在上一篇《打造零停機企業儲存架構,QNAP High Availability 雙機熱備援實測與 Failover 驗證》中,我們成功建置了基於 ZFS 與 Active-Passive 架構的高可用性儲存叢集。然而,當這套強大的儲存系統要正式介接至核心的虛擬化(如 VMware vSphere、Microsoft Hyper-V 或 Proxmox VE)叢集時,我們必須面對一個更嚴苛的挑戰,如何在 HA 進行節點切換的數十秒空窗期內,確保叢集內上百台虛擬機(VM)不會因為儲存 I/O 逾時而發生檔案系統損毀、藍白畫面(BSOD)或 Kernel Panic?
VMware 的答案就在於 iSCSI 儲存協定與 MPIO(Multipath I/O,多重路徑輸入輸出)技術的結合;而在 PVE 環境下,若採用 NFS 作為儲存協定,其容錯機制與 iSCSI 截然不同。NFS 仰賴的是底層網路的實體備援(Network Bonding)以及掛載設定(Mount Options)的深度調整。
以下,是 CyberQ 實作 PVE 與 VMware ESXi 虛擬化環境與 QNAP HA 儲存無縫接軌的進階調整實作。
為什麼有了 HA,還需要 MPIO?拋棄單點故障的底層邏輯
許多企業在建置 HA 叢集後,往往只拉一條網路線將虛擬化主機連上 HA 的虛擬 IP(Cluster IP)。這種預設狀態存在著致命的潛在風險。
首先是網路單點故障和頻寬瓶頸。NFS 的傳輸極度依賴單一 IP 的連線穩定度。若未在 PVE 節點配置網路綁定(Bonding),只要一條網路線或 Switch 埠故障,VM 就會立即卡死。同時,所有 VM 的儲存流量擠在單一實體網卡,完全無法發揮現代伺服器多網卡的吞吐量。
其次是切換空窗期的 I/O 中斷。當 QNAP HA 叢集中發生任何硬體或網路故障並觸發 Failover 時,被動節點接管虛擬 IP 與 ZFS 儲存池約需 15 到 30 秒。若 VMware 或 PVE 端使用預設的儲存掛載設定,很容易在短時間內判定連線逾時,進而向 VM 的 QEMU 程序回報 I/O Error,導致 Guest OS 崩潰。
透過 MPIO 架構與進階 NFS 參數,我們不僅平時能實現流量負載平衡(Load Balancing),在遭遇突發斷線或 HA 切換時,更能透過多路徑重試機制與自訂 Timeout 設定,賦予虛擬機憋氣續命的能力,達成真正的 Zero Downtime。
企業級儲存網路的實體隔離與架構法則
在進入 Hypervisor 的底層設定前,實體網路的規劃直接決定了基礎設施的容錯能力。
基礎共通原則是絕對隔離與效能解放
儲存網路(iSCSI 或 NFS)極度敏感且佔用高頻寬,必須劃分獨立的 VLAN,並與一般上網流量、VM Network 或 Corosync 叢集網路絕對隔離。預算許可下,強烈建議使用專屬的 10GbE / 25GbE 實體交換器。
在企業級環境中,最佳做法是同時採用獨立 VLAN 與獨立實體 NIC,若條件允許則使用專屬儲存交換器,以避免儲存流量與一般網路互相競爭。
此外,應全面啟用 Jumbo Frame(MTU 9000)。在 Hypervisor、實體 Switch 以及 QNAP NAS 的網卡上,全鏈路將 MTU 修改為 9000,可大幅降低 Packet Per Second (PPS) 與 TCP/IP stack 處理負擔,進而提升高吞吐量情境下的效能。
iSCSI 架構法則建構 MPIO 雙子網域
為了建立具備容錯能力的 MPIO,區塊層級的 iSCSI 應採用雙子網域設計(Dual Subnet):
儲存網路 A:10.10.1.X / 24 (VLAN 10)
儲存網路 B:10.10.2.X / 24 (VLAN 20)
透過不同網段的強制分離,確保單一交換器或網卡失效時,流量能瞬間切換至另一條實體路徑。這是因為 ESXi 透過 Port Binding 為每個 VMkernel 建立獨立 iSCSI Session,而不同子網路可避免路徑選擇衝突,並強制建立多條獨立資料通道。
NFS 架構法則網路綁定與平行調整
檔案層級的 NFS 需透過網路綁定(Bonding)來實現高可用性:
LACP (802.3ad):當實體交換器支援 LACP 時,可建立鏈路聚合群組(LAG),提供多連線負載分散與鏈路備援能力。需要注意的是,LACP 並不會提升單一 TCP Session 的頻寬,單一 NFS 連線仍受限於單一鏈路速度,但多個 VM 或多個 NFS Session 可以在多條鏈路之間分散流量。
Active-Backup:若儲存系統連接到兩台不同的交換器,而未部署 MLAG / vPC 等跨交換器聚合技術,則建議使用 Active-Backup 模式。此模式雖不提供頻寬疊加,但在任一交換器故障時能立即切換至備援路徑,是跨交換器環境中最穩定的高可用架構。
實作佈署 VMware ESXi MPIO 設定
1、QNAP 端的 iSCSI Target 建置
進入 QNAP QuTS hero 建立 iSCSI Target 時,選擇建立區塊層級 (Block-based) LUN。它直接映射到底層 ZFS 儲存池,可避免檔案層級額外的抽象化負擔,在支援 VMware VAAI 的硬體卸載表現上也更為優異。VMFS 在 Block LUN 上還可透過 ATS (Atomic Test & Set) 機制的硬體卸載能力,降低 SCSI Reservation 對多主機存取的影響。
2、ESXi 網路連接埠繫結 (Port Binding)
為儲存網路 A 與 B 各建立一個 VMkernel 介面,並將兩者加入 iSCSI Software Adapter 的 Network Port Binding。完成後,在 Dynamic Discovery 中加入 QNAP 高可用架構提供的兩個虛擬 IP 位址,並重新掃描 Storage Adapter,使 ESXi 建立多條 iSCSI Session。
3、核心調整:Round Robin IOPS 最佳化
ESXi 在多數 iSCSI 環境中預設使用 Round Robin(VMW_PSP_RR),但其路徑切換臨界值預設為 1000 IOPS。在此設定下,系統會先在單一路徑上處理 1000 次 I/O 才切換至下一條路徑,這往往導致負載集中在單一路徑,無法充分利用多條網路通道。 因此在高頻寬 iSCSI 環境中,通常會將切換臨界值降低至 1 IOPS:
esxcli storage nmp psp roundrobin deviceconfig set \
--type=iops \
--iops=1 \
--device=naa.xxxxxxxxxxxxxxxxxCyberQ 提醒。這項設定會使 ESXi 在每次 I/O 操作後立即切換到下一條可用路徑,使 I/O 封包如同拉鍊般均勻交錯地分配到多條實體鏈路上,最大化多路徑架構的頻寬利用率。
需要注意的是,將 IOPS 設為 1 會增加路徑切換頻率,因此會略微提高主機 CPU 的路徑管理負擔。不過在現代多核心伺服器架構下,這種額外負載通常可以忽略不計,而所換得的吞吐量提升往往更加顯著。
若希望未來新增的 LUN 能自動套用相同策略,則可透過 SATP Rule 或自動化腳本進行統一配置,否則每個新建立的 LUN 都需要手動調整其 Round Robin 參數。
實作佈署 PVE NFS 掛載進階設定
PVE 的 GUI 介面預設無法涵蓋所有 NFS 進階選項。完成初步掛載後,必須透過 SSH 編輯叢集儲存設定檔 /etc/pve/storage.cfg。
找到你的 NFS 區塊,修改 options 這一行:
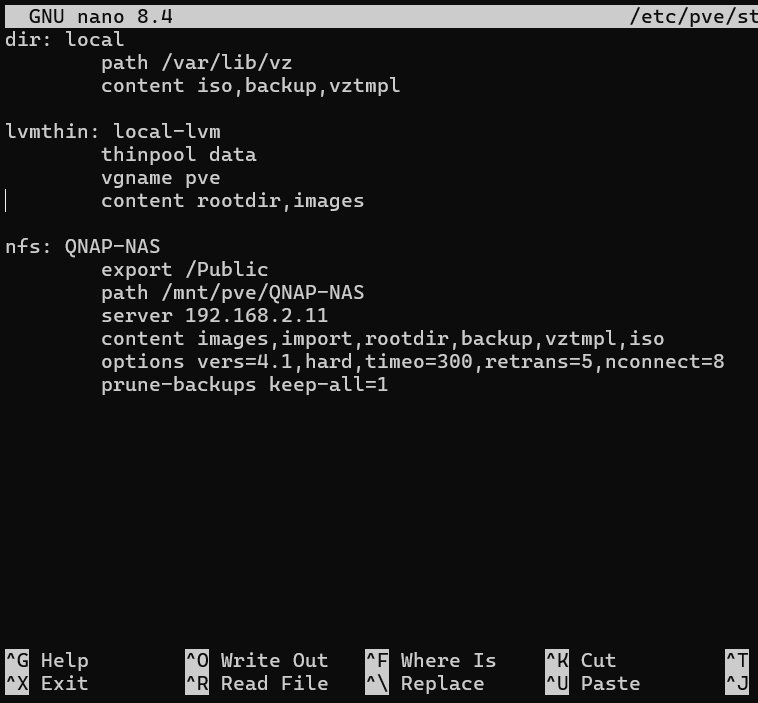
nfs: QNAP-HA-NFS
export /NFS_HA
path /mnt/pve/QNAP-HA-NFS
server 10.10.1.100
content images,iso
options vers=4.1,hard,timeo=300,retrans=5,nconnect=8
關鍵設定說明:
hard:不能使用 soft。hard 模式會強制 PVE 在儲存設備無回應時,持續阻擋(Block)應用程式的 I/O 請求直到伺服器恢復。這能確保資料寫入的強一致性。
(額外說明一下,早期教學常提到 intr 參數,但在 PVE 使用的現代 Linux 6.x 核心中,intr 已被棄用且無實質作用,關鍵在於 hard 與 timeo 的搭配。)
timeo=300:設定每次重試前的等待時間,單位為 0.1 秒(300 代表 30 秒)。
retrans=5:觸發重大逾時警告前的重試次數。
nconnect=8:建立多條 TCP 連線至 NFS 伺服器,這能大幅提升全快閃或 10GbE 以上環境的併發傳輸效能,突破單一 TCP 的瓶頸。
決定生死的 30 秒,Hypervisor 與 Guest OS 的 I/O 掛起機制
當 QNAP HA 發生無預警斷電、Active 節點停機時,必然會產生約 15~30 秒的實體切換空窗期。如果底層或 VM 的磁碟 Timeout 時間短於 NAS 的切換時間,VM 就會直接當機。我們必須建立雙層等待機制:
第一層 底層 Hypervisor 的 I/O 暫停設定
VMware ESXi:修改進階系統設定 Disk.QFullSampleSize 與 Disk.QFullThreshold,讓 LUN 佇列滿載時,I/O 先駐留在佇列中等待。
Proxmox VE:確保 NFS 採用上述的 hard 模式。
第二層 Guest OS 內部的 Timeout 容忍度調校
當 Hypervisor 成功將 I/O 掛起時,Guest OS 自身的容忍值也必須拉長:
Windows VM:開啟登錄編輯程式 HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Disk,將 TimeOutValue 從 60 延長至 120。
Linux VM:修改 SCSI device 的 timeout 參數,在開機腳本或 udev 規則中寫入:
echo 120 > /sys/block/sda/device/timeout
化崩潰為短暫卡頓的結果
透過這套雙層機制,即使底層儲存正在進行激烈的控制器轉移,前端的應用程式只會感受到約 30 秒的畫面卡頓。一旦備援節點接手完成,I/O 就會瞬間湧通,完美避免檔案系統鎖死或當機畫面。
實測網路隔離與儲存 HA 容錯的驗證
設定完成後,我們在系統高負載(Sysbench 連續寫入)的壓力下進行破壞性測試驗證:
測試劇本 A:單一實體線路故障(容錯路徑切換)
觸發動作:直接拔除 QNAP HA 主動節點上的一條主力資料網路線。
架構反應:
VMware:ESXi 偵測到 Dead Path,MPIO 在毫秒間將 I/O 流量無縫切換至儲存網路 B。
PVE:Linux Bond 瞬間將流量切換至備援實體網卡。
驗證結果:前端 VM 寫入圖表僅出現微小波動,作業系統完全未察覺底層斷線,防禦單點故障。
測試劇本 B:主動節點全面隔離(觸發 Failover)
觸發動作:拔除 QNAP HA 主動節點的「所有資料線」與「心跳線」,模擬整台主機從網路蒸發(Node Isolation)。
架構反應流程:
前端 VM 吞吐量瞬間掉至 0,作業系統進入 I/O 等待狀態(Windows 顯示 Pending,Linux 進入 D-State)。
QNAP HA 備援機偵測到 Heartbeat 遺失,強制接管 ZFS 儲存池與 VIP,歷時約 15~20 秒。
在此期間,ESXi 的 MPIO 佇列與 PVE 的 hard/timeo 機制成功將 I/O 攔截在 Hypervisor 層級,未向 VM 報錯。
備援機 VIP 上線,ESXi 與 PVE 瞬間重新連線,流量重新攀升。
驗證結果:長達 30 秒的實體空窗期內,VM 全程未發生系統崩潰,資料庫寫入正常,成功達成近乎零資料遺失(RPO=0)的企業級水準。
CyberQ 觀點:HA 架構的價值在於穩定度
CyberQ 觀察,許多人在建置基礎設施時,往往認為採購了高階 NAS 組成 HA,或是設定了 PVE/VMware 的運算叢集高可用性,系統就萬無一失了。但採購高階硬體只是提供了「容錯的潛力」,唯有透過精細的儲存網路規劃與虛擬化超時容忍度調校,才能真正賦予系統強悍的營運韌性(Operational Resilience)。
在本次測試環境中,ESXi 主機透過兩條 10GbE iSCSI 路徑連接至 QNAP HA 環境,並以 Block-based LUN 建立 VMFS Datastore。每條路徑對應獨立 VMkernel 介面與獨立儲存子網路,並啟用 Round Robin MPIO(IOPS=1)策略。
在預設設定(Round Robin IOPS=1000)下,觀察到大部分 I/O 流量會集中於單一路徑,導致其中一條 10GbE 連線接近飽和,而另一條路徑利用率相對較低。此時整體吞吐量通常會停留在 單條 10GbE 的實際上限區間(約 9–10 Gbps)。
當 Round Robin 切換臨界值調整為 IOPS=1 後,ESXi 會在每次 I/O 操作後即切換路徑,使 I/O 請求在兩條 iSCSI Session 之間平均分配。此時觀察到兩條 10GbE 連線的流量明顯趨於均衡,整體吞吐量可接近 雙鏈路聚合的實際效能上限(約 18–20 Gbps),顯示 MPIO 負載分散機制已有效發揮作用。
除了吞吐量提升外,多路徑架構的另一個關鍵價值在於容錯能力。在測試過程中,透過模擬關閉其中一條實體網路連線或停用交換器連接埠,可以觀察到 ESXi 會在極短時間內將 I/O 流量轉移至剩餘可用路徑,虛擬機的 I/O 操作幾乎不會出現中斷或明顯延遲。
在 VMware 的多路徑管理機制下,這種故障切換通常可在數秒內完成,而對於大多數虛擬機工作負載而言,僅表現為極短暫的 I/O 延遲增加,而非服務中斷。
綜合測試結果顯示,在正確規劃儲存網路、啟用 Jumbo Frame、建立 Dual Subnet iSCSI 架構並調整 Round Robin IOPS 參數後,QNAP QuTS hero HA 與 VMware ESXi 或 PVE 均可可形成一套具備高吞吐量、高可用性與自動容錯能力的企業級儲存平台。對於虛擬化環境中的 VM Datastore、備份儲存或高 I/O 工作負載而言,這樣的架構能在成本與效能之間取得不錯的平衡。
CyberQ 認為, IT 維運上需要很多心理來維護各種好的設定和實作,這也呼應了在 ISO 27001 資訊安全管理系統中,對於營運持續計畫(BCP)與高可用性的嚴格要求。從單點到多路徑,從硬體備援到服務不停機,這套 QNAP HA 結合進階 I/O 調校搭配虛擬化環境與檔案、網路的實戰架構,正是現代化企業資料中心在可控成本下,能夠好好進行實作掌握的防禦深度。