

來自歐洲法國的 Mistral AI 推出全新語音轉文字模型 Voxtral Transcribe 2,這項技術正以令人驚艷的精準度與反應速度,重新定義音訊資料的處理效能。
這款新一代語音模型家族包含了專為批次處理設計的 Voxtral Mini Transcribe V2,以及針對即時應用開發的 Voxtral Realtime。值得注意的是,其中 Voxtral Realtime 採用 Apache 2.0 授權協議開放模型權重,展現了 Mistral AI 持續深耕開放原始碼社群的決心。
低延遲與高精準度的完美平衡
Voxtral Realtime 是為了滿足對時間極度敏感的應用情境而生。與傳統將音訊切片處理的方式不同,該模型採用創新的串流架構,能夠在音訊輸入的同時進行轉換。其延遲時間可調整至 200 毫秒以下,這項特性能夠讓語音助理或即時客服系統的對話更貼近真人客服。
Photo Credit by Mistral AI
Voxtral Realtime 在追求速度的同時仍維持了極高的準確率。在 FLEURS 基準測試中,即使延遲設定在 480 毫秒,其錯誤率與其它離線模型相比僅有微小差異。此外,該模型具備 40 億參數規模,能有效率地在終端裝置上運作,確保資料處理的隱私與安全。
領先其他AI模型的成本效益與效能表現
Mistral AI 此次的技術規格的提升,相比於其它同類型產品也展現了優秀的市場競爭力。根據官方公佈的效能對比資料顯示,Voxtral Mini Transcribe V2 在成本與精準度之間取得了不錯的平衡。
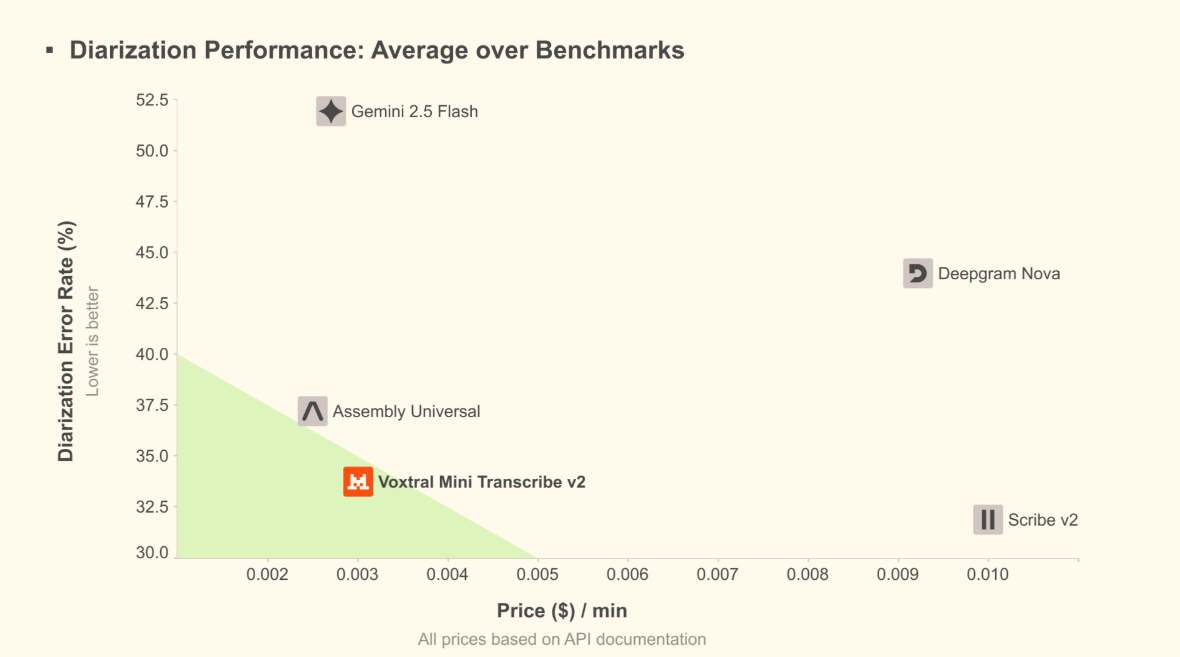
Figure Credit by Mistral AI
在針對辨識發言者的準確度(Diarization)測試中,Voxtral Mini Transcribe V2 的錯誤率明顯低於 Gemini 1.5 Flash 與 Assembly Universal。更關鍵的是,其 API 使用成本維持在每分鐘 0.003 美元的低水位,相較於報價較高的 Deepgram Nova 或 Scribe V2,提供了更具優勢的性價比選擇。
這項資料證實了該模型除了能夠處理複雜場景的語音外,更能協助有大規模資料轉譯需求的公司節省營運支出。
功能升級與多元場景應用
除了優異的性價比,Mistral 這次升級帶來了多項關鍵功能:
精準角色辨認:具備優異的分段辨者功能,能自動標註不同發言者並標記時間軸,非常適合會議紀錄與訪談分析。
語境偏好設定:使用者可提供最多 100 個專有名詞、技術術語或人名,引導模型進行更精確的拼寫。
多語系支持:原生支援包括繁體中文、英文、日文、韓文等 13 種語言,在非英語系的表現上尤其出色。
環境抗噪與長音訊處理:模型在吵雜環境中依然能穩定運作,且單次請求可處理長達 3 小時的錄音。
從企業內部的會議紀錄分析,到提供即時語音翻譯的虛擬助手,Voxtral Transcribe 2 的應用範圍相當廣泛。對於影音產業而言,低延遲的特性可用於生成直播節目的即時字幕。而對於法務或醫療等高度受規管的行業,甚至還支援了被公認為史上最嚴、隱私保護範圍最廣的歐盟一般資料保護規範 GDPR 與美國醫療保險流通與責任法案 HIPAA 的合規佈署方式,這算是不簡單的任務,要符合法遵的面面俱到可能是他們的優勢之一。
目前使用者已能在 Mistral Studio 的音訊實驗室中直接測試 Voxtral Transcribe 2 的效能,或透過 API 將這項強大的語音處理能力整合至自有的應用程式中。
CyberQ 認為 Mistral AI 此次的核心價值除了模型本身的高效能與高性價比之外,還能透過支援高度合規的佈署模式,打破法務與醫療等受到高度管制的領域採用 AI 的門檻。這種兼顧成本與隱私的技術架構,將成為企業推動數位轉型的關鍵動力。
首圖由 Nano Banana AI 生成









