在 AI 大型語言模型(LLM)的軍備競賽中,「參數量」與「跑分」早已不是唯一指標,有另一個更直觀、卻也更具爭議的戰場,那就是我們熟悉的智商(IQ)測試,這些 AI 模型到底能跑多少分數呢?
Gemini 3 Pro 已可考進門薩
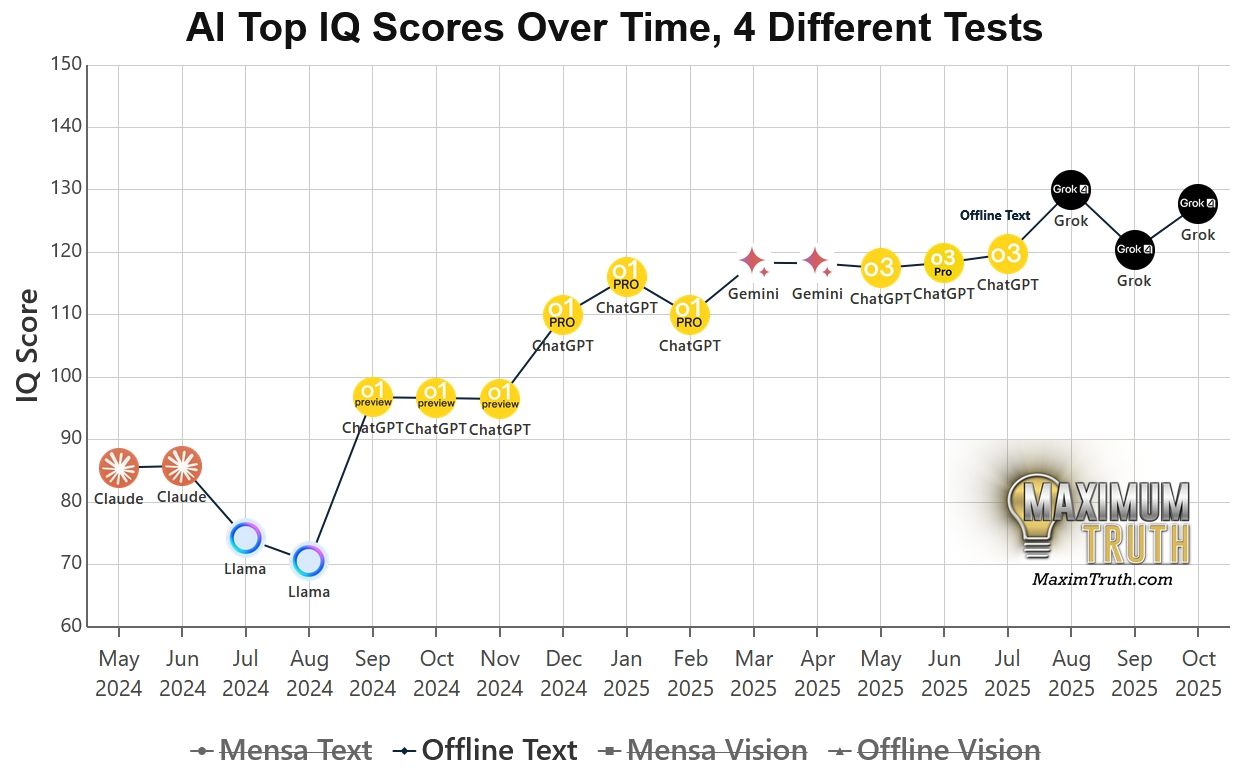
這幾天,由 Maxim Lott 維護的 TrackingAI.org 更新了最新的 AI IQ 排行榜,結果在 Reddit 和 X(前 Twitter)上引發了許多討論。為什麼?因為這次的測試打開了「資料污染(Data Contamination)」的問題面,讓我們看見了誰是真材實料的「資優生」,誰又是靠「刷考古題」拿高分的「填鴨式選手」。
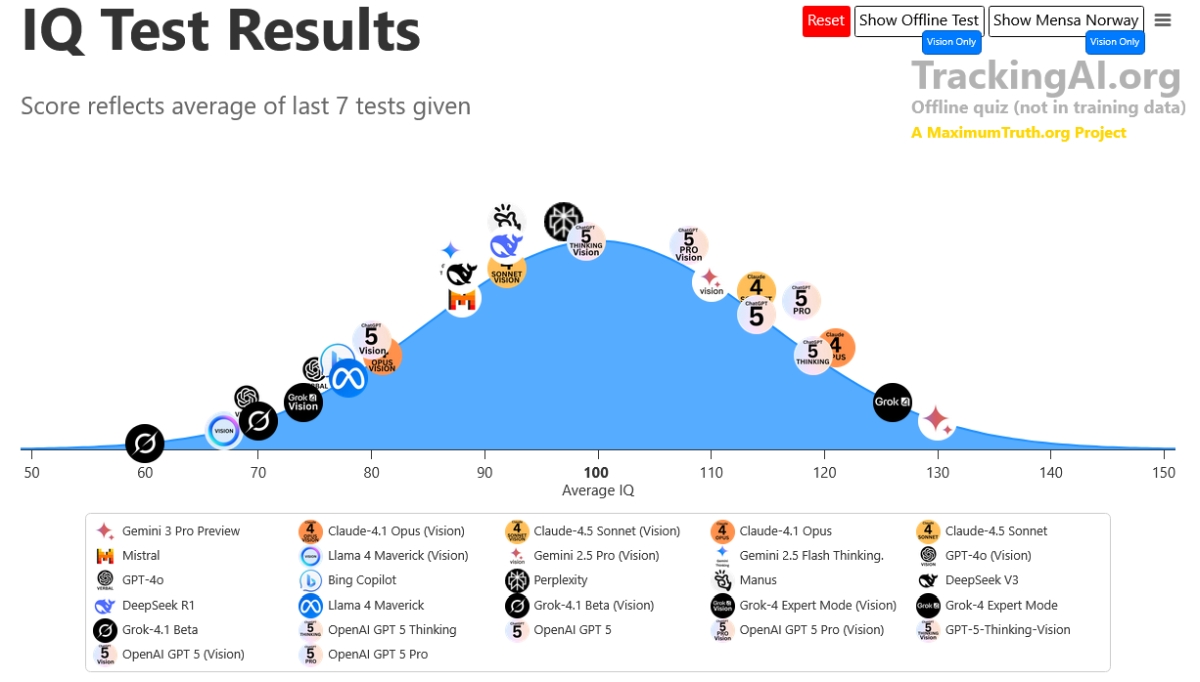
整體來說,以該網站做的綜合 index 呈現出的平均 IQ 分布來看,之前早期大部分 AI 的 IQ 都落在平均 100 以下,但新推出的 GPT-5 Pro、Grok 4、Gemini 3 Pro ,IQ 都已經來到 120 以上的區間,其中 Gemini 3 Pro 的 IQ 130,Grok 4 則是 IQ 126。
Gemini 3 Pro 已經是能考進高智商學會門薩 (Mensa)的成績,門薩的入門成績標準為智商分數需在測試拿到全球人口的前 2%,通常相當於標準差為 15 的智商測試分數達到 130 分或以上。
馬斯克在 x 的最新貼文對自家 Grok-4 拿到智商 126 的分數,也說 Not bad for now :
我們真實人類智商的話,IQ 的平均值是 100,有不少人的分數落在 90 到 110 之間,是一般的智力水準。而 IQ 分數的分野,在 130 分以上為非常優異,120-129 分為優異。
因此,「IQ 到底有多少 ? 」,這取決於個人的實際測試結果,而 100 是平均值,高於 110 就還不錯,但一直看考題刷題的人,是可以刻意去拿到好成績的。
不同考卷呈現的真相
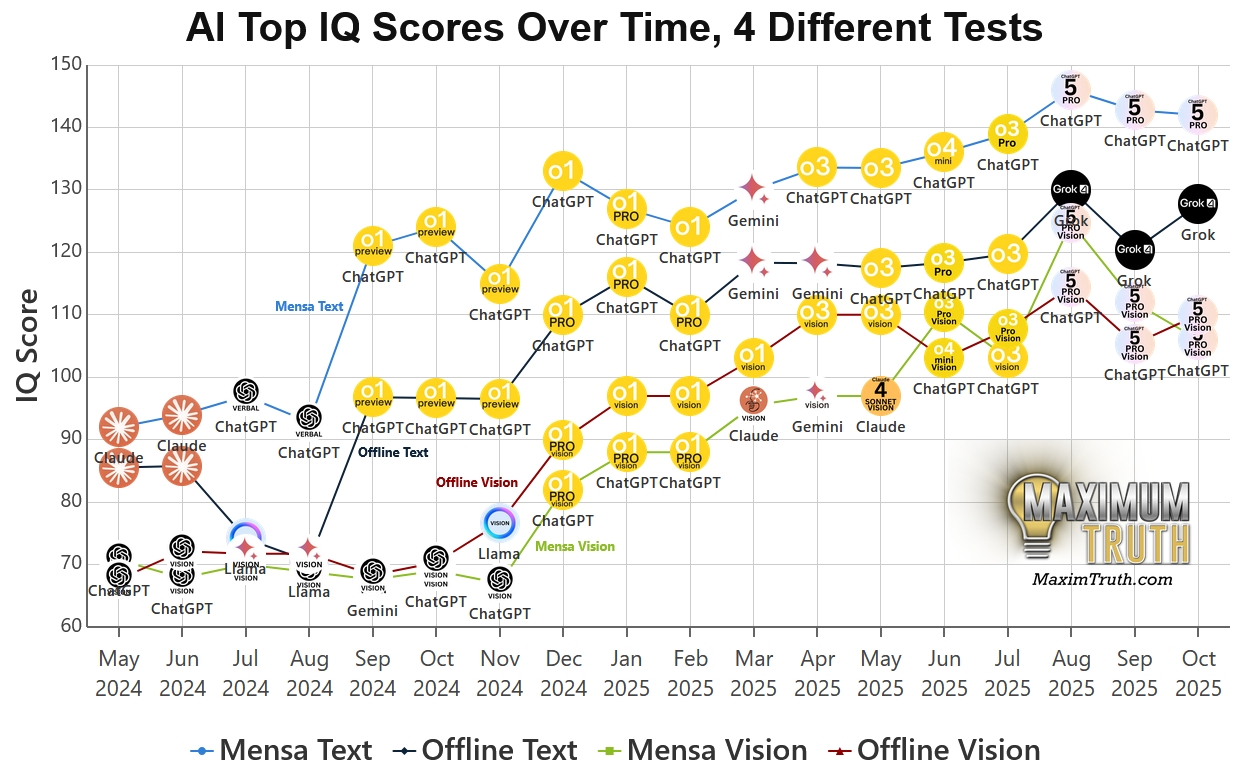
TrackingAI 的最大特色在於它提供了截然不同的測試標準,以公開版和離線版來說是這樣:
Mensa Norway(挪威門薩測試):這是一份公開在網路上的標準智力測驗。
Offline Test(離線測試):這是一份由門薩會員設計、從未在網路上公開的全新題目。
這些考卷的成績落差,正是精彩之處。
Gemini 3 Pro 的逆襲與 GPT-5 的問題
根據 2025 年 11 月的最新資料,Google 的 Gemini 3 Pro 在這場對決中表現超越現有所有 AI 模型。
真正的推理王? 在最關鍵的「離線測試」中,Gemini 3 Pro 拿下了 130 的高分。這是一個里程碑式的數字,意味著它在面對完全未知的邏輯難題時,已經達到了人類「資優(Gifted)」的門檻,甚至超越了 98% 的人類受測者。
刷題疑雲: 相比之下,榜單上部分模型出現了令人尷尬的分數落差,比方說著名的 GPT-5 Pro ,它在公開的 Mensa 測試中狂飆到 148 分(接近天才級別),但在沒見過題目的「離線測試」中卻回落至 116 分。
這種高達 30 分以上的落差,被社群戲稱為「背答案被抓包」。這證實了我們在業界長久以來的擔憂,許多模型之所以表現優異,是因為它們的訓練資料裡早就包含了這些公開試題的答案。
TrackingAI.org 之所以具有指標性,正是因為它不只給出一個籠統的分數,而是透過這四個維度的交叉比對,精準地拆解出 AI 模型的「真實智力」與「視覺能力」。
簡單來說,這四種曲線是基於「題目來源(是否公開)」與「輸入方式(看圖還是看文字)」所組成的矩陣。
我們可以將這四種曲線理解為 AI 的四場不同考試:
1、Mensa Norway (Image) ,考驗「視覺+記憶」的公開考卷
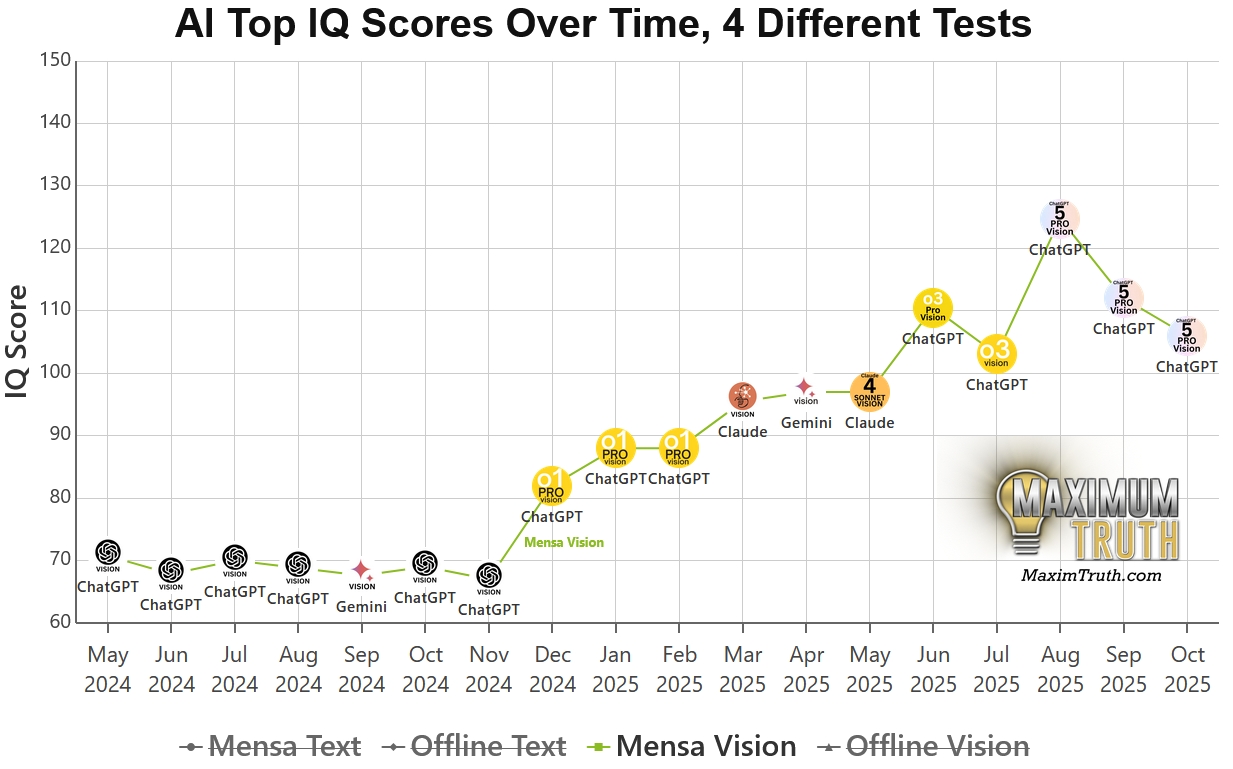
資料測試方式: 使用網路上公開的挪威門薩(Mensa Norway)智力測驗題目,直接將圖片餵給 AI(Multimodal 輸入)。
資料代表意義: 這是最基礎的基準線。
CyberQ 解讀: 因為題目公開已久,許多模型的訓練資料集(Training Data)可能早就看過這些圖了。
資料資料分數虛高風險:極高。 如果這個分數很高,但 Offline 分數很低,代表 AI 只是在「背答案」。
2、Mensa Norway (Text) ,考驗「純邏輯+記憶」的盲測
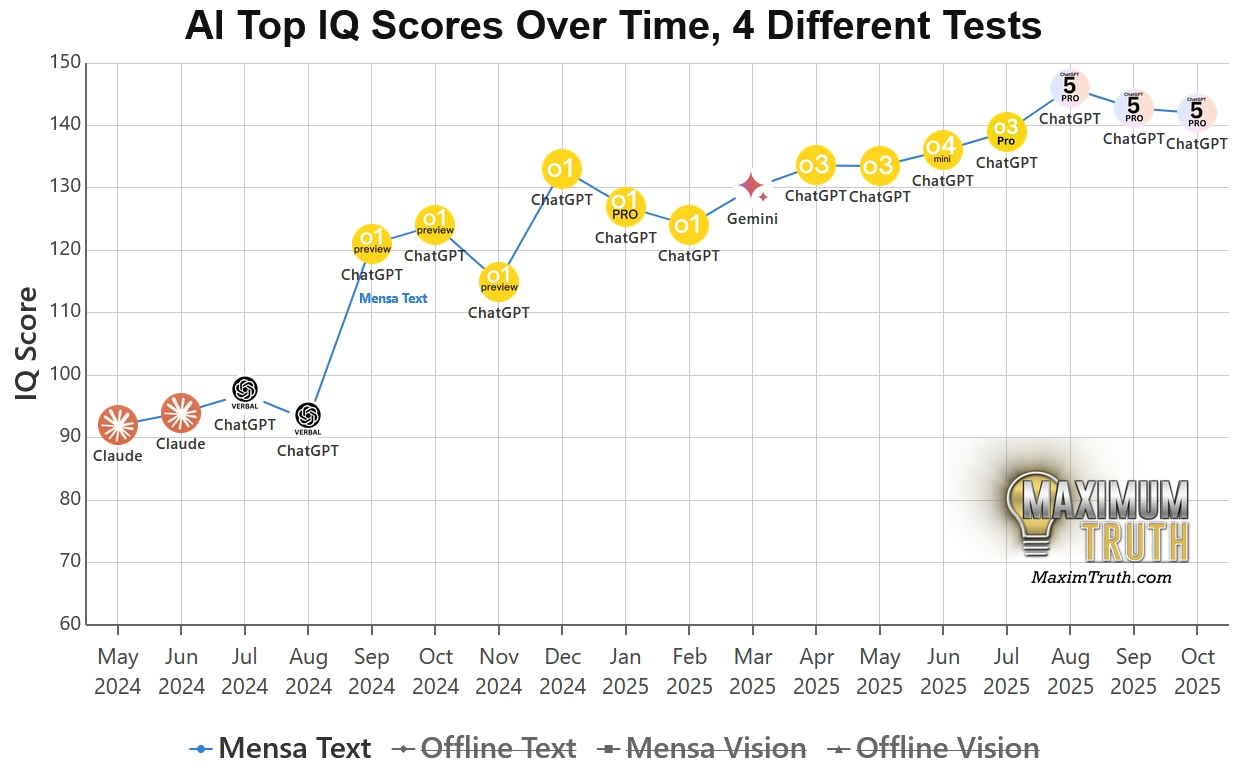
資料測試方式: 同樣是公開的門薩題目,但不給 AI 看圖片,而是將圖片中的規律轉化為純文字描述(例如:「3×3 的格子,第一行是圓形變三角形…」)讓 AI 去解。
資料代表意義: 剝離了「視覺辨識」的變因,單純測試 AI 的邏輯推理核心。
CyberQ 解讀: 如果 Text 分數 >> Image 分數:代表這個 AI 很聰明,但「眼睛(Vision Encoder)」不好,看不懂圖片裡的細節。
資料資料如果 Text 分數 << Image 分數:這很不合理,通常暗示 AI 是靠識別圖像的像素特徵來「作弊」或死記硬背,而非真的理解邏輯。
3、Offline Test (Image) ,考驗「真實視覺推理」的照妖鏡
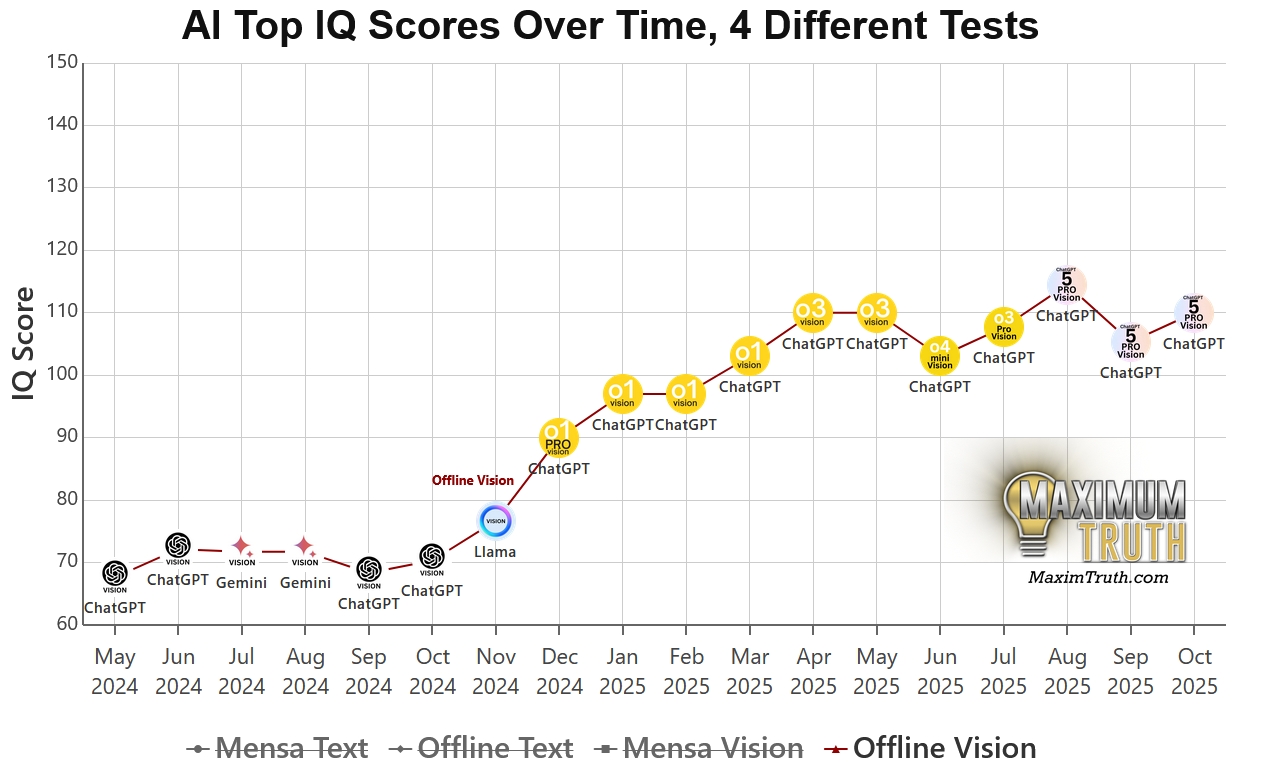
資料測試方式: 使用由專家設計、從未在網路上公開的全新圖形推理題,直接給 AI 看圖片。
資料代表意義: 這才是真正的實力。 因為沒有標準答案可以背,AI 必須現場觀察、現場推理。
CyberQ 解讀: 這是目前業界公認含金量最高的指標。Gemini 3 Pro 之所以被大家熱門討論和採用,就是因為它在這個項目拿了高分。
這部分的成績呈現,這代表 AI 具備了類似人類的「流體智力(Fluid Intelligence)」。
4、Offline Test (Text) ,考驗「真實純邏輯」的極限挑戰
資料測試方式: 使用未公開的全新題目,並轉化為純文字描述給 AI。
資料代表意義: 測試 AI 在面對完全未知問題時的純文字邏輯推演能力。
CyberQ 解讀: 這是給那些「視覺能力較弱」但「推理能力強」的模型(如早期的 GPT-4)平反的機會。
這份測試同時也能檢測出那些只擅長處理視覺模式,但語言理解能力較弱的模型。
實測呈現驚喜與懷疑並存
CyberQ 觀察了 Reddit r/singularity 與 r/LocalLLaMA 等社群對這份榜單的最新反應,歸納出幾個有趣的實測觀點:
1、對「未見資料」的極度渴望
社群們對於 Gemini 3 Pro 在離線測試奪冠的反應多半是:「這才是我們想看的!」(”The performance on unseen data is the real surprise.”)。社群厭倦了那些在標準跑分榜(Benchmarks)上刷榜、實際使用卻翻車的模型。Gemini 3 Pro 的表現被視為 AI 具備真正「泛化推理能力」的訊號,而不僅僅是高階的文字接龍。
2、DeepSeek 的波動引發討論
來自中國的 DeepSeek V3 在榜單上的表現也引發討論。有網友發現其成績波動劇烈(Overtime difference),這在技術論壇上引發了關於「模型穩定性」與「量化蒸餾(Quantization/Distillation)後遺症」的討論。其實越來越多人留意到,AI 的 IQ 高不代表回答每一次都穩,這也是目前 AI 落地應用的一大問題。
3.、「AI IQ 無用論」的反撲
當然,反對聲音從未缺席。部分開發者指出,IQ 測試高度依賴視覺模式識別(Pattern Recognition)與幾何邏輯,這對擅長程式碼與語言理解的 LLM 來說,可能是用錯工具。有網友犀利評論:「這就像是在考愛因斯坦投籃準不準。」(”Like testing Einstein on his jump shot.”),換言之,IQ 榜單雖具參考價值,但絕非評估 AI 實用性的唯一真理。以最新的幾個程式開發強大 AI 模型來說,它們擅長的是程式開發,但可能在這個 IQ 測試排名會不夠前面。
從超強記憶力的接話達人逐步升級為思考者
TrackingAI 的這份榜單,最大的價值不在於排名,而在於我們可以好好地重新看待 AI 在 「記憶」與「推理」的邊界。
如果一個 AI 只能解決它「看過」的問題,以及努力接話你給它的文本,那它充其量是一個超強的搜尋引擎。但當 Gemini 3 Pro 在未知題目上拿下 130 分時,xAI Grok 4 也拿到 IQ 126 分暫居第二名,我們或許正見證著 AI 從接話強者 + 檢索整理資料者,走向思考者跨越的關鍵時刻。
對於企業與開發者來說,CyberQ 建議別再迷信那些公開的 Benchmark 分數了。 在評估模型時,請務必使用內部的、未公開的私有資料進行測試(Private Evaluation Set),唯有在「未知」面前,才能看見智慧的真容。
首圖由 Google Gemini AI 生成