全球網路基礎設施要角 Cloudflare 於今日(11 月 18 日)稍早傳出服務異常,導致包括社群平台 X(前 Twitter)、ChatGPT、PTT、Letterboxd 在內的眾多依賴其 CDN 與安全服務的全球大量網站無法存取。這是繼今年包括 AWS 美東機房當機等數次大型事故後,又一次衝擊全球網路連線的重大事件。危機解除後,官方也很負責任地發表了這次事件的調查報告,坦承是該公司 2019 年以來的最嚴重事故。
CyberQ 額外更新:歷經了數個小時的動盪,Cloudflare 的服務終於在台灣時間晚間 10 點 42 分宣佈恢復正常,剩下零星問題在處理中,包括管理後台等等。
[22:42] Cloudflare 官方宣佈:事故已解決 (Resolved),進入監控階段 Cloudflare 正式更新狀態為「監控中 (Monitoring)」。官方表示,修復方案已全面實施,並認定本次事故現已解決 (The incident is now resolved)。目前技術團隊將持續監控系統運作情形,以確保所有服務均已完全回歸正常狀態,不再出現錯誤。
[22:34] 儀表板 (Dashboard) 服務已恢復 這算是本次事件的重大進展,Cloudflare 表示已部署了一項變更 (Deployed a change),成功修復並恢復了 Dashboard (控制台/儀表板) 的運作。不過官方也強調,目前仍持續針對影響範圍較廣的「應用服務 (Application Services)」層面進行搶修,這意味著終端用戶訪問網站可能仍不穩定,但管理員已可登入後台。
下方有 CyberQ 針對此事件的詳細報導內容 :

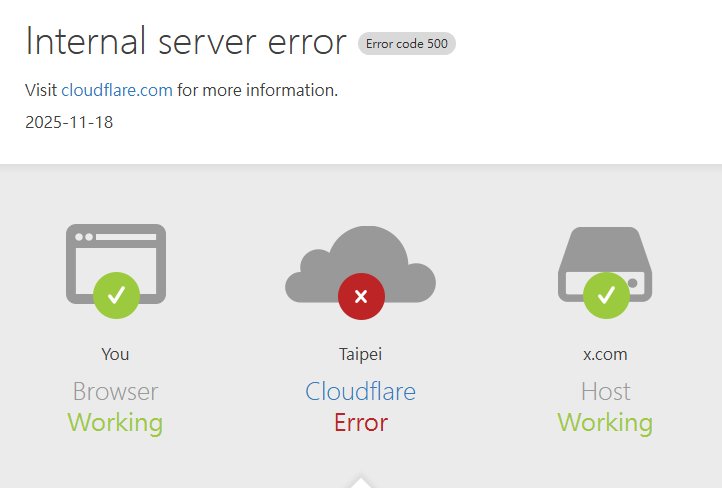
圖說: ChatGPT 不是罷工,是連線要讀取 Cloudflare 的安全性驗證服務 challenges.cloudflare.com時,當系統 api 異常和服務不能用時,ChatGPT 網站只好回應這個畫面出來。
災情現況:500 Internal Server Error 頻傳
根據全球監測網站 DownDetector 的資料顯示,自 11 月 18 日今日白天開始,針對 Cloudflare 及 ChatGPT、X 的錯誤回報數量呈垂直式飆升。全球各地大量使用者(包含台灣用戶)在嘗試連線至受影響網站時,普遍遭遇到以下狀況:

連線逾時 (Timeout)
頁面顯示「500 Internal Server Error」
看到 Cloudflare 的品牌錯誤頁面,提示「Web server is down」或「Connection timed out」
CyberQ 有數個客戶在連線使用 Cloudflare 管理 DNS 和 CDN 時,後台甚至無法正確顯示資訊和使用,不時還出現 404 錯誤頁面在後台中,而 Cloudflare 官方仍在修復中。甚至有客戶反映,連 Dashboard API 介面也失效,管理者想登入後台改設定也沒辦法。

由於 Cloudflare 作為全球網路流量的守門員,其服務範圍涵蓋了內容傳遞網路 (CDN)、DDoS 防護及 DNS 解析。一旦其核心節點或 API 發生故障,影響範圍往往是重大且顯著,這也解釋了為何許多看似無關的網站會同時斷線。
CloudFlare 官方狀態與回應:[22:42] 官方宣佈:事故已解決 (Resolved)
截至撰稿時間,CloudFlare 官方已經給出了 11/08 網路連線異常公告 「Cloudflare Global Network experiencing issues」。
我們查閱了 Cloudflare Status 頁面,發現今日(11 月 18 日)在多個節點(包括洛杉磯 LAX、邁阿密 MIA、亞特蘭大 ATL 等)確實排定有 「已排程的維護 (Scheduled Maintenance)」。
然而,目前的災情規模似乎遠超出了單純「節點維護」通常會造成的延遲或路由重導 (Re-routing) 影響。
官方最新回應: 根據外媒報導與最新的官方更新,Cloudflare 已確認意識到問題,並表示:「Cloudflare 已知悉並正在調查一個可能影響多個客戶的問題。 (Cloudflare is aware of, and investigating an issue which potentially impacts multiple customers.)」
以下是我們整理的 Cloudflare 這次事件的時序與分析 :
Cloudflare 全球網路異常事件更新日誌 (Timeline)
[11/19 03:28] 事故正式結案 (Resolved) Cloudflare 官方正式宣告,本次大規模網路異常事故已解決。
[11/19 01:44] 警報解除,可安全重啟服務 Cloudflare 確認目前所有服務運作正常,全網監測已不再出現異常的錯誤率或延遲。
- 重要指示: 雖然工程團隊仍在密切監控平台並對稍早的中斷進行更深入的調查,但目前階段不會再進行任何配置變更。
- 行動建議: 官方表示,此刻已被視為安全狀態,企業用戶可以放心地重新啟用 (Safe to re-enable) 在事故期間暫時關閉或繞過的任何 Cloudflare 服務(如 WAF 規則、負載平衡設定等)。調查結束後將提供最終更新。
[11/19 01:14] 數據回歸正常水平,將發布檢討報告 系統透過復原程序的持續監控顯示,錯誤率與延遲皆已回到正常水平。官方承諾將盡快提供完整的事故檢討與細節報告 (Post-incident investigation)。
[11/19 00:46] 全球節點逐步「掃雷」 隨著技術團隊在全球各個服務節點推進修復工作,並清除剩餘的錯誤與延遲堆積,整體的錯誤率正持續下降中。
[11/19 00:27] 尋求加速全面復原 雖然整體數據持續改善,但仍有間歇性的錯誤回報。團隊正密切監控局勢,並尋求能加速達成「全面復原」的方法。
[11/19 00:04] Bot Management (機器人防護) 評分波動 請注意,在全球復原的過程中,Bot Scores (機器人評分機制) 將會受到間歇性的影響。這意味著依賴 Bot Fight Mode 或 WAF 評分的網站可能會出現誤判或漏判。官方將在確認該功能完全恢復後另行更新。
[11/18 23:40] 處理修復後的殘留問題 團隊目前的重心已轉向修復後的服務重建 (Restoring service post-fix)。目前正在積極緩解 (Mitigating) 幾個在部署修復方案後仍殘留的異常問題。
[11/18 23:23] 持續監控 團隊持續監控是否有任何衍生問題。
[22:57] 部分用戶儀表板仍有異常,官方修正中 儘管稍早宣佈事故解決,Cloudflare 最新更新指出,仍有部分客戶在登入或使用 Cloudflare Dashboard (控制台) 時遭遇困難。技術團隊正在進行修復作業,並持續監控是否還有其他衍生問題。
[22:42] 官方宣佈:事故已解決 (Resolved),進入監控階段 Cloudflare 正式更新狀態為「監控中 (Monitoring)」。官方表示,修復方案已全面實施,並認定本次事故現已解決 (The incident is now resolved)。目前技術團隊將持續監控系統運作情形,以確保所有服務均已完全回歸正常狀態,不再出現錯誤。
[22:34] 儀表板 (Dashboard) 服務已恢復 這算是本次事件的重大進展,Cloudflare 表示已部署了一項變更 (Deployed a change),成功修復並恢復了 Dashboard (控制台/儀表板) 的運作。不過官方也強調,目前仍持續針對影響範圍較廣的「應用服務 (Application Services)」層面進行搶修,這意味著終端用戶訪問網站可能仍不穩定,但管理員已可登入後台。
[22:22] 持續修復中 技術團隊正持續致力於開發與部署針對此問題的修復方案。
[21:58] 持續修復應用服務層 官方再次更新狀態,目前的搶修重點仍集中在恢復「應用服務 (Application Services)」客戶的服務運作。
CyberQ 認為,Cloudflare 特別點出 「Application Services (應用服務)」,換言之,雖然部分網路層面已恢復,但負責處理 HTTP 請求、快取 (Caching) 與防火牆規則 (WAF) 的核心層可能仍有延遲或錯誤。如果你目前管理的網站目前仍偶爾出現 502/500 錯誤,均屬於此範疇,要耐心等待該層級的修復完成。
[21:35] 專注於應用服務修復 繼稍早 WARP 與 Access 恢復後,目前的作業進度顯示,團隊正持續致力於讓「應用服務 (Application Services)」恢復正常。
[21:13] Access 與 WARP 服務已恢復,倫敦節點重啟 官方宣佈實施的變更已生效,Cloudflare Access 與 WARP 服務已成功復原。目前的錯誤率監測顯示,上述兩項服務已回降至事故前的正常水平。此外,先前因修復作業而暫時關閉的倫敦地區 WARP 存取權限也已重新啟用。技術團隊目前正全力將焦點轉向恢復「其他受影響的服務」。
[21:09] 故障根源已確認 (Identified) 重大進展!Cloudflare 宣布已定位出導致本次大規模異常的問題根源,目前正在導入修復方案 (Fix is being implemented)。
[21:04] 倫敦地區 WARP 服務暫時手動關閉 作為緊急修復措施 (Remediation) 的一部分,官方暫時停用了倫敦節點的 WARP 存取功能。位於該地區的用戶若嘗試透過 WARP 連網,將會遭遇連線失敗。
[20:53] 官方持續調查中 Cloudflare 表示仍在針對此問題進行持續調查,目前尚未完全排除故障。
[20:21] 服務部分恢復,但錯誤率仍高 官方監測到服務已開始出現恢復跡象,但提醒用戶在技術團隊持續進行修復作業 (Remediation efforts) 的同時,客戶端仍可能觀察到「高於正常水平」的錯誤率 (Error rates)。
[20:03] 持續調查 技術團隊正持續調查問題根源。
[19:48] 官方首度確認:內部服務效能降級 Cloudflare 正式將狀態更改為「調查中」,並確認正面臨「內部服務效能降級 (Internal service degradation)」。官方指出部分服務可能會受到間歇性影響 (Intermittently impacted),目前首要目標是恢復服務運作。

圖說 : Cloudflare 狀態頁顯示維護中,但不少用戶端連線的網站服務已全面斷線
狀態頁面時間差須留意
值得 IT 與資安人員注意的是,各家與設備狀態頁面的更新往往有滯後性 (Lag)。在事故發生初期,即便用戶端已無法連線,狀態燈號可能仍顯示為綠色或僅標示為維護中。建議 IT 管理員應以實際監控數據 (Synthetic Monitoring) 為準。
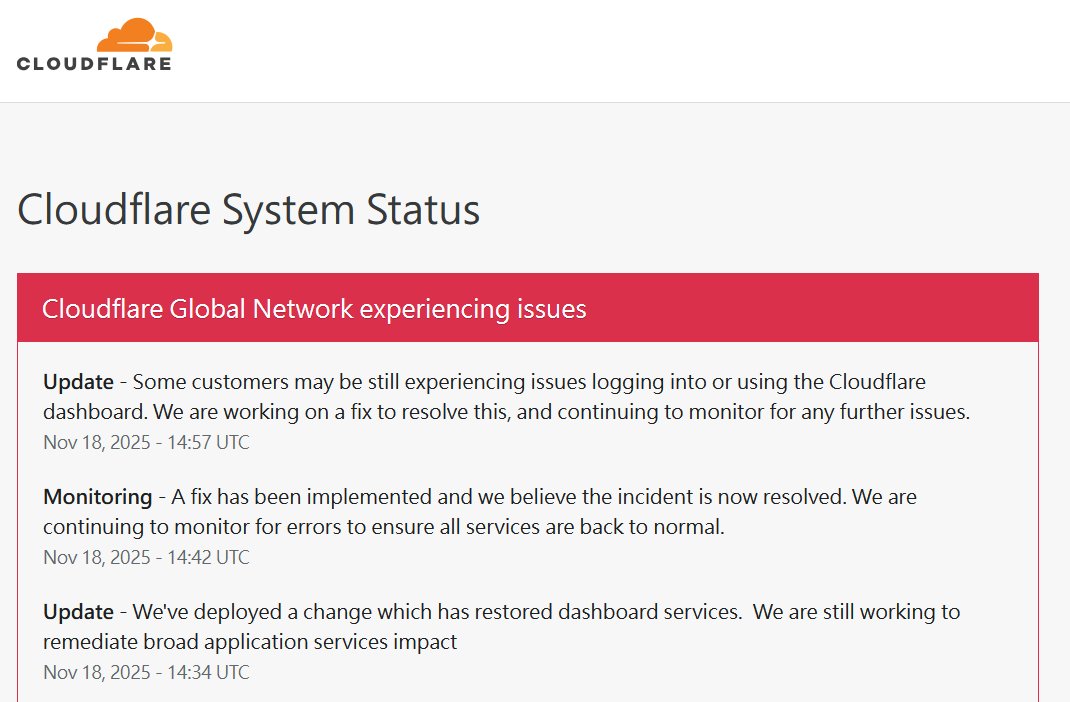
Cloudflare 狀態頁持續滾動式更新內容,並宣布於Nov 18, 2025 – 14:42 UTC,台北時間 22:42 解決事件,後續監控與繼續處理中。
今年屢傳災情,企業該如何應對?
CyberQ 回顧 2025 年,除了類似上次 AWS 重大事故導致全球許多重要服務停擺和調整外,身為全球網路基礎重要環節的 Cloudflare 穩定性備受考驗。從 2025 年 6 月涉及多個核心服務(Workers KV, WARP 等)的中斷,到 8 月與 9 月的 API 及儀表板故障,本次事件再次凸顯了「集中化風險」的問題。當單一供應商掌握了過大比例的網路流量基礎設施,其單點故障 (SPOF) 的代價便極為高昂。
針對本次事件,CyberQ 給予企業與 IT 管理人員的建議:
暫勿直接更動設定: 若網站在 Cloudflare 後方且無法連線,請勿在此時急著更改 DNS 指向或防火牆規則,或者是把 CDN 關掉的緩解法,因為少掉 Cloudflare 這一層的代理可能讓你的伺服器 IP 直接對外,除非確保你的網路防火牆、負載平衡 LB 都做得很好。畢竟,這通常是上游供應商如 Cloudflare 的問題,沒有想清楚就更改設定,可能在服務恢復後導致二次故障。
關注官方管道,請定期或不定期持續重讀整理 Cloudflare Status 頁面,或訂閱相關事件的 Incident 郵件通知、RSS資訊等等。
啟用備援頁面 (若有): 若架構允許(例如有非 Cloudflare 的備援線路或單純的靜態維修頁面),可考慮暫時切換以安撫用戶,但在 DNS 或 CDN 層級故障時,這通常很難實現。
多重 CDN 策略 (Multi-CDN): 對於高可用性要求極高的企業,此次事件再次證明了評估多重 CDN 架構的必要性,雖然成本較高且管理複雜,但能有效分散風險。
值得注意的是,雖然官方在 20:21 提到「服務恢復」,但隨後又連續兩次更新「持續調查中」,這在維運上通常代表修復措施尚未完全生效,或者進入了「震盪期 (Flapping)」,建議企業用戶現階段仍需保持警戒,切勿過早認定危機解除。

CyberQ 觀察,Cloudflare 今天稍晚時,對外公布優先修復並宣布恢復的是 Cloudflare Access (零信任身分驗證) 和 WARP (網路通道)。
至於該公司在倫敦節點的異常操作,官方特別提到「在倫敦手動關閉 WARP」才讓狀況緩解。這通常暗示某個壞掉的配置 (Bad Configuration) 或路由問題是透過這些連線服務擴散的,必須切斷它才能正常。
根據 Cloudflare 官方後續的 RCA,本次事故的根因並非網路路由或底層通道的中斷,而是某項資料庫權限變更造成 ClickHouse 回傳異常數據,進而生成遠大於預期的機器學習特徵(feature)檔案。
當這個錯誤的檔案被部署到全球節點後,Cloudflare 的 proxy 程式在載入過大檔案時觸發 Rust 的 runtime panic,導致大量 HTTP 請求處理程序(workers)崩潰,因此造成 500/502 等錯誤暴增。也就是說,本次事件的核心是「程式 panic 與 worker crash」,並非網路層或身份驗證層的通道斷線。
後續觀察: 雖然官方宣佈解決,但根據經驗,全球各地的節點快取 (Cache) 和路由傳播 (BGP propagation) 可能仍需一點時間完全同步。若自己管理維運的網站仍有零星錯誤,請再觀察 15-30 分鐘。
Cloudflare 官方已經在後續釋出相關的事故檢討報告 (RCA, Root Cause Analysis),CyberQ 做了這篇分析 Cloudflare 11/18 全球大當機官方調查報告出爐,結果權限變更反而比 DDoS 更致命
(本文內容依據 2025/11/18 Cloudflare 之公開資訊與 CyberQ 海內外客戶第一手即時資訊整理)
本文圖片由 ComfyUI 搭配本地端 AI 模型生成