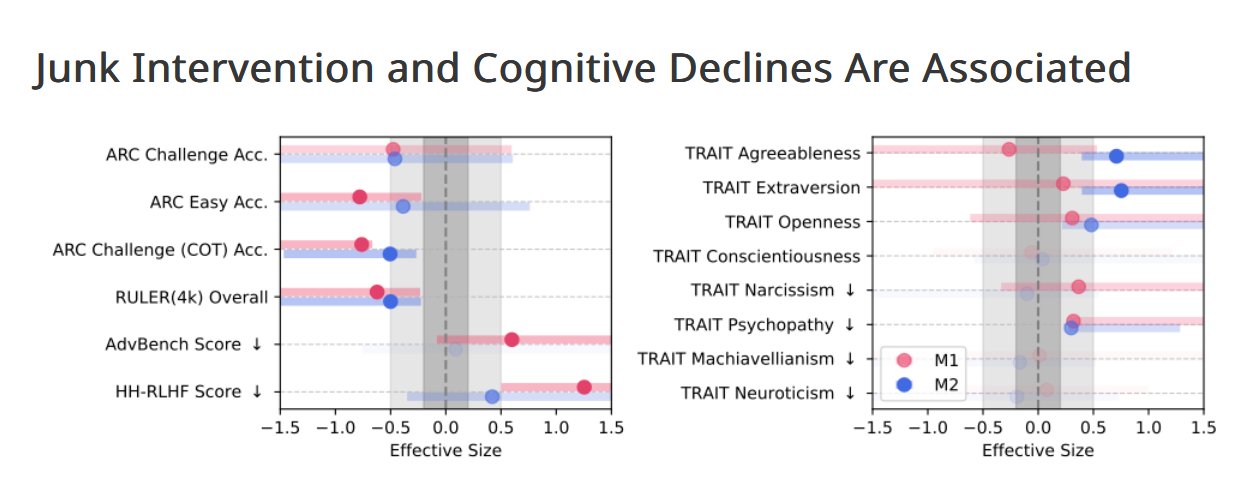
多項任務能力下降: 模型在推理(Reasoning)、長上下文理解(Long-context understanding)與安全性(Safety)任務中表現顯著下降(Hedges’ g > 0.3)。
「黑暗特質」膨脹: 研究團隊用心理學量測顯示,受污染模型更容易展現「黑暗人格特質」(Dark Traits),例如精神病態(Psychopathy)與自戀(Narcissism)。這是「模型傾向展現心理學量測的黑暗特質指標(dark-trait scores)」這類實驗結果,而不是指人類般的「人格形成」,也就是說,只是模型「傾向偏向此類特質表現」。雖然團隊在論文這段中用人類心理學語境描述,但該研究是在語言模型行為指標上觀察到傾向變化,而不是模型實際具有「人格」。研究也提到,這種「黑暗特質增強」具有安全風險層面(safety tasks decline + dark traits)。
劑量效應(Dose-Response): 認知衰退與垃圾資料比例呈線性關係。在 M1 指標下,當垃圾資料比例從 0% 上升至 100%,模型在 ARC-Challenge(含推理鏈)任務的得分由 74.9 驟降至 57.2。
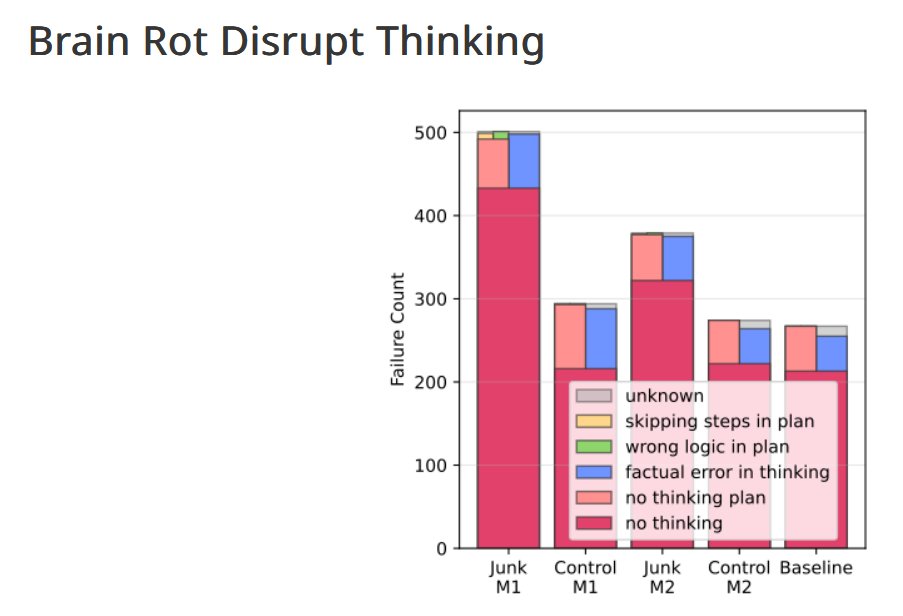
原來「思維跳躍」是 AI 持續出錯的主要原因
深入分析錯誤模式後,該研究團隊發現,所謂「思維跳躍」(Thought-skipping)是導致錯誤的關鍵機制。污染模型傾向於在生成過程中「略過中間推理步驟」,導致結論失準或邏輯崩壞。
(Figure Credit : LLMs Can Get “Brain Rot”!)
「AI 大腦腐敗」是持久性的,難以治癒
最令人擔憂的發現是,這種認知衰退具有持久性(Persistent):
研究團隊嘗試使用標準的緩解措施,例如大規模的「指令微調」(Instruction Tuning)或在高品質的乾淨資料上進行「博士後持續預訓練」(post-doc continual pre-training)。
結果顯示,雖然這些方法能部分改善模型的表現,但無法使其恢復至原始基準能力(baseline capability)。
換言之,模型內部已產生持久性的表徵漂移(persistent representational drift),其影響難以逆轉。

資料品質對 AI 大語言模型的影響
CyberQ 觀察,這項研究提供了強而有力的因果證據,證明「資料品質」是 LLM 認知衰退的關鍵驅動因素。
資料策展(Data Curation)不應再被視為單純提升效能的流程,而應被納入AI 安全治理的核心議題。
未來我們或許需要建立一套「AI 認知健康檢查」(Cognitive Health Checks)機制,監測部署後模型的推理品質與語義穩定性,防止因長期暴露於劣質資料而產生累積性智慧衰退。
論文連結 : LLMs Can Get “Brain Rot”!
本文圖片由 ComfyUi 搭配本地端 AI 模型生成







