隨著 AI 運算模型日益龐大、高階資料庫存取頻繁,以及諸如 ZFS 儲存池架構與 Proxmox VE 等虛擬化環境的普及,企業內部與實驗室的網路骨幹正快速面臨頻寬瓶頸。10GbE 甚至 25GbE 已逐漸無法滿足節點間動輒數十 GB 的資料交換需求。

在這樣的技術趨勢下,升級至 100GbE 成為了突破 I/O 限制的關鍵。我們透過實際操作畫面和實測,深入探討 QNAP QSW-M7308R-4X 網管型交換器,看看它如何搭配全新的 QSS Pro 管理介面,為高速網路環境提供兼具效能與可靠性的解決方案。

在實務上,企業很少會一次將所有設備升級到 100GbE,通常是核心運算(如 AI 伺服器)與主儲存節點先上 100GbE,邊緣節點或一般虛擬化叢集仍維持 10GbE/25GbE。在導入 AI 伺服器、AI 工作站 或小型的 DGX Spark 這類高效能 AI 設備,傳統 1G 網路自然是早已不敷使用,即便是升級到 10G 網路仍會有會資料吞吐量需求的瓶頸(Data Starvation)產生。

100GbE 核心規格 RS-FEC 確保資料完整性
在進入 100GbE 的領域時,物理層的訊號完整性變得極度嚴苛。從 QSW-M7308R-4X 的「連接埠管理」介面中可以觀察到,當連接埠(如 Port 1 與 Port 2)以 100 Gbps FDX(全雙工) 運作時,系統預設啟用了 RS-FEC(Reed-Solomon Forward Error Correction)。
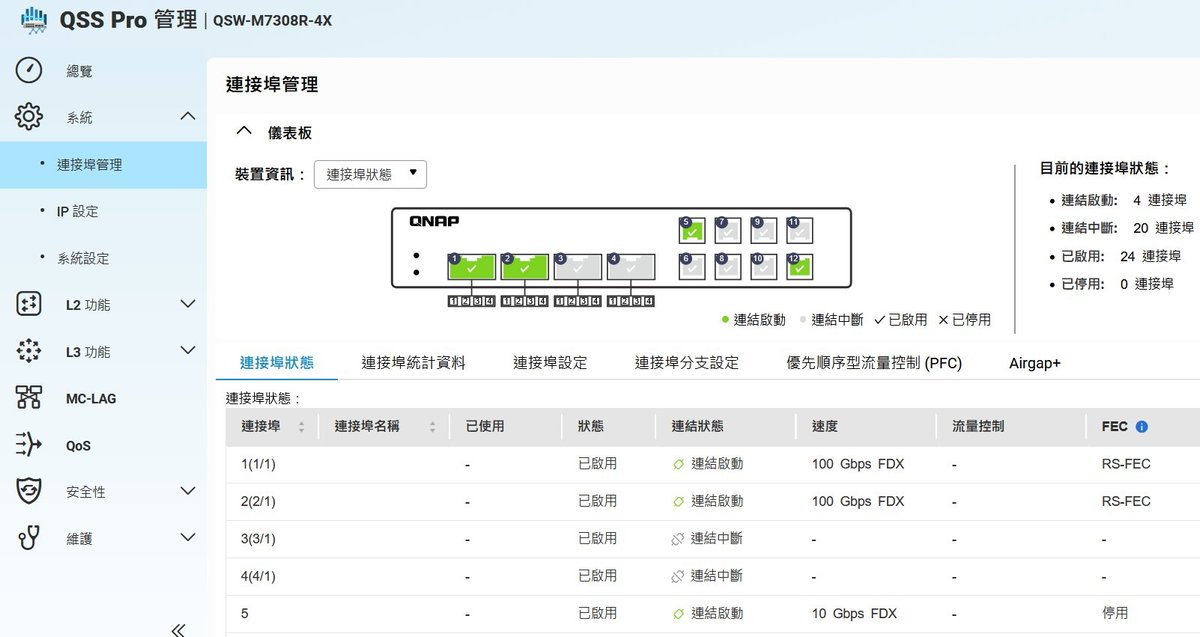
在 100G 網路(特別是使用 DAC 銅纜或長距離光纖時),訊號衰減與雜訊干擾無可避免。RS-FEC 技術能在不大幅增加延遲的情況下,在接收端自動修正傳輸過程中的位元錯誤(Bit Errors),這對於需要高頻寬且零容錯的 AI 訓練叢集或高速 NAS 儲存環境來說,是維持網路穩定的絕對關鍵。
Docker 環境實戰多執行緒 iPerf3 吞吐量測試
為了驗證實際的資料吞吐能力,我們在終端節點透過 Docker 容器化環境(networkstatic/iperf3)使用 Host 網路模式進行了基準測試,並分別測試了不同的 100GbE 網卡 QXG-100G2SF-BCM、QXG-100G2SF-E810。
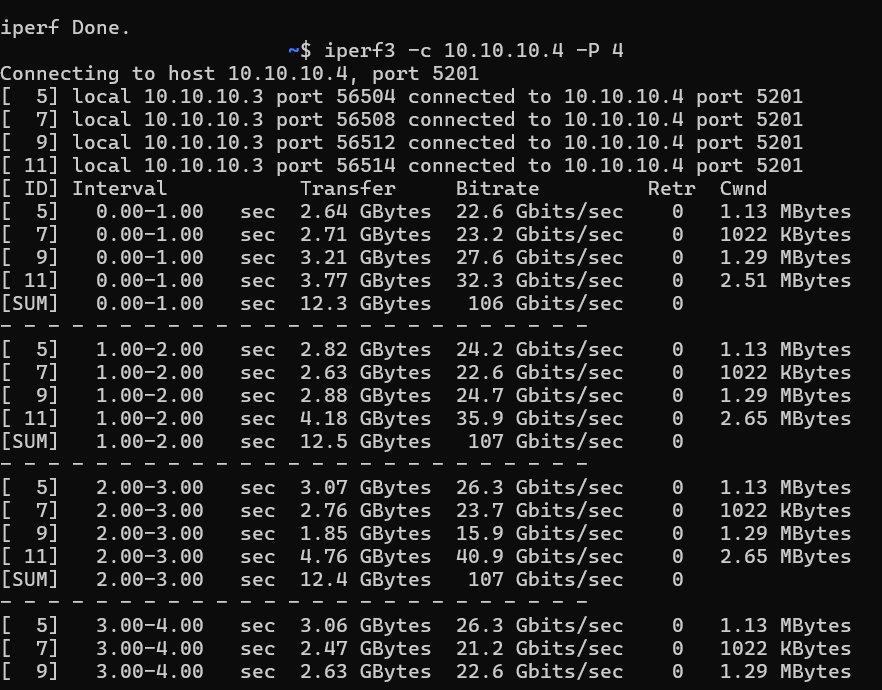
CyberQ 開啟 4 個平行連線(-P 4)向目標伺服器(10.10.10.4)發送流量,在未對 TCP Stack 與 MTU 進行調整的基礎 Docker 環境下,測得了穩定約 98 Gb/s 的總頻寬。
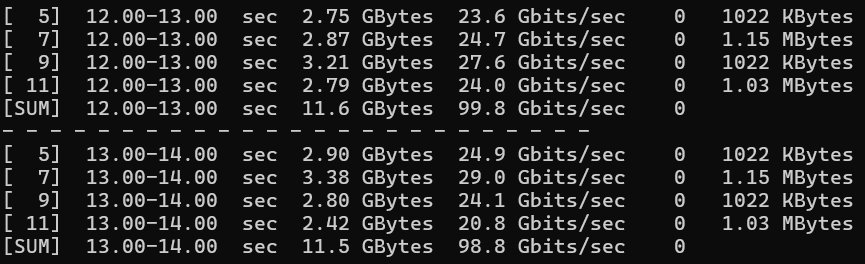
在容器化環境中,由於虛擬網路堆疊的轉換與 CPU 中斷處理的限制,單一 iPerf3 測試往往不一定能直接跑滿 100Gbps 的線速(Line Rate),不過如果在設定上有做調整,有些測試情況下會有更好的成績。
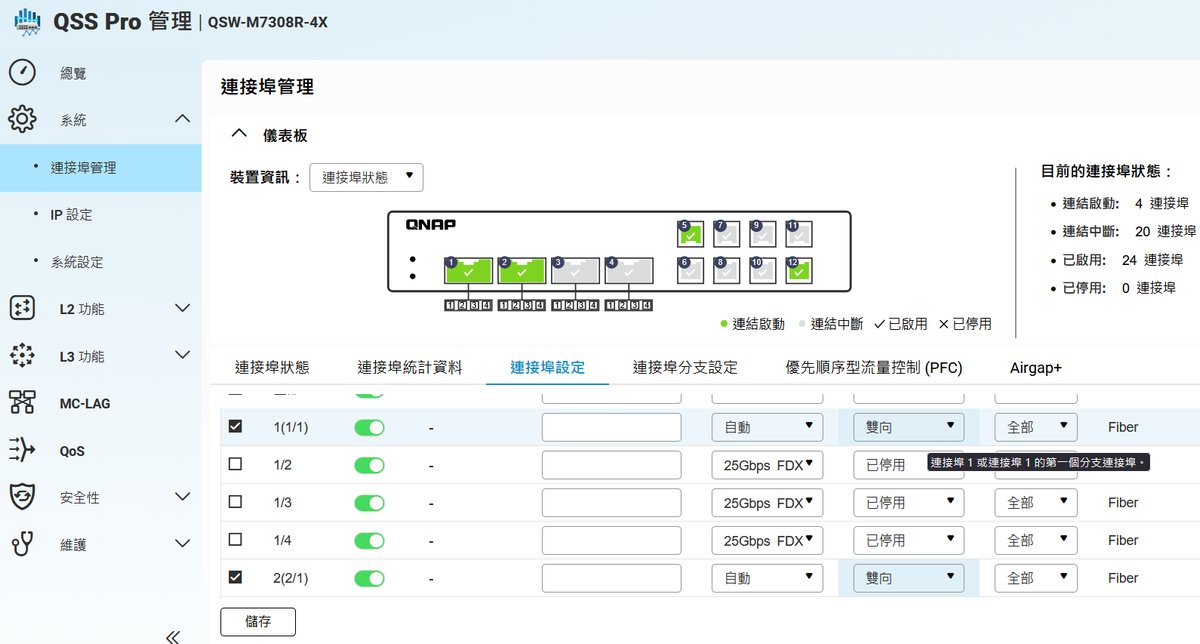
將發送資料端與接收端的 MTU 都調整為 9000,並設定 RX、TX on 為雙向,並確認 FEC 為 RS mode 後,跑出了下列的優秀成績,軟體端會顯示到 106 – 107 Gb/s 的數字。
直覺的系統與維護管理
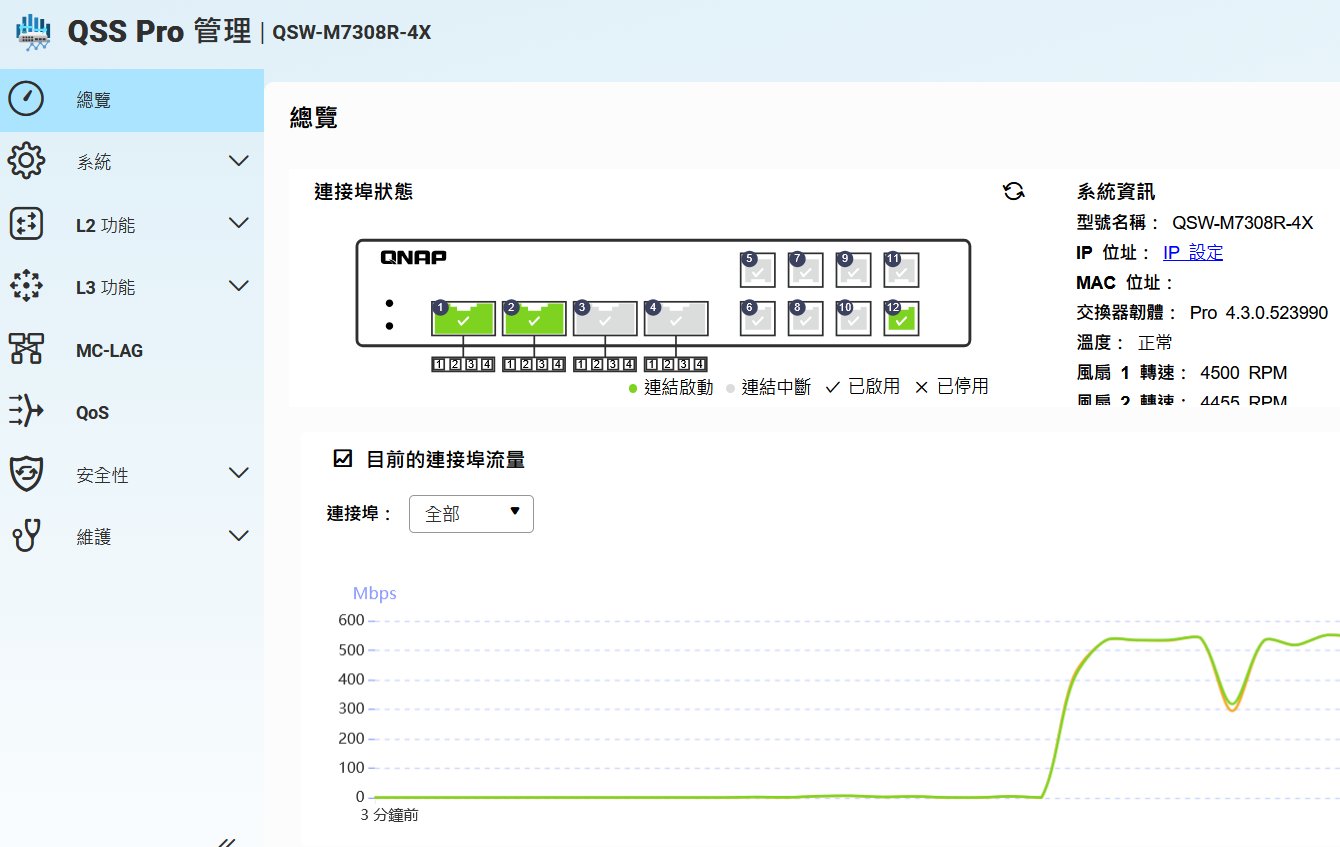
一套好的網管系統應該要在功能強大與操作直覺之間取得平衡。從系統總覽介面來看,QSS Pro 提供了清晰的設備拓樸狀態、即時流量圖表,以及風扇轉速(約 4500 RPM,確保高頻寬晶片的散熱)等系統健康資訊。
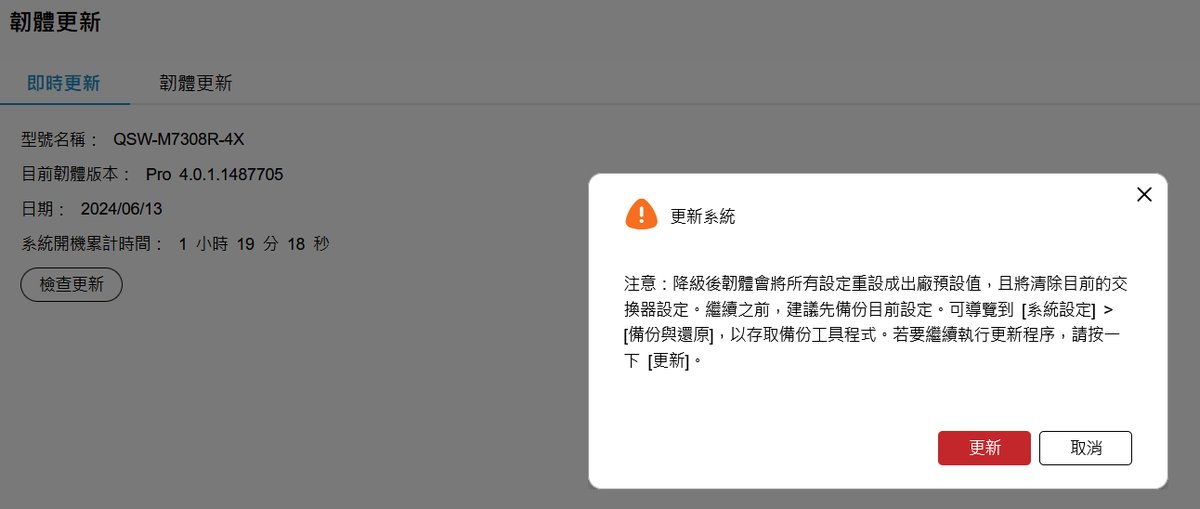
此外,在韌體更新機制上也有防呆設計(例如降級時的重設警告),確保管理者在維護具有複雜 L2/L3 設定的設備時,不會因為操作失誤而導致設定檔遺失。
L3 Lite 路由效能與網路架構隔離
這台交換器也升級了 QSS Pro 並支援 L3 Lite,它可以分擔核心路由器的 Inter-VLAN 路由壓力,可幫助我們規劃企業網路拓樸時更強化。
企業級架構的基石 MC-LAG 跨設備容錯
對於擔當骨幹任務的交換器而言,單點故障(Single Point of Failure)是無法容忍的。QSW-M7308R-4X 支援了 MC-LAG(跨設備連結彙總群組) 功能。

我們在 QSS Pro 的介面中可以設定系統,允許將多台交換器的第二層(L2)連線合併成單一邏輯連結。這意味著你可以將伺服器的兩張網卡分別接在兩台不同的 QSW-M7308R-4X 上,當其中一台交換器需要重啟更新韌體,或是實體線路發生意外時,流量會無縫切換,確保服務高可用性(High Availability),這對於維持業務連續性有相當幫助。
物理層的健康守護者 DDM 數位診斷監控
100G 光收發模組(Transceivers)在全速運作時會產生可觀的熱量,且對電壓與光學功率極為敏感。QSS Pro 內建的 DDM(數位診斷監控)儀表板提供了模組的即時遙測資料:
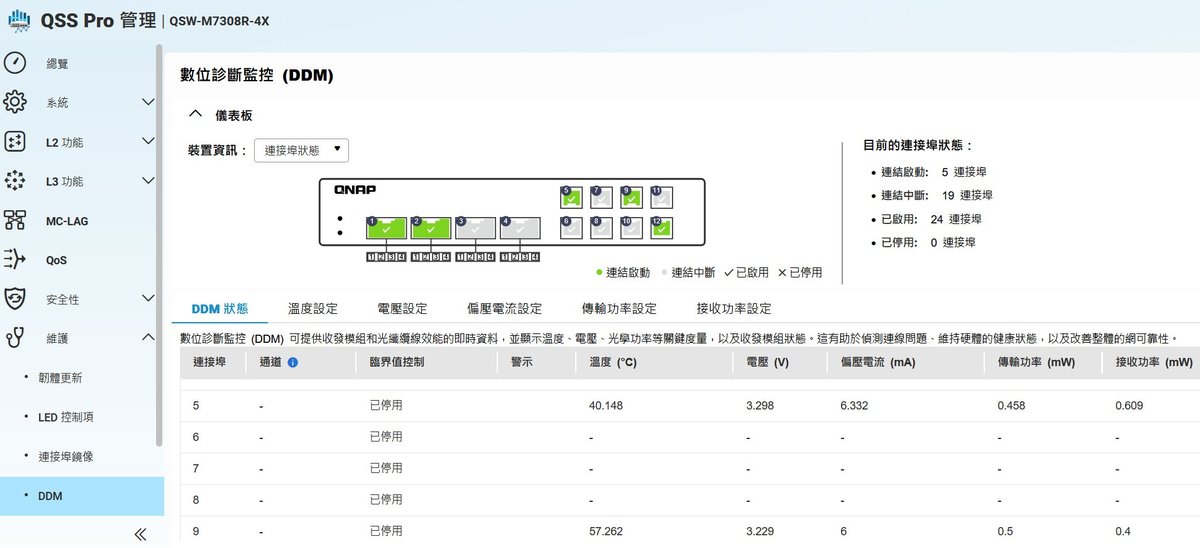
溫度(Temperature)介面顯示某模組運作於 57.2°C 或 36.4°C,協助管理者判斷機房或設備散熱是否正常。而電壓與偏壓電流(Voltage & Bias Current)可監控模組供電是否穩定,預先防範硬體老化導致的斷線。
傳輸/接收功率(Tx/Rx Power)的單位為 mW。光衰減是光纖網路常見的問題,透過監控接收功率,可以在光纖線材損耗過高導致掉包前,及早進行抽換。

不過本次測試我們主要使用的是 QSFP28 規格的 DAC 線,這種線材的溫度比較低,即便是不支援 DDM 的溫度顯示,也不影響它的穩定運作,在機房內的同機櫃或短距離機櫃的跨櫃仍可以使用,但超過 1.5公尺 範圍就改用光纖線和光纖模組了。
RDMA 與 RoCE v2 的核心優勢 Kernel Bypass
在現代乙太網路架構中,最主流的 RDMA 實作方式是 RoCE v2 (RDMA over Converged Ethernet)。它將 InfiniBand 的傳輸技術封裝在標準的 UDP/IP 封包中,我們能夠直接沿用 QSW-M7308R-4X 這種 100GbE 乙太網路交換器,而不需要建置昂貴的專屬 InfiniBand 網路。
RDMA 帶來了兩個決定性的優勢,分別是核心旁路 (Kernel Bypass),應用程式可以直接與網卡硬體溝通,完全跳過 Linux 核心的 TCP/IP 堆疊。以及 Zero-copy,讓資料直接從一台機器的應用程式記憶體,透過網卡傳輸到另一台機器的記憶體中,CPU 幾乎不參與搬運過程。這些技術搭配使用,使得延遲可以從微秒(Microsecond)級別大幅降至接近奈秒(Nanosecond),並在極低 CPU 使用率下跑滿 100Gbps 線速。
實踐 RoCE v2 的關鍵是無損網路 (Lossless Network)
與傳統 TCP 會自動重傳掉包不同,RoCE v2 對於網路封包遺失極度敏感。一旦發生掉包,RDMA 效能會大幅下跌。因此,必須在交換器端設定無損網路。在 QSS Pro 介面中,可以去設定優先順序型流量控制 (PFC, Priority-based Flow Control)。
同時還可以啟用 ECN (Explicit Congestion Notification),在 IP 標頭中標記壅塞狀態,讓端點在交換器真正開始丟包前,預先降低發送速率。
Docker 容器內的 RDMA 設定
在 Docker 中,不能只依賴 –network host。因為 RDMA 繞過了 Kernel,必須將宿主機的 RDMA 設備(Infiniband uverbs)直接映射進容器內。執行容器時,通常需要加入類似這樣的參數:–device=/dev/infiniband/uverbs0 –cap-add=IPC_LOCK
並且確保容器內的應用程式(例如自編譯的 MPI 程式或支援 RDMA 的 iPerf 工具如 ibv_rc_pingpong)具備相應的 OFED (OpenFabrics Enterprise Distribution) 驅動庫。
功能完整並兼顧效能與價格
CyberQ 認為,無論是為了應對 AI 算力所需的龐大資料吞吐,還是為了升級高效能的儲存網路架構,100GbE 網路已逐漸成為次世代 IT 基礎建設的標準。
QNAP QSW-M7308R-4X 不僅提供了硬體上的高頻寬與 RS-FEC 支援,其 QSS Pro 系統所帶來的 MC-LAG 容錯機制與 DDM 光學監控,更補足了企業在營運與維護上的需求,是一台非常適合進階用戶、影音工作室、AI 新創團隊及不同規模企業升級網路骨幹的實戰利器。