

前身是日本大廠東芝半導體的記憶體與儲存大廠鎧俠(Kioxia)最近發表了兩項高效能運算(HPC)與人工智慧(AI)產業關注的重大消息:一項是與 GPU 巨擘 NVIDIA 合作,開發速度將比現行 SSD 快上近百倍的新世代產品 ;另一項則是推出業界首款容量高達 245.76TB 的 LC9 系列 SSD,再次刷新儲存密度的世界紀錄,這兩項突破性的發展,以及凱俠成功開發出較低功耗下實現5TB大容量、64GB/s高頻寬的快閃記憶體模組原型,都引起業界對 AI 資訊架構進化方向的關注。
為 AI 而生:直接連接 GPU,實現近百倍的讀取效能
隨著生成式 AI 的爆發性成長,資料傳輸瓶頸已成為限制 GPU 運算能力發揮的主要障礙。為此,鎧俠正依循 NVIDIA 的前瞻性提案,著手開發一款能夠直接與 GPU 進行資料交換的新型 SSD。此專案的核心目標是徹底革新傳統的資料存取路徑,透過繞過 CPU,讓 SSD 直接成為 GPU 的高速資料暫存區,設法大幅提升數據傳輸效率。

鎧俠這次設計開發效能的規格極為驚人,最關鍵的效能部分,隨機讀取效能將達到每秒 1 億 IOPS(每秒輸入輸出操作次數),約為當前高效能 SSD 的 100 倍。而為了達到 NVIDIA 開出來期望的 2 億 IOPS 終極目標,鎧俠計畫透過兩組 SSD 協同運作來實現,為了支撐如此龐大的數據流量,此產品預計將支援 PCIe 7.0 標準。
此產品的問世,將有望取代部分目前在 AI 伺服器中價格高昂的 HBM(高頻寬記憶體),為市場提供一個更具成本效益、高彈性且易於擴充的記憶體解決方案。鎧俠預計在 2027 年前將此劃時代產品推向市場,屆時將為 AI 模型的訓練與推論帶來更高效率與兼顧成本和容量的 AI 基礎建設新環境。
根據 Kioxia 過去公開過的資訊,可以關注該公司推出的高頻寬快閃記憶體,也就是 HBF 技術,這能夠解決 NAND 快閃記憶體原本的局限。當初是 SanDisk 最先開發了該標準,而這種技術 HBF的最大優勢是超大的容量,每個裝置可擴展到數 TB 之多。
這種設計,可讓 AI 資料中心能利用龐大的快閃記憶體儲存池去來處理推理工作的資料,分流高貴 HBM 記憶體的負載。Kioxia 如果要達成NVIDIA 設定的效能目標,不只是能用 HBF 技術,該公司還有 XL-Flash 這種高效能 NAND 技術可搭配實現。
245TB LC9 系列創下 SSD 密度新紀錄,有助於企業儲存與NAS同時擴充容量與效能
在追求極致速度的同時,鎧俠也在高密度儲存領域的腳步繼續穩健地成長。該公司日前發表的 Kioxia LC9 系列企業級 NVMe SSD,具備高達 245.76TB 的驚人容量,獲得今年度記憶體與儲存盛會 FMS 2025的「最佳展品獎」。

Photo Credit : Kioxia 官方公布的 LC9 系列 SSD 產品照,標榜採用該公司的 BiCS FLASH,根據資料是第八代晶片。
LC9 系列可說是專為生成式 AI、向量資料庫與大型資料湖(Data Lake)等資料密集型工作負載設計的新世代產品,其關鍵技術以該公司新版本的 3D NAND 搭配 CBA 晶片封裝為主。
3D NAND 部分是採用鎧俠第八代 BiCS FLASH QLC(4-bit-per-cell)3D 快閃記憶體技術,採用 CBA(Chip-on-Board Assembly)封裝,在單一晶片上成功堆疊了 32 個 2Tb 晶片,讓儲存密度達到史無前例地高。不但如此,鎧俠設計的相關功能與架構,能減少寫入放大,同時也提高耐用性,這對產業來說是重要的。
因應產業需要,LC9 也提供不同的規格,包括標準 2.5 吋、EDSFF E3.S(最高 122.88TB)以及達成最高容量的 E3.L(最高 245.76TB)等多種尺寸,以搭配不同的伺服器架構。在理想的配置設計下,如果規劃全快閃記憶體的儲存設備或 NAS 系統,最高可以產出 9PB 容量的機種來,以伺服器可行的量產品來說,也會有個數百 TB 到 1PB 容量的水準持續供應給業界,這對企業儲存產業、AI 基礎架構來說都是不簡單的技術進步。
在效能方面,循序讀取速度高達 12GB/s,寫入速度為 3GB/s,已經可滿足新資料中心對於高效能、高容量儲存的需求,該公司已陸續提供 LC9 系列的樣品給客戶測試。
低功耗下實現5TB大容量、64GB/s高頻寬的快閃記憶體模組,加速邊緣運算等應用
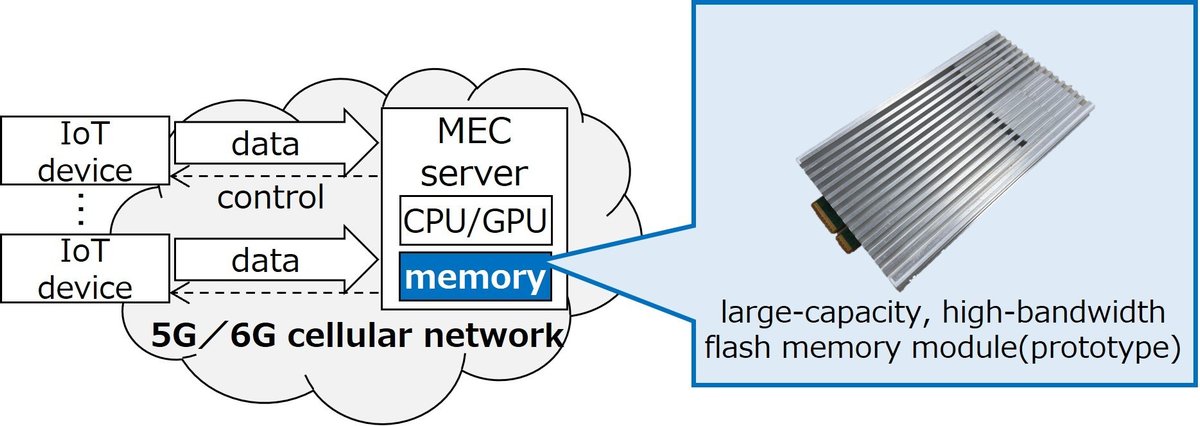
另外,根據該公司最新的這篇新聞稿 Kioxia成功研發5TB大容量、64GB/s高頻寬快閃記憶體模組原型 ,可望加速在物聯網(IoT)、巨量資料分析和先進 AI 處理在行動邊緣運算 (MEC) 伺服器等場景中的應用。
(Figure Credit: Kioxia )
Kioxia 開發了一種新的快閃記憶體模組組態,透過將快閃記憶體晶片顆以菊輪鍊連接方式來加速連接,每個記憶板都連接著一串控制器,而非採用匯流排連接。因此,即使增加快閃記憶體數量,頻寬也不會下降,且能實現超越傳統限制的大容量。
另外,該公司在這項模組中,也研發了支援 128Gbps 頻寬的 PAM41 高速低功耗收發器,讓儲存控制器之間的菊輪鍊連接採用高速差分串列訊號傳輸(而非並行訊號傳輸)以減少連接數量,並利用PAM4(四階脈衝幅度調變)技術,目的是在低功耗下實現128 Gbps的更高頻寬。
透過應用 128 Gbps PAM4 高速低功耗收發器以及快閃記憶體預取技術,這款原型模組,和伺服器的主機介面採用PCIe 6.0(64 Gbps,8通道)的配置下,在功耗低於40瓦時,可實現 5TB 的容量和 64GB/s 的頻寬。他們的這起成果是在日本國家研發機構,日本新能源產業技術綜合開發機構 (NEDO) 委託的「後5G資通訊系統基礎架構強化研發專案 (JPNP20017)」架構中去實現的。
展望未來:技術藍圖清晰,持續引領產業創新
除了上述三項重大發表,鎧俠對外也公布了第九代與第十代的 BiCS FLASH 技術藍圖,顯示其在快閃記憶體領域的研發動能,很值得期待。
CyberQ 觀察,從追求極致 IOPS 以消除 AI 運算瓶頸,到不斷突破物理極限以擴展儲存容量,鎧俠正從「速度」與「密度」兩個面向,為 AI 時代繼續構建堅實的基礎設施元件,NVIDIA 選擇鎧俠擔任 AI 運算架構的次世代儲存合作夥伴絕非偶然,這家大廠的每一步,都值得我們持續關注。
首圖由Google Gemini AI 生成








