

AI 運算的典範正在轉移,從仰賴遠端 API 的雲端服務,正式邁入全新的代理人電腦(Agent Computer)時代。在這個新架構下,電腦的主要操作者不再是人類,而是能夠自主推理、規劃並執行複雜任務的 AI 代理人。隨著硬體記憶體容量與頻寬的突破,將龐大的代理人系統部署於本地端已成為各大廠的必爭之地。
近期,AMD 與 NVIDIA 紛紛針對本地端 AI 代理部署提出了截然不同的硬體與軟體解決方案。CyberQ 解析觀察 AMD 最新釋出在 AMD Ryzen AI Max+ 上的 OpenClaw 本機部署方案,並結合近期我們自己在 GB10 實作的經驗,探討 AMD 方案與 NVIDIA DGX Spark 之間的架構差異與應用場景。
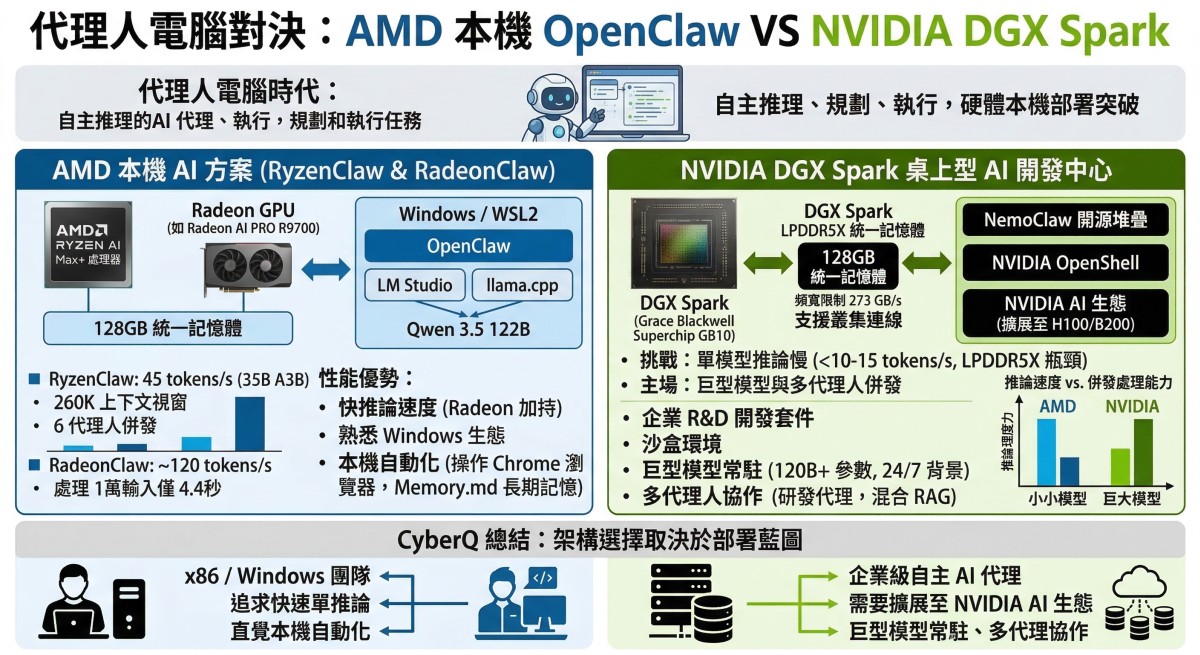
AMD 用 RyzenClaw 與 RadeonClaw 展現本機 AI 實力
AMD 近期展示了如何透過 Ryzen AI Max+ 處理器與 Radeon GPU,打造被稱為 RyzenClaw 與 RadeonClaw 的本機代理人工作站。這套架構的核心優勢在於將龐大的模型部署於開發者熟悉的 Windows/WSL2 環境中。
透過結合 LM Studio、llama.cpp 以及具備 128GB 統一記憶體的 Ryzen AI Max+ 平台,開發者可以在不依賴雲端的情況下,順暢執行如 Qwen 3.5 122B 這類較吃記憶體的大型地端 AI 模型。在 AMD 的最佳已知配置(BKC)測試中:
RyzenClaw (128GB 統一記憶體): 執行 Qwen 3.5 35B A3B 模型時,能提供約 45 tokens/s 的推論速度,支援高達 260K 的上下文視窗,並允許 6 個代理人同時併發運作。
RadeonClaw (Radeon AI PRO R9700): 推論速度則可大幅躍升至 120 tokens/s,處理一萬個輸入 token 僅需約 4.4 秒,為本地端代理人提供極快的反應能力。
這套方案不僅解決了過往 Windows 用戶在部署複雜 AI 系統時面臨的環境建置問題,更深度整合了本地端的 Embedding 模型來實現 Memory.md 長期記憶功能,甚至能透過 WSL2 賦予 AI 代理人直接控制 Chrome 瀏覽器的能力,讓自動化工作流程得以在本地端完整閉環。
NVIDIA DGX Spark 與 NemoClaw 聚焦桌上型 AI 開發中心
相對應地,NVIDIA 則以定價約 4,000 美元級距的 DGX Spark 搭配最新的 NemoClaw 開源軟體堆疊,其他合作夥伴則有較便宜的 1TB 容量機種約三千多美元,主攻桌上型 AI 開發中心,以及迷你資料中心概念。DGX Spark 搭載了基於 ARM 架構的 Grace Blackwell Superchip (GB10/GB300) 以及 128GB LPDDR5X 統一記憶體,並支援最高 4 節點的叢集連線。
它的產品定位並非單純的高階消費級顯示卡,而是一個為企業 R&D 打造的開發套件。開發者可以在本地端的 DGX Spark 上透過 NVIDIA OpenShell 進行原型開發,確保自主 AI 代理在沙盒環境中安全執行後,再無縫擴展至 H100 或 B200 等資料中心基礎設施。
不同需求開發者實作的差異
探討這兩套系統的實際表現,開發者實作的面向,會依據需求而有差別。以 NVIDIA 來說,部署 AI 代理人與 DGX Spark 在市場上呈現出極度兩極化的感想。CyberQ 實測也有同感,它有這兩個問題。
1、記憶體頻寬的雙面刃與推論速度爭議
許多期待 DGX Spark 能成為推論神機的開發者遭遇了落差。實際上 DGX Spark 的 LPDDR5X 統一記憶體頻寬僅約 273 GB/s,這與 RTX 4090 或 RTX 6000 等動輒 1,000 至 1,800 GB/s 的 GDDR 顯示記憶體架構提供的頻寬有顯著的差距。
當執行 4-bit 量化的 34B 甚至 120B 模型時,受限於記憶體傳輸瓶頸,單一 token 的生成速度可能低於 10-15 tokens/s,導致部分追求極致推論速度的開發者或用戶認為其性價比,不如組裝多張 RTX 顯示卡的工作站。
2、巨型模型與多代理人併發的絕對主場
然而,對於真正投入複雜多代理人(Multi-Agent)系統與 Mixture of Models (MoM) 開發的資深工程師而言,DGX Spark 的評價卻截然不同。在建置如研發工程師代理人或混合 RAG 堆疊時,問題往往不是每秒能吐出多少字,而是能否將超過 100B 參數的巨型模型完整塞進記憶體且不需頻繁卸載。
CyberQ 利用 DGX Spark 執行 Qwen3-80B 進行本地與雲端混合的 RAG 任務時,能維持高度的併發處理能力與極低的端到端延遲(低於 150ms),而 NVIDIA 最新推出的Nemotron-3 系列模型,不論是 Nemotron-3 Super 120B 或 Nemotron-3 Nano 30B,在 GB10 上的表現都不錯。對於長時間執行、需要在背景同時開啟多個子代理進行推理、規劃與工具呼叫(Tool Calling)的任務,DGX Spark 的大容量統一記憶體與高併發架構展現了強大的穩定性。
架構選擇 AMD 或 NVIDIA 取決於部署藍圖
CyberQ 認為,AMD 與 NVIDIA 在代理人電腦的佈局上展現了不同的哲學。
若公司內的團隊熟悉 x86 架構,高度依賴 Windows 生態系,且追求快速的單一模型推論與直覺的本機自動化(如操作本機瀏覽器),AMD 結合 OpenClaw 與 WSL2 的方案能提供極佳的性價比與開發親和力,特別是在 Radeon PRO GPU 的加持下,推論速度表現會比 GB10 好。
相反地,若團隊的目標是開發企業級的自主 AI 代理,後續需要拓展至龐大的 NVIDIA AI 生態系,或是需要一個低功耗、能讓 120B 等級模型常駐於記憶體中進行 24/7 背景多代理人協作的開發節點,NVIDIA DGX Spark 搭配 NemoClaw 將會是打通從桌上型到資料中心這條康莊大道的首選。






