

是的,CyberQ 直接告訴你結論,AWS 官方文件時序看起來總共花費了約 15 個小時恢復所有該平台服務正常,我們確實需要多雲端服務架構 multi-cloud,不能只依賴市場上最穩定的 AWS,因為它也有可能會掛掉,平常要準備有第二套方案因應,備援至少要恢復到某個程度才能應對全球客戶。
當雲端停止呼吸:AWS大當機揭示的驚人真相
你是否曾有過這樣的經驗:早晨醒來,想問 Google Gemini AI 或 蘋果 Siri 、Alexa 這些服務關於今天天氣,卻只得到一片寂靜?或是打開最愛的 Youtube 或 Spotify 串流影音,卻怎麼也無法載入?這不再是科幻情節,而是真實發生在數百萬人身上的「雲端停止呼吸」時刻。
就在 2025 年 10 月 20 日台北時間的下午,美國雲端服務大廠亞馬遜旗下的 AWS(Amazon Web Services)雲端服務爆發了大規模中斷。此次事件的中心是其關鍵的「US-EAST-1」(美國東部)區域,但影響迅速擴散至全球。這場數位世界的「停電」,不僅讓亞馬遜自家的線上服務癱瘓,更導致了 Paypal 的 Venmo 行動支付、社群軟體 Snapchat、AI 搜尋引擎 Perplexity,甚至麥當勞的應用程式和美聯社(AP)的後台都瞬間停擺,迫使美聯社緊急啟用備援網站。另外還有 EA、Epic、Ubisoft 等公司也受到影響,蘋果則是 iCloud 的部分受影響,一堆科技公司的網站、APP、軟體服務有用到 AWS 的都受到不同程度的影響。
根據 AWS 官方當時的說明,他們持續去修復 US-EAST-1 的 EC2 服務,並且努力恢復包括 RDS 、ECS 與 Glue 等服務,這些包括了虛擬機、資料庫等等,要等服務完全恢復,各家科技大廠執行在 AWS 許多相關伺服器服務才有辦法恢復運作。
根據 CyberQ 在美國的合作夥伴訊息與目前客戶上碰到的 AWS 雲端問題,簡單綜合歸納如下 :
事件總結:網路「電話簿」故障引發的連鎖效應
簡單來說,這次 AWS 大規模當機的根本原因,是核心的「DNS 服務」出了問題。
用另一個視角來看,暫時權稱把 DNS 想像成是網路世界的「電話簿」。當全球訪客要造訪一個網站(或一項服務)時,電腦會先去查這本電話簿,找到該網站的「地址」(IP 位址)。
這次事件中,AWS 內部這本「電話簿」壞掉了,導致它自己內部的許多服務找不到彼此的「地址」。
起火點: 最先出問題的是 DynamoDB,這是一個超大型的「雲端資料庫」(想像成一個巨型數位檔案櫃)。
連鎖效應: 因為「電話簿」查不到 DynamoDB 的地址,導致其他數十個依賴這個「檔案櫃」的服務(例如:身份驗證、虛擬主機、資料處理服務等)全部跟著大亂。
殘餘問題: 即使「電話簿」修好了,但先前中斷引發了「後遺症」,例如:
EC2(虛擬主機): 用戶無法順利「開啟新的雲端電腦」。
Lambda/SQS(自動化任務): 就像「郵局的信件 (SQS)」堆積如山,而「郵差 (Lambda)」來不及處理這些積壓的信件。
事件時序整理 (PDT 時間)
以下是從問題發生到修復的關鍵時間點:
階段一:偵測到問題
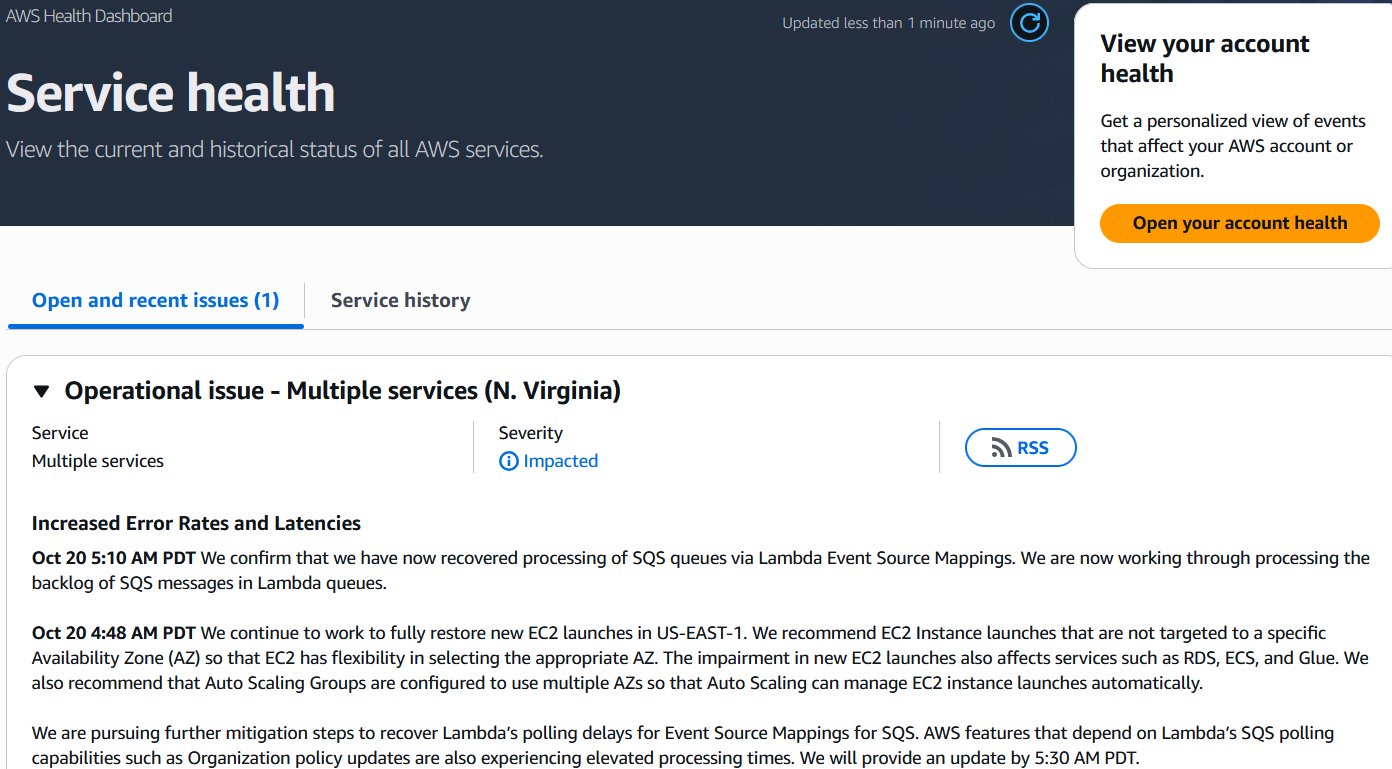
[12:11 AM] AWS 工程師開始調查美東(N. Virginia)機房的服務出現「大量錯誤和延遲」。
[01:26 AM] 官方確認,DynamoDB (雲端資料庫) 服務出現「嚴重錯誤率」。這時連 AWS 自己的「客服支援系統」也跟著掛點了。
階段二:找到根本原因並開始修復
[02:01 AM] AWS 鎖定了潛在的根本原因:DNS 解析問題。
[02:01 AM] 官方證實,這個 DNS 問題也影響到「全球服務」(例如 IAM 身份登入管理),因為它們都依賴美東機房的端點。
[02:22 AM] 團隊開始實施修復 DNS,並觀察到「早期恢復跡象」。
[02:27 AM] 服務出現「顯著的恢復跡象」,大部分請求開始恢復成功。
階段三:主要問題解決,但出現「後遺症」
[03:35 AM] 核心的 DNS 問題已完全緩解。大部分服務恢復正常。
03:35 AM 雖然 DNS 修好了,但中斷引發了「後遺症」:
EC2 (虛擬主機): 使用者在「啟動新的虛擬主機」時開始遇到錯誤(顯示「容量不足」)。
Lambda (自動化任務): 仍在處理先前堆積如山的「積壓事件」。
05:48 AM 虛擬主機與日誌問題改善
虛擬主機 (EC2): 啟動問題取得進展。在美東機房的某些「獨立建築」(AZ) 已經可以成功啟動新主機了,團隊正在將修復方案應用到剩下的區域。客戶會漸漸看到越來越多主機能成功開啟。
日誌/事件 (CloudTrail, EventBridge): 先前卡住的「日誌」和「事件」積壓也正在成功消化中。新產生的日誌已恢復正常傳遞,不再有延遲。
[06:42 AM] EC2 啟動錯誤仍然很高。AWS 開始「限流」(Rate Limiting),主動限制新主機的啟動數量以協助恢復。
第二波衝擊 – 網路連線大亂 (7:14 AM – 10:03 AM)
07:14 AM 系統爆發「嚴重的 API 錯誤和連線問題」。這是一個新問題。
[08:04 AM] 問題源頭指向「EC2 內部網路」。
08:43 AM 真正的元兇是「網路負載平衡器 (NLB) 的健康監控子系統」。
白話文: 「交通號誌監控系統」故障,導致網路癱瘓。
[09:13 AM] 團隊開始修復 NLB 監控系統。
[10:03 AM] 官方確認,故障的 NLB 系統也導致了 Lambda (自動任務) 大量失敗。
系統穩定與逐步恢復 (10:38 AM – 2:48 PM)
[10:38 AM] EC2 (第一波衝擊) 的修復工作取得進展,在少數 AZ 開始恢復。
[11:22 AM] EC2 啟動和網路連線問題「顯著改善」。Lambda 錯誤也大幅改善。
[12:15 PM] Lambda 在存取其他服務時仍有網路錯誤。AWS 刻意減慢 SQS (信件處理) 速度,以降低 Lambda 的壓力。
[01:03 PM] 情況持續好轉。AWS 開始「減少限流」(Reduce throttles) EC2 啟動。SQS 的處理速度也調回正常。
[01:52 PM] Lambda 積壓的事件預計 2 小時內處理完畢。
[02:48 PM] EC2 (第一波衝擊) 問題解決。 主機啟動的「限流」已恢復到事件前的水準。依賴 EC2 的服務 (如 Redshift) 開始消化積壓。
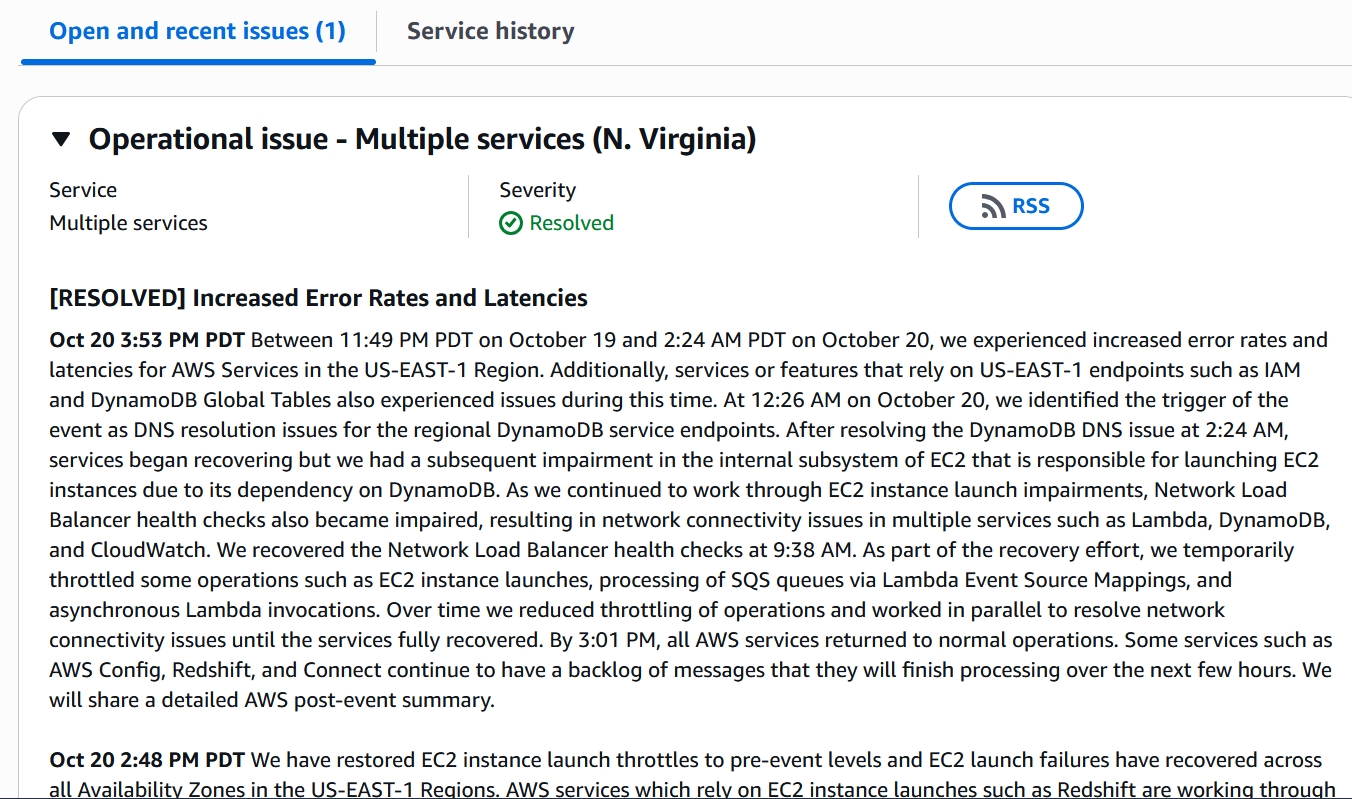
[已解決] 官方最終總結 (3:53 PM)
AWS 在 3:01 PM 宣布所有服務恢復正常運作。
官方總結了這場連環災難:
事件 1 (DNS 故障): 10/19 11:49 PM – 10/20 2:24 AM。 (DynamoDB 故障)。
事件 2 (EC2 啟動故障): 2:24 AM 開始。 (修好 DNS 卻觸發了 EC2 虛擬主機啟動系統的潛在問題)。
事件 3 (NLB 故障): 9:38 AM 修復。 (在修復 EC2 期間,NLB 故障,導致 Lambda 和 DynamoDB 再次 出現網路問題)。
恢復行動: 官方承認在此期間使用了「限流」(Throttling) 手段來穩定系統。
殘餘工作: 雖然服務已恢復,但少數服務 (如 AWS Config, Redshift) 仍有一些積壓的訊息需要數小時才能完全處理完畢。
階段四:處理殘餘問題(後遺症)
[04:08 AM] 團隊仍在努力修復 EC2 (虛擬主機) 的啟動錯誤,並處理 Lambda 對 SQS (訊息隊列) 的 polling 延遲。
[04:48 AM] 官方建議,如果客戶需要啟動 EC2 主機,請「不要指定特定可用區 (AZ)」,讓系統自動幫你找健康的主機房。這也證實了 RDS (託管資料庫) 和 ECS (容器服務) 也因此受到影響。
[05:10 AM] Lambda/SQS 的處理功能已恢復。團隊開始努力消化先前「堵塞」的龐大訊息積壓。
受影響的服務範圍
這次事件波及範圍非常廣(總共一百多項服務受影響),因為 US-EAST-1 是 AWS 最古老且核心的區域:
已解決 (Resolved): 共 142 項。

核心問題:DynamoDB (資料庫)、IAM (身份登入)、Support (客服系統) 等。
衍生問題:EC2 (虛擬主機)、RDS (資料庫)、ECS/EKS (容器服務)、Lambda (無伺服器) 等。
日誌積壓:CloudTrail (操作日誌)。
以下是 AWS 近期關於服務恢復的最新陸續聲明 :
Operational issue – Multiple services (N. Virginia)
這場事故,再次揭示了我們對「雲端」的依賴程度遠超想像。它究竟教會了我們什麼?以下是幾個最令人警醒的真相。
一、你的智慧生活,其實是「亞馬遜 AWS 」智慧生活
從 Alexa 語音助理、掃地機器人到智慧門鈴,無數的智慧家庭裝置都悄悄地依賴著 AWS 運作。正如這次當機中有用戶通報,他們的 Alexa 瞬間關閉,無法回應查詢或執行例行鬧鐘。這場事故讓我們意識到,許多我們以為是獨立運作的智慧產品,其核心服務其實都集中在少數幾個雲端提供商手中。單一節點的故障,就能癱瘓我們數位化生活的一大部分。
二、遊戲、社群、串流影音,無一倖免
想像一下,當你正準備在《要塞英雄》(Fortnite)中與朋友並肩作戰,或是想上 Snapchat 分享生活點滴,卻發現一切都無法登入。此次受災的用戶名單中,就包括了 Snapchat、Canva 和 NVIDIA 舵手黃仁勳愛用的 Perplexity。
Perplexity AI的執行長更是在 X 平台發文證實:「根本原因是AWS的問題。」
換言之,無論是娛樂、社交還是資訊獲取(如美聯社的新聞後台),現代人的數位生活已與大型雲端服務深度綁定。我們享受著便利,卻也付出了將所有雞蛋放在同一個籃子裡的風險。
三、一個「自動化系統」的錯誤,引發骨牌效應
儘管 10 月 20 日這次當機的確切原因仍在調查中,AWS 僅表示在調查「錯誤率和延遲增加的問題」,但它突顯了高度自動化系統的脆弱性。過去的經驗(如2017年因技術人員「打錯字」導致的服務中斷),有時反而是「自動化系統」在檢測到錯誤後,觸發了更大的連鎖反應,導致服務全面癱瘓。這提醒我們,即使是最先進的自動化系統,也可能帶來毀滅性的後果,也引發了對 AI 和自動化系統設計的深層思考:我們如何確保其在故障時能「安全地失敗」?
四、企業的「雲端夢」與「雲端惡夢」
越來越多的企業將服務遷移到雲端,以享受其帶來的彈性、擴展性和成本效益。然而,這次當機也展示了雲端服務的脆弱面。許多公司,即使是擁有強大技術實力的企業,如美聯社和 Perplexity,也因為 AWS 的故障而需要啟動資安管理與 BCP 營運持續計畫中,提供資訊服務最重要的備援,要把網站用備援環境上線持續提供服務。
這次事件也讓我們反思,檢查自己公司和服務的雲端策略,思考如何建立更具韌性、分散式的架構,以避免將所有業務命脈寄託於單一供應商。

五、數位世界的「停電」
「這場當機不僅是技術問題,更是對現代數位基礎設施韌性的一次嚴峻考驗。」
CyberQ.tw
當電力中斷,我們知道該怎麼辦。但當「雲端」中斷,我們的應變能力又如何?這次事件就像一場 BCP 營運持續計畫的預演,讓我們看到了單一雲端供應商萬一變成單一失效點的潛在風險。
AWS的這次當機,我們可以思考,下一次當我們點擊一個應用程式,或是與智慧裝置互動時,或許會對其背後的巨大雲端基礎設施,有更深一層的理解與敬畏。
我們是否已經準備好,面對下一次的「雲端停止呼吸」呢?
本文圖片由 ComfyUi 搭配本地端 AI 模型生成








