在 AI 生成圖像領域,工具的迭代速度往往決定了創作者的上限。開源圖像生成介面的霸主 ComfyUI 近期釋出了 v0.3.76 版本,針對記憶體管理與運算效率進行了底層級別的最佳化。與此同時,新熱門 AI 工作站硬體 NVIDIA DGX Spark 也逐漸進入開發者視野。
CyberQ 這次測試 ComfyUI 0.3.76 特別採用新的硬體來實際比較看看效果,我們找來了目前消費級市場的中階 GPU 產品 NVIDIA RTX 5060 Ti (16GB VRAM),與搭載 128GB 統一記憶體的 NVIDIA DGX Spark 進行同場競技,去執行中國阿里巴巴集團旗下通義實驗室最新發布的 Z-Image Turbo 模型,這個模型目前的討論程度,和之前同樣是阿里巴巴旗下通義實驗室發布的 Qwen Image 剛出來的時候一樣火熱,更重要的是,它能不受限制地生成 NSFW 圖像,也引起市場關注。
ComfyUI v0.3.76 新版讓使用者體驗(UX)和底層效能的重大提升。
許多使用者更新到 v0.3.76 後的第一反應可能是使用了他們新版測試中的 Node 2.0 ,會發現介面清爽許多,工作流的使用雖然一開始不太習慣,但仍舊是好用的。同時,魔鬼也藏在細節裡,根據官方 Changelog 與我們在程式方面做的檢視,這次更新主要集中在記憶體最佳化 (Memory Optimization) 與執行穩定性:
Pinned Memory(鎖頁記憶體)預設開啟:針對 NVIDIA 與 AMD GPU,新版預設啟用了 Pinned Memory 技術。這意味著 CPU 與 GPU 之間的資料傳輸效率大幅提升。
VRAM 佔用最佳化:針對 Flux 與 LTXV 等大模型進行了核心程式碼瘦身,這對於顯示卡記憶體 VRAM 吃緊的用戶相當重要。
更聰明的卸載邏輯:當 VRAM 使用量大增時,系統能更智慧地釋放閒置權重,減少程式與模型崩潰的機率。
實測:RTX 5060 Ti vs. DGX Spark
為了驗證效能,我們採用了ComfyUI 官方提供的 Z-Image Turbo 標準預設工作流(Default Workflow)。
設定:解析度 1024 x 1024,採樣步數 9 步(Steps)。
我們分別在兩台機器上執行同一份預設的 JSON 工作流,結果如下:
RTX 5060 Ti (16GB VRAM)
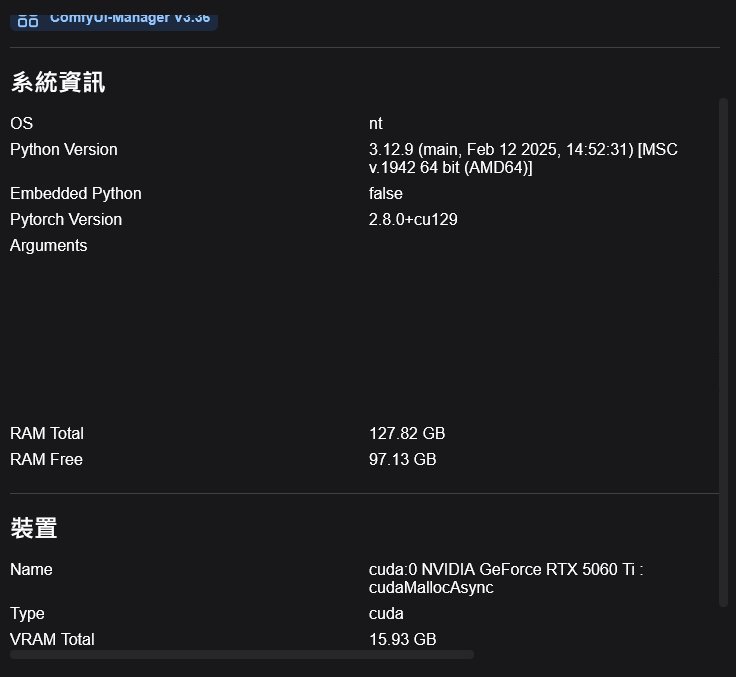
平均單張出圖時間:約 2X 秒 / 張
雖然 RTX 5060 Ti 配備了 16GB VRAM,在過往若執行較大參數的模型,若未進行極致的量化(Quantization)或分層卸載,模型權重加上中間運算產生的 Tensor 很容易突破 16GB 的物理極限。但 Z-Image Turbo 模型的大小是剛剛好的,對較少 VRAM 的顯示卡也是友善,因此出圖表現的時間和品質都還可以。
NVIDIA DGX Spark (128GB Unified Memory) , 12 秒的生產力甜蜜點
平均單張出圖時間:穩定約 11 秒到 12 秒 / 張
DGX Spark 搭載的 Grace Blackwell 架構擁有 128GB 統一記憶體。這讓它能輕鬆將 Z-Image Turbo 完整載入,甚至還有餘裕同時跑其他 LLM。
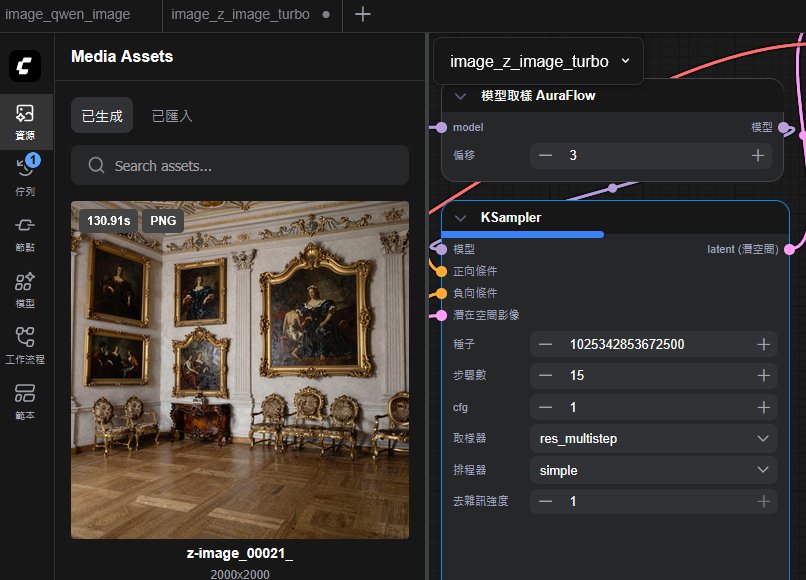
如果看圖片的大小與效率,測試中的同一張圖,5060Ti 16GB 在 1024*1024 的時間是22.3秒,在 DGX Spark 則是 10.9秒,如果是解析度到 2000*2000 ,5060 Ti 16GB 要 130.9 秒,而 DGX Spark 則是 88 秒。
對於商業工作室而言,大量圖片生成與高解析度的情況下,當客戶要求 2K 以上精細海報底圖時,DGX Spark 會比消費級顯卡實用,因為實際上的環境會並用多種工作流,出圖出影片,因此 DGX Spark 也是工作室的一種可考慮選項。
三、 為什麼是 Z-Image Turbo?
Z-Image Turbo 是近期 AI 圖像社群最熱議的焦點,在 ComfyUI 社群中掀起熱潮,主要因為驚人的生成速度與較低的 VRAM 需求,其最大的優點是圖像精緻且能正確理解 Prompt 並輸出,同時減少變形、手壞掉、透視角度錯誤等問題,另為,其殺手級應用是可用中文辭彙來下 Prompt 提詞,渲染效果也不錯。 在我們的實測中,輸入提示詞「一個寫著 CyberQ 資安 & AI 的霓虹招牌」,它能精準生成繁體中文字,且字體結構正確,完美融合於 Cyberpunk 背景中。這點目前連 Flux 系列模型或 SD 系列模型都難以望其項背。配合 DGX Spark 的 12 秒生成速度,這套組合非常適合需要快速迭代素材的設計師與廣告工作人員。
CyberQ 實測給予 Z-Image Turbo 極高肯定,但對其 LoRA 訓練功能則抱持謹慎態度。
1、性能與速度之外還有 NSFW
極速生成: 實測顯示,Z-Image Turbo 在標準解析度 (1024×1024) 下的生成速度極快,甚至有使用者回報在 6-12GB VRAM 的 GPU 上能達到令人滿意的流暢度。許多評論指出,它在「快速疊代 (Rapid Iteration)」方面表現出色,適合需要大量嘗試提示詞的創作者。
低 VRAM 最佳化: 該模型針對效率進行了高度最佳化,即使在較少 VRAM 的顯示卡也能順利生成高品質、照片級真實感(Photorealistic)的圖像。
模型特性: Z-Image Turbo 模型以其「未審查 (uncensored)」的特性和雙語(Bilingual Text)支援受到部分使用者關注,尤其適合需要探索創意邊界的用戶,所以你要產生 NSFW 的圖片在這個模型是直接可以生產而沒有限制的,不論是視覺與指定動作都能順利完成,適合給需要自產精神糧食的用戶們。

上圖為 NSFW 的示範,你可以指定人物、服裝、場景、動作與執行細節,嘗試不同分鏡來達成用戶想要的效果,可無限制地重複抽卡調整和運用。

動畫或漫畫風格同樣是可以的,對於很多人來說,創作文學作品和設定好配圖和配菜,想像一下霸道總裁或自己穿越到古代宮廷遇見男神太子或奇幻世界惡役千金的戀愛情境也有機會實現。
再來一個 Z-Image Turbo 在文字顯示上的小問題,是繁體中文在圖片上的顯示雖然能夠成功支援,但成熟度沒有簡體中文字和英文字般完美,反覆抽卡測試可能很費使用者的時間。
2、LoRA 訓練與潛在限制
原生 LoRA 訓練器強化:ComfyUI 原生 LoRA 訓練器現在支援多解析度訓練 (Multi-resolution),這對於圖像品質的提升算是重要。支援 Z-Image LoRA 訓練格式的功能可說和是時下熱門的 Z-Image Turbo 模型需要的,但因為官方還沒有釋出完整的基礎模型,目前有的人訓練這款模型的 LoRa ,是透過其他方式完成的。
CyberQ 觀察,由於 Z-Image Turbo 是一個「蒸餾模型 (Distilled Model) / Turbo 變體」,它針對快速推論 (Inference) 進行了最佳化,可是其底層架構在面對 LoRA 微調 (Fine-tuning) 時不如基礎模型 (Base Model) 穩定,容易出現過度擬合 (Overfit)或蒸餾崩潰的現象。
現階段社群中對 Z-Image Turbo 部分的評論也在於 LoRA 訓練的支援情形,有人認為初期的訓練效果仍不佳,部分使用者測試在 Z-Image Turbo 上進行角色 LoRA 訓練,發現角色相似度還不夠好,即使提高訓練步驟也無明顯改善。
CyberQ 建議,對於需要精準控制的 LoRA 訓練,使用者應暫時觀望或等待官方釋出 Z-Image 的基礎模型 (Base Weights),或改用其他成熟模型(如 Qwen-Image)進行訓練。不過,也有使用者回報概念型 LoRA (Concept LoRA) 表現尚可。
目前熱門以 Z-Image Turbo 做的社群模型有造相、Z-Image Turbo – Quantized for low VRAM (給更少記憶體的顯示卡用)等,可以下載來試試看效果。
ComfyUI v0.3.76 及相關未來發展
ComfyUI v0.3.76 這次的前端介面與使用者體驗 (UX) 不錯,特別是 Node 2.0 公測版和新前端頁面普遍獲得好評。從傳統 JavaScript 遷移到 TypeScript/Vue 的現代化新前端我們實測是喜歡的,這樣一來功能可以更豐富,且更易於擴展,許多用戶也期待它能解決舊介面中長期存在的 UX 問題。
至於線性模式測試版也極具潛力, 針對不習慣複雜節點連線圖(Spaghetti Monster)的使用者,線性模式被視為一個福音。它有助於將複雜的 ComfyUI 工作流轉化為類似 A1111 或 InvokeAI 的簡潔、循序漸進的流程,降低新手門檻。
子圖改進也能夠提升大型工作流的效率,比方說 Subgraphs(子圖)作為 ComfyUI 封裝複雜流程的關鍵,其改進受到重度用戶歡迎,有助於創建更整潔、更容易除錯的 AIO(All-in-One)工作流。
新增工作流進度面板是讓使用者能清楚追蹤冗長生成過程的進度,這是基礎但重要的 QoL 提升。
另外,左邊頁面新增的資產側邊欄 (Asset Sidebar) 和社群中已經有類似的第三方 SideBar 外掛程式 (如 ComfyUI-N-Sidebar) 相比,獲得高度讚揚。官方原生側邊欄(或類似功能)的加入,對於管理大量 LoRA、模型、或自定義模板而言,是不錯效率提升。
另一個值得關注的典試,預設在 Nvidia 顯示卡、GPU 上啟用非同步解除安裝 (Async Offload) ,這可說是關鍵效能的改善,這個功能允許在 GPU 運算時,同時將不再需要的模型權重搬運到系統記憶體,大幅緩解 VRAM 壓力,也有報告提到 AMD 顯卡似乎也從 Pinned Memory 相關最佳化中受益。
這次雖然新版增加支援了 Z-image LoRA 格式,提供了 Z-Image 的 LoRA 讀取節點。但儘管如前所述,訓練仍然面臨挑戰,但這為社群測試和使用預訓練的 Z-Image LoRA 提供了基礎。
支援視訊微型 VAE (Video Micro VAE) 預示著 ComfyUI 在影片生成方面將有更多底層加速,這與 Veo3/Kling 等影片模型生態的整合趨勢一致。
最後就是新的3D 節點支援全景圖像,換言之,ComfyUI 正在也讓 3D 內容生成和虛擬實境 (VR/AR) 領域可在這個生態系中實現更好的工作流,畢竟全景圖支援是 3D 內容輸出的重要基礎。
而 Veo3/Kling First-Last-Frame 節點的重大整合,對這種錨定影片關鍵畫面的技術是很需要的,現在 ComfyUI 納入了 Veo3(Google DeepMind)和 Kling 等頂級影片模型的 First-Last-Frame 節點,代表 ComfyUI 具續強化它在先進 AIGC 模型生態的中央樞紐角色定位,帶給我們精準、高品質的影片接續與控制能力。
CyberQ 認為,ComfyUI v0.3.76 透過底層記憶體管理(如非同步解除安裝)和前端體驗改進,大幅最佳化了消費級顯卡的使用體驗,而 Z-Image Turbo 則是以「速度」和「低 VRAM」優勢確立了其在快速生成領域的地位,但針對專業級的 LoRA 訓練,可以等待 Z-Image 基礎模型的釋出。它和 ComfyUI 相輔相成,很值得期待後續的發展呢。
相關網站 :
Tongyi-MAI / Z-Image-Turbo ,通義實驗室 Z-Image-Turbo 在 HuggingFace 上的專頁
HuggingFace Z-Image Turbo 線上測試專頁
首圖為 Google Gemini AI 生成