

OpenAI 日前正式釋出了最新的影像生成模型 GPT-Image 1.5,並同步更新了 ChatGPT 的影像編輯介面。這次更新不僅僅是「畫質變好」這麼簡單,OpenAI 顯然聽見了用戶長久以來對於「精準控圖」的渴望,試圖透過更強的指令遵循能力與編輯工具,縮短與競爭對手 Google 的差距。
CyberQ 也針對 GPT-Image 1.5 與 Google Nano Banana Pro 分別進行了實測,

提詞相同的情況下,上面這張是 GPT-Image 1.5 產生的圖片。

提詞相同的情況下,上面這張是 Google Nano Banana 產生的圖片。
速度更快,終於能「聽懂人話」修圖了
這次更新主要聚焦在三個面向,分別是速度、可控性與文字渲染。
(Figure Credit: OpenAI website)
4 倍生成速度:根據官方資料與實測,GPT-Image 1.5 的生成速度比前代快了約 4 倍。這對於需要大量抽卡、試錯(Trial and Error)的創作者來說,大幅降低了時間成本。
精準的局部編輯(In-painting):過去我們常抱怨 ChatGPT「聽不懂」修改指令(例如:「把貓換成狗」,它通常會重畫一張全新的圖)。新版引入了更直觀的編輯工具,你可以直接選取圖片區域,透過對話要求「增加物件」、「改變風格」或「調整特定服裝」,而不會破壞畫面的其餘部分。
專屬的「My Images」空間:OpenAI 終於在側邊欄加入了一個獨立的影像管理介面,讓你的創作不再散落在茫茫對話紀錄中,這一點對我們日常在這個平台的工作流程管理是不錯的改善。
改圖風潮再現
新功能上線不到 24 小時,社群媒體 X(前 Twitter)與 Reddit 已經被大量測試圖洗版。
許多人測試讓 AI 將日常照片轉換為不同作品的風格與發揮更多創意,用戶反應這次的模型在捕捉「日式手繪質感」與「光影氛圍」上進步神速,不再像以前那樣有濃重的「AI 塑膠感」。
物理常識的修正:社群論壇 Hacker News 上有開發者指出,新模型終於修復了一些經典的物理錯誤(例如玻璃杯中的液體折射),這顯示模型的底層邏輯有相當的提升。
褒貶不一的聲音:雖然編輯功能大受好評,但仍有專業用戶指出,在處理極其複雜的提示詞時,GPT-Image 1.5 偶爾還是會「漏單」(忽略部分指令),且在人體手指與肢體末端的處理上,偶爾仍會出現令人啼笑皆非的失誤。
GPT-Image 1.5 vs. Google Nano Banana Pro
對於專業用戶來說,最關心的莫過於它打得贏 Google 目前最強的 Nano Banana Pro 嗎?
CyberQ 觀察,根據目前的評測資料與開發者反應,兩者各有千秋,但定位截然不同:
GPT-Image 1.5 是一個「更好聊」的創意夥伴,它的編輯功能讓普通人也能輕鬆修改圖片,非常適合社群素材的快速產出。然而,如果你需要的是接近專業等級的精準輸出(例如海報設計、連環畫創作),Google Nano Banana Pro 以其對繁體中文的支援度與強大的控圖能力,目前在專業領域仍略勝一籌。
實際測試會發現,GPT-Image 1.5 的文生圖能力儘管接近 Google Nano Banana Pro ,可是呢,它在處理一些畫面細節和理解力線然仍是落後 Google的,特別是處理手寫筆記、某些人物動作時,GPT-Image 1.5 的圖片看起來可能給過,可是內容錯誤率頗高。畫面細節的部分,也還不如 Google Gemini 給的精緻。
CyberQ 建議,日常玩梗、發文用 ChatGPT;接案、做正經設計用 Nano Banana Pro。
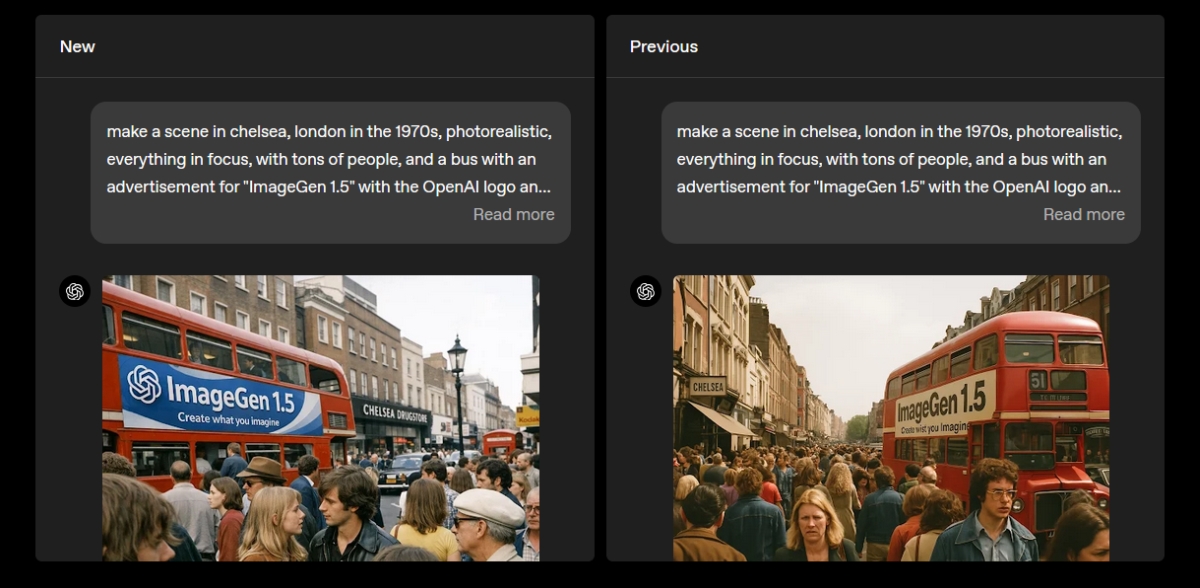
以下是另外一組採用同樣提詞,在 GPT-Image 1.5 與 Google Nano Banana Pro 、ComfyUI + Z-Image Turbo 所做的實測對照,可以看出很明顯的差異和風格的不同,Google 和 Z-Image 的風格是類似的,對包括中文等多國文字在內的理解能力也強:

上圖是 GPT-Image 1.5 所產生的圖片

上圖是 Google Nano Banana Pro 所產生的圖片

上圖是 ComfyUI 搭配 Z-Image Turbo 所產生的圖片
首圖由 Nano Banana AI 生成,配圖由 ChatGPT、ComfyUI 搭配 Z-Image Turbo 生成







