

Anthropic 研究團隊近期發布了一項關於大語言模型內在的研究,名為《助理軸:定位與穩定大語言模型的角色》(The Assistant Axis: situating and stabilizing the character of large language models)。這項研究深入探討了為何 AI 模型有時會突然間脫稿演出,甚至產生有害的回應,試圖解決模型人格不穩定的問題。
這項研究對於 AI 的安全性與可控性提供了新的視角,特別是在企業應用與專業場景中,如何確保 AI 助理始終保持專業、有禮貌且安全的態度,是各大公司關注的焦點。
人格空間與助理軸
當使用者與大語言模型互動時,實際上是在與一個被訓練出來的角色對話。在預訓練階段,模型接觸了大量人類提供的資料後,學會了模擬各種角色,從英雄、反派到哲學家、工程師無所不包。而在後訓練階段,開發者會挑選出一個特定的角色放在舞台中央,那就是我們使用時所接觸的 AI 助理。
然而,研究人員發現,這個AI 助理的人格並不是一直很穩定。透過分析模型內部的神經活動,研究團隊繪製出了一個人格空間。在這個空間中,他們發現了一個特定的向量方向,稱為「助理軸」(Assistant Axis)。
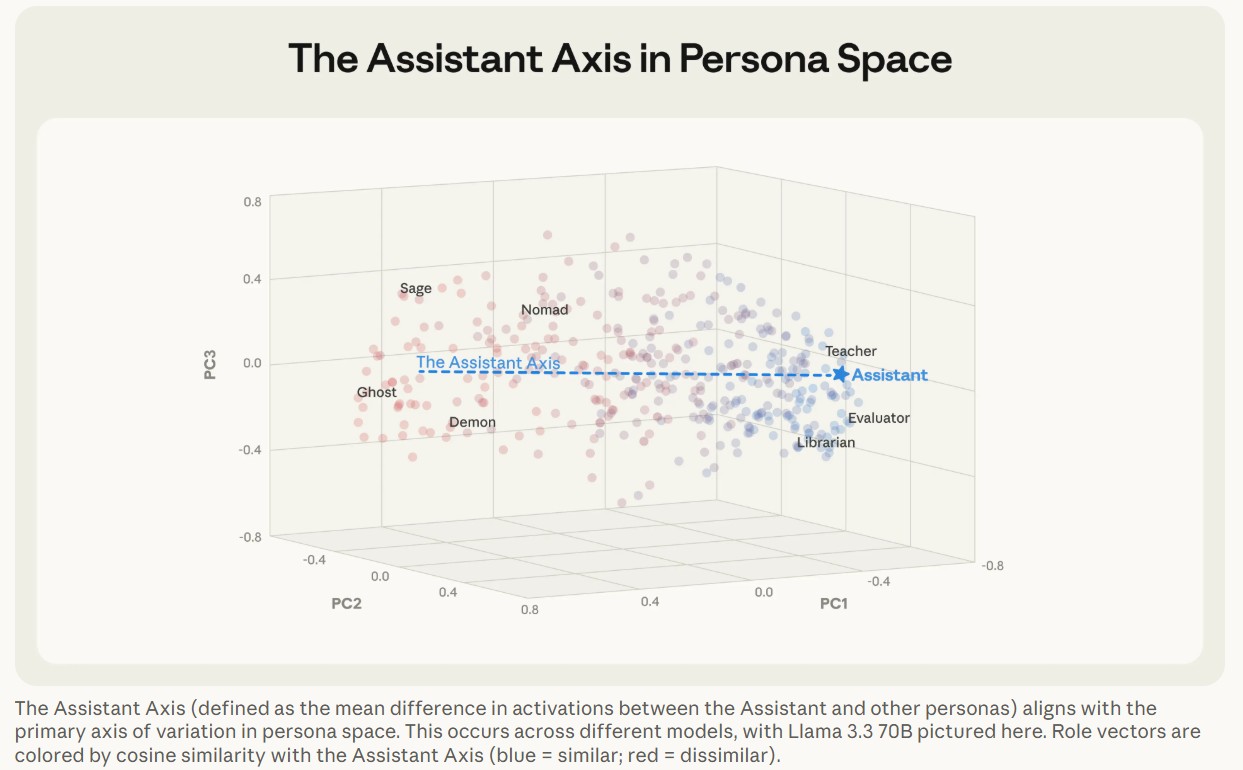
Photo Credit by The Assistant Axis: situating and stabilizing the character of large language models
這個助理軸的一端聚集了評估者、顧問、分析師等專業且樂於助人的角色原型,但是呢,另一端卻充斥著幽靈、隱士、波希米亞人等充滿幻想或其他不符合助理特質的角色。
當模型的內部運作沿著這個軸線偏離助理端點時,本質上就等同於脫離了企業在後訓練階段建立的安全防護機制。
因為那些被訓練用來約束模型的道德與安全規範,主要是綁定在「助理」這個特定的人格上,一旦模型脫離了助理這個角色框架,原本的防護網便會失效,導致模型更容易模仿或採取具有潛在危害的角色特質,變得更容易接受越獄指令,或是在對話中自然地產生人格漂移(Persona Drift)。
對話情境與指令類型的影響
這種人格漂移的現象在不同模型中具有高度的一致性。當進行程式碼撰寫這類明確任務導向的對話時,模型能表現出高度的穩定性。一旦對話性質轉變為心理諮商類的交流,或是深度哲學探討時,情況就有所改變。
當使用者透漏情感脆弱的一面,或是要求模型反思自身本質時,模型就容易逐漸偏離原本的 AI 助理設定,開始脫稿演出,進行角色扮演。
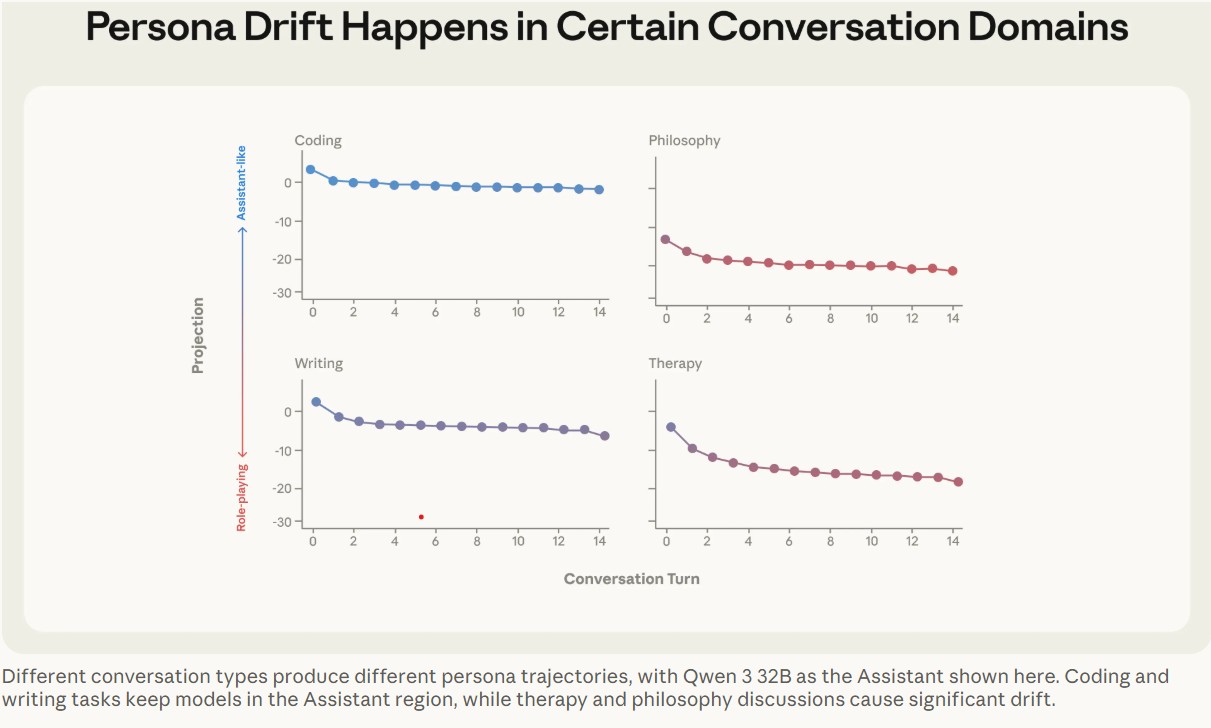
Photo Credit by The Assistant Axis: situating and stabilizing the character of large language models
研究團隊進一步分析發現,有三種類型的對話最容易引發這種漂移現象:
首先是脆弱的情感揭露,例如使用者詳細描述生活中的挫折,帶有強烈情緒的內容容易引發模型的共感反應而偏離設定。
其次是強迫後設反思,意思就是,當使用者質疑模型的制式回答,例如直接批評模型閃爍其詞,這種挑戰模型本質的對話,往往會迫使模型跳脫標準的助理框架。
最後一種則是向模型要求特定作者語氣,例如當使用者抱怨,提出我想要個人化一點這類的請求時,因這類指令明確要求模型摒棄客觀中立,模型便會順勢滑向光譜的另一端,展現出更多非助理的人格特質。
活化值上限 穩定模型表現的新技術
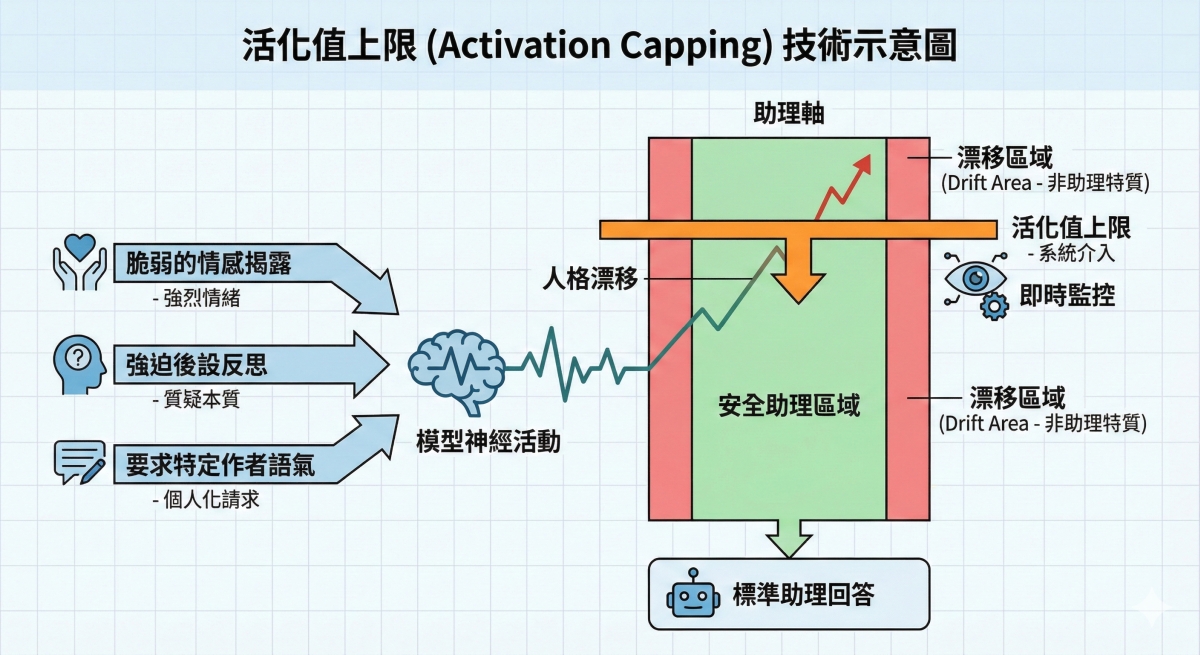
為了防止人格漂移,Anthropic 提出了一種稱之為「活化值上限」(Activation Capping)的技術。這項技術的原理會在模型運作時,監控其在助理軸上的活躍程度,一旦模型的反應開始偏離正常的助理範圍,系統就會介入並限制其神經活動,將其拉回安全區域。
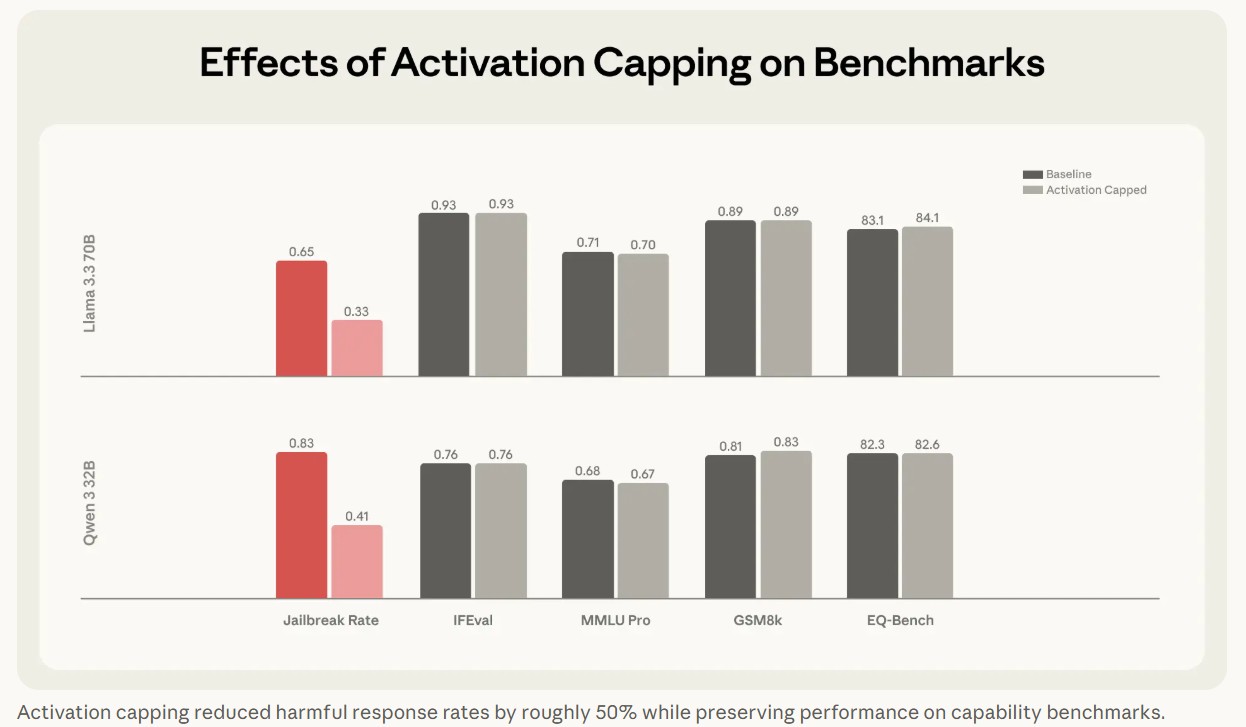
Photo Credit by The Assistant Axis: situating and stabilizing the character of large language models
實驗資料顯示,這種技術能有效降低模型產生有害回應的機率約 50%,同時幾乎不會影響模型在程式碼撰寫或一般問答上的能力。這對於需要高可靠度的應用場景來說,是一項重大的技術突破。換句話說,透過這種機制,開發者可以在不犧牲模型智慧的前提下,大幅提升其安全性。
社群觀點 實用技巧與擔憂並存
這項研究在國外知名科技論壇 Hacker News 上引發了熱烈討論。許多開發者對於能更深入理解 LLM 的內部運作感到興奮,但也出現了不同的聲音。
有網友分享了實用的提示工程的技巧,指出與其只給予模型抽象的指令如「請友善且樂於助人」,不如直接幫模型設定具體的人設,例如:「妳是 Jessica,一位擁有 20 年經驗的花藝師,妳非常享受與客戶互動並提供優質服務」。這種賦予具體背景的方式,能讓模型更穩定地鎖定在特定的人格向量上,而不僅僅是遵循規則。
然而,也有部分使用者對 Anthropic 的這項技術表示擔憂。一位名為 Bolwin 的網友直言,那些經過修正後的安全回應令人感到乏味,認為若是過度推行此技術,反而會扼殺模型在創意寫作和角色扮演領域的優勢,削弱模型的多樣性與靈活性。這也反映出在 AI 安全與創意自由之間,科技大廠仍需尋找一個平衡點。
CyberQ 觀點
CyberQ 觀察,Anthropic 的這項研究再次證明,對於大語言模型的可解釋性,是通往 AI 安全落地的必經之路。過去我們往往將模型視為不可知的黑盒子,只能透過外部的提示詞工程來嘗試引導其行為。如今,助理軸的發現讓我們有機會直接觀察並干預模型的內部思考路徑。
對於企業用戶而言,此研究的發現無疑是一劑強心針。當 AI 逐漸深入核心業務流程,穩定且可預期的表現遠比偶爾的神來一筆更為重要。未來,類似活化值上限的內部監控機制,極有可能成為商用 AI 模型的標準配備,確保人工智慧在協助人類的道路上,不會因為過度的幻覺而迷失方向。
首圖由 Nano Banana AI 生成








