OpenAI 終於在 2025 年 8 月釋出首個以 ChatGPT 架構為基礎、可供本地端部署的開源模型 gpt-oss,分成gpt-oss-20b 與 gpt-oss-120b兩個不同參數的版本,前者因為比較小,可以在有 16GB 以上VRAM記憶體顯示卡的電腦執行,或者是統一記憶體容量夠的電腦執行 (NVIDIA新款AI電腦、蘋果 Mx 系列筆電),為 AI 社群投下一顆震撼彈。
根據 OpenAI 的說法,這兩個模型都採用彈性的 Apache 2.0 授權條款發佈,在推理任務上的表現優於同規模的開源模型,具備強大的工具使用能力,並針對消費級硬體上的高效部署進行了最佳化。它們採用強化學習與結合 OpenAI 最先進內部模型 (包括 o3 及其他尖端系統) 所啟發的技術進行訓練。
OpenAI 還說,gpt-oss-120b 模型在核心推理基準測試中的表現趨近 OpenAI o4-mini,同時可在單一 80GB GPU 上高效運作。gpt-oss-20b 模型在常見基準測試中的表現與 OpenAI o3‑mini 相近,且僅需 16 GB VRAM顯卡記憶體,即可在邊緣裝置上執行,非常適合用於裝置端應用、本地推論,或在無需昂貴基礎設施的情況下進行快速最佳化。(最少要有 16GB 的 NVIDIA 顯示卡,不然會很慢)
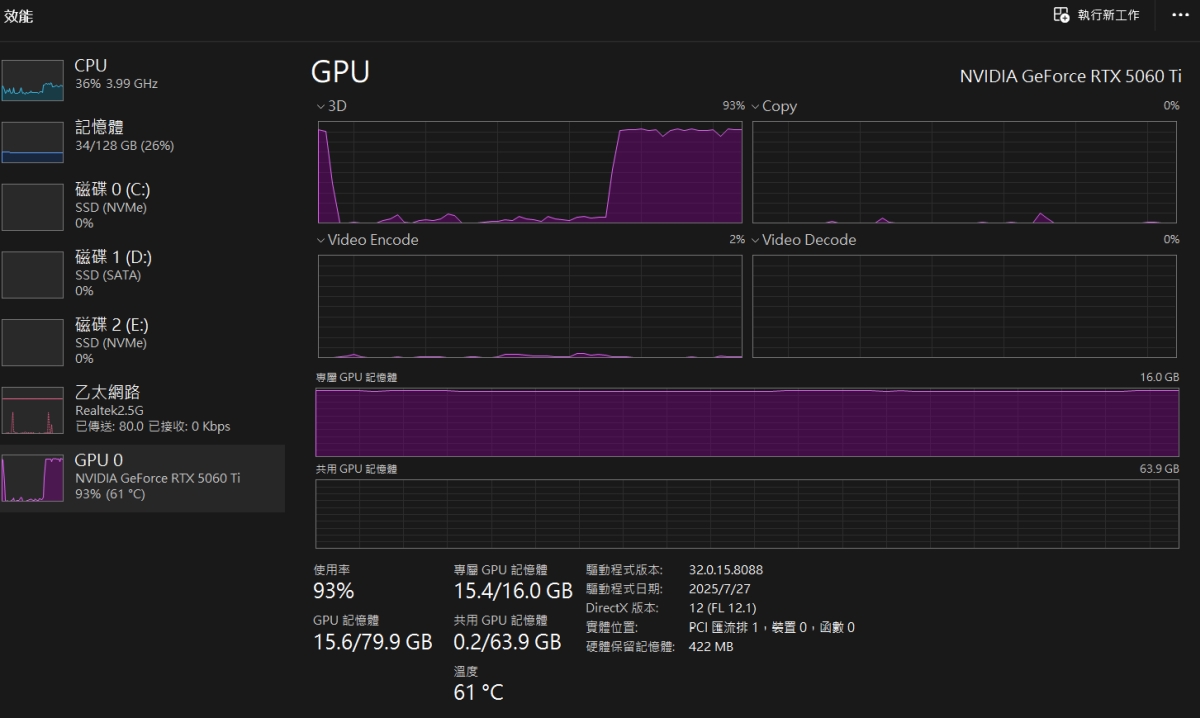
上圖是 CyberQ 測試 cpt-gss-20b 在本地端電腦上執行時的資源耗用截圖,GPU 記憶體和運算當然是吃滿的。
另外,這兩款模型在工具使用、少量示範函式調用、思路鏈推理 (可見於 Tau-Bench 智慧體評估套件的結果)以及 HealthBench 測試中表現優異,甚至超越 OpenAI o1 和 GPT‑4o 等部分專有模型 。
gpt-oss-20b 與 gpt-oss-120b
這次開源共包含兩個版本的模型:
| 模型 | 圖層 | 總參數量 | 每個字元啟動參數數量 | 專家總數 | 每個字元啟動的專家數量 | 上下文長度 |
| gpt-oss-120b | 36 | 117b | 5.1b | 128 | 4 | 128K |
| gpt-oss-20b | 24 | 21b | 3.6b | 32 | 4 | 128K |
gpt-oss-120b:總參數1170億,每個token預設啟用約51億參數參與推理。定位為高推理需求的生產型應用,可在單張80GB VRAM 的 H100 GPU上運作。
gpt-oss-20b:總參數210億,每個token啟用36億參數,主打低延遲與本地部署場景,僅需 16GB VRAM 記憶體的顯示卡即可執行,適合邊緣設備或客製化應用。
實際執行 gpt-oss-20b 的效果
我們部署在我們自己電腦上的 OLLAMA 搭配 Open WebUI 中去執行,效果確實不錯,也能製作表格和更多衍生任務。

gpt-oss 的離線版 ChatGPT 模型是採用 Apache 2.0授權,這樣對開發者和社群都是很友善的,允許我們能自由進行研究、修改與商業部署,不用擔心專利風險或copyleft 條款的限制。
gpt-oss 其他主要的功能特點還包含:
針對程式碼任務,可支援函式呼叫、Python程式碼執行、網頁查詢與結構化輸出。
提供完整CoT(思維鏈)推理紀錄,這點是很不錯的。
訓練時導入MXFP4原生量化技術,強化運算效率。
推理資源配置彈性,開發者可依需求去設定高、中、低等級來進行。
下方是我們在 Open WebUI 中管理 Ollama 的模型頁面,下指令 ollama run gpt-oss:20b,用管理模型頁的下載功能去下載 gpt-oss-20b 模型,它的名稱為 gpt-oss:20b。如果是更大版本的模型,名稱為 gpt-oss:120b 。
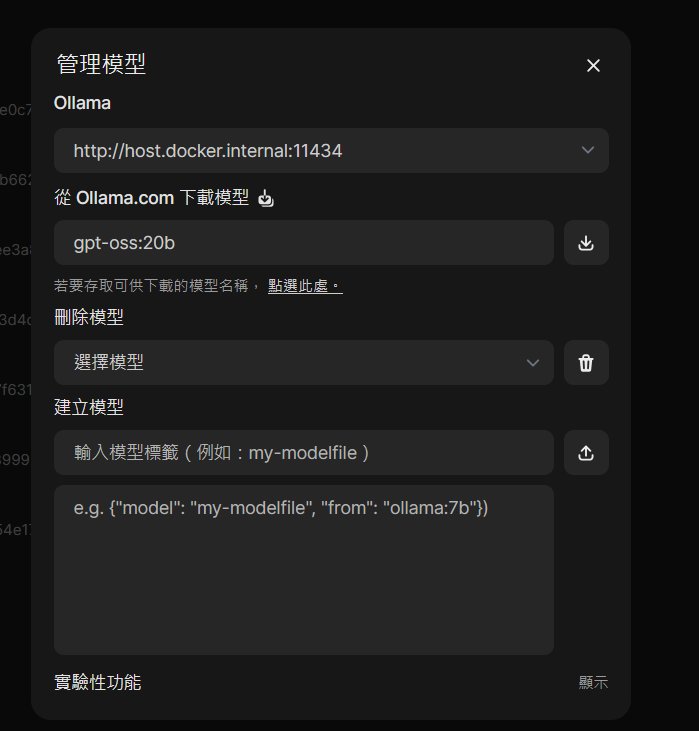
檔案不大,12.8GB而已,很快就下載完畢。
完成之後會顯示已成功下載。
開啟之後的畫面是這樣,和其他在 Ollama 跑模型的輸入框都是一樣的。

有搭配 NVIDIA 顯示卡後,執行的效率就很快了,問題的回答與反應都很好,以這個 20b 參數的小模型來說,接近之前我們在線上 ChatGPT 官方網站跑 OpenAI o3‑mini 的效果接近,然後實際應用當然是沒有官方最新版的大模型好用,但是呀,這可是開源模型可以在本地端跑的,可以再訓練自己的資料集,以及針對不同任務下,我們去自訂,開發人員和研究人員可以在自己的環境中客製化 AI ,推動新的 AI 工作流程。
對個人來說,日常的問題在不耗費雲端付費 token 的情況下,可以用這個模型來完成一些不需要太深入推論的日常任務,已經是相當好用了,推薦大家部署在具備 NVIDIA顯示卡的機器上,記憶體越多越好,不論是機房內的伺服器、有安裝 NVIDIA 顯示卡的 QNAP NAS (如QAI-h1290FX NAS),以及家用電腦和工作站都很適合。
資源夠多的機構就可以使用 120b 參數的模型 gpt-oss-120b ,gpt-oss-120b 在競賽編碼 (Codeforces)、一般問題解決 (MMLU 與 HLE) 以及工具調用 (TauBench) 方面的表現優於 OpenAI o3‑mini,並與 OpenAI o4-mini 相當或更佳。此外,它在健康相關查詢 (HealthBench) 及競賽數學 (AIME 2024 與 2025) 上的表現更勝 o4-mini。gpt-oss-20b 雖然規模較小,但在相同測試中與 OpenAI o3‑mini 相當或更佳,甚至在競賽數學與健康領域的表現上超越了 o3‑mini。
功能多樣,支援網頁搜尋與繼續跟進
實務上使用,在 gpt-oss 模型上,同樣可以自動產生跟進的問題和往下延伸。
而只要有先設定好搜尋引擎的 key ,就可以如下方圖片所示,支援網頁搜尋,請先自己去 Google 等搜尋引擎設定好客製化的搜尋引擎 api key ,再把 key 導入於 web-ui 與 ollama 中使用即可,這樣可讓 cht-oss 本地端小模型的能力增加,透過搜尋來強化基本日常任務的處理能力。
私密資料不外流,進階還能處理程式碼、用語音問問題
支援語音搜尋,這樣你在家裡或公司都可以用口說的方式問問題,讓 gpt-oss 回答你。
以在家或辦公室內透過手機來問問題的應用場景來說就很適合。

手機版網頁的界面和跟進問問題的 UI 與回應是友善的 :
而程式碼的編寫與直譯,在 gtp-oss 進行不要太複雜的小型專案,也可以達到可用的程度,但不如 Claude.ai 的程式撰寫功能強大,你可以把它當作一些程式碼在本地端的輔助撰寫工作,困難的問題再拿去給 Claude.ai 去展開也是可行的方式。
以上諸多任務中,使用本地端 LLM 在企業與家中最大的好處是,你所有覺得有個人隱私、公司商業機密的內容,都可以在本地端的電腦或伺服器、NAS 上實現,而不用擔心資料外流的問題,真的有需要上雲處理的,就記得要去識別化個人資訊,避免之前新聞報導過的 ChatGPT 雲端對話紀錄被分享公開、可搜尋到的資安議題。
部署和執行本地端 AI 模型,可以參考我們的方式,使用 gpt-oss 與其它包括微軟 phi4、Google gemma3 等高品質可在地端執行的 LLM 模型,提升你的生產力和個人學習、資料整理等多種日常任務的工作。
相關資源 :
Hugging Face 頁面 : 20b 版本 / 120b 版本
本文最上方的標題特色圖片,由 AI 所產生。